Section 3.5. Unicode and UTF-8
3.5. Unicode and UTF-8Since the range of code numbers in Unicode is very large, it is useful to have different encodings for different purposes. Some encodings are technically very simple and efficient in terms of internal data processing but wasteful in storage space. Some other encodings aim at compactness, for efficiency in data storage and transfer. Before discussing the encodings, we will consider a general conceptual model, which is aimed at clarifying the different meanings and level of encoding character data. This discussion deals with Unicode encodings in general terms and in reference to options that you have, as a user, in choosing an encoding. The technical definitions of the encodings (i.e., how data is encoded in detail) are in Chapter 6. 3.5.1. The Conceptual Model: Levels of CodingIn the character context, "coding" or "encoding" of characters can mean different things, at different levels of abstraction. There are several ways to describe the situation, trying to make things clearer and unambiguous. In practice, approaches differ, so sometimes the clarifications end up confusing people. The differences are reflected in terminology. Thus, when reading about characters, you'll see not only unfamiliar words but also words that are familiar to you but have unexpected meanings. 3.5.1.1. The Internet (IAB) modelBefore considering the Unicode model, we consider the superficially simple model that is often called the Internet Architecture Board (IAB) model. It is described in a report of a meeting, published as RFC 2130 (http://www.rfc-editor.org/rfc/rfc2130.txt). It has three levels:
For example, ASCII and Unicode define Coded Character Sets. The Character Encoding Scheme for ASCII uses one octet for each character (and for each code number). For Unicode, there are several possible Character Encodings, such as UTF-8 and UTF-16. Transfer encoding syntax is something that may or may not be applied. It can consist of an operation that transforms a sequence of octets to another sequence, to be interpreted by different rules. The idea could be, for example, to make sure that all octets used are "safe" in the sense that they can be sent over a connection or a system that may not handle all octets properly. For example, the Base64 transfer encoding uses only a limited repertoire of octets, corresponding to a limited subset of ASCII values. Evidently, Transfer Encoding Syntax is logically different from the other levels. It is optional, not part of the basic model. The Unicode approach recognizes this, but it also adds two levels: the most abstract level where characters are defined as abstract objects only, without assigning code numbers to them, and an intermediate level, where characters exist ascode units . A code unit is neither a code number nor a sequence of octets, but at an intermediate abstraction level. The separation of code number from code unit is mostly relevant in Unicode only, but the model itself is of a general nature. 3.5.1.2. The four-level Unicode modelThe Unicode model on character encoding, defined in Unicode Technical Report (UTR) #17 at http://www.unicode.org/unicode/reports/tr17/, is summarized in Table 3-6. The last column shows illustrative examples of the way characters (here the Latin "A," in Unicode and UTF-32) could be represented at each level.
Thus, to represent the letter "A" in a computer, we logically start by identifying it as an abstract character, as a member of an Abstract Character Repertoire, such as the collection of all Unicode characters. At this level, a character may have a name assigned to it, but its internal representation is in no way fixed. At the next level, in a Coded Character Set, a code number is assigned to the character according to a character code. The notation U+0041 is, as we have learned, just a way of writing the number 41 (hexadecimal) in a manner that emphasizes its role as a Unicode code number. The code number as such is an abstract mathematical integer. Next, the code number is mapped to a sequence of code units according to some Character Encoding Form. The size of code units may vary across encodings (7, 8, 16, and 32 bits are typical sizes), but the size is fixed for any particular encoding form. At this level, all characters are of equal size. For Unicode, starting from Version 4.0, the encoding forms are UTF-8, UTF-16, and UTF-32, where the number indicates the number of bits in a code unit. This is sometimes expressed by saying that Unicode is variably an 8-, 16-, or 32-bit code, although it is very easy to misunderstand that. Using UTF-32, for example, U+0041 would map to a 32-bit integer, which we here express as 00000041, to be interpreted in hexadecimal. The fourth level, Character Encoding Scheme, maps code units to strings of octets. If the encoding form is UTF-32, for example, the encoding scheme maps a 32-bit value to a sequence of four 8-bit values, of octets. This is not a trivial operation, since the order of octets may vary. This reflects different machine architectures, namely different mutual order of octets in a two- or four-octet entity. A 32-bit integer that logically consists of octets o1, o2, o3, and o4, from most significant to least significant, can be physically represented in the order o1o2o3o4 or in the order o4o3o2o1. To use the usual jargon, "byte order" can be "big endian" versus "little endian." The mapping of code units to octet strings is often calledserialization . In practice, Character Encoding Form and Character Encoding Scheme are often not distinguished from each other. A term such as "UTF-16" may refer to a Character Encoding Form only, but it may also refer to a specific Character Encoding Scheme, where the byte order has been fixed. A mapping of character strings (sequences of abstract characters) to sequences of octets is called a Character Map, or "charmap" for short, in UTR #17. This somewhat odd term thus refers to a mapping that goes from the topmost level, Abstract Character Repertoire, to the bottom level, Character Encoding Scheme. That is, when using this term, we are not interested in what happens at the intermediate level. A Character Map usually bears the name of a Character Encoding Scheme that determines the mapping in practice. We can more or less identify "Character Map" with "charset" or "character encoding" as understood by nontechnical people. When you select character encoding upon saving a file (e.g., in a Save As dialog), you inevitably fix the representation down to the Character Encoding Scheme. 3.5.1.3. Transfer Encoding SyntaxIn the Unicode view, as mentioned earlier in this chapter, the Transfer Encoding Syntax (TES) is not part of the basic model of character coding. Instead, it is an optional auxiliary transformation. The most common forms of TES are Base64, uuencode (originally developed for Unix), BinHex (developed for Mac), and Quoted Printable (QP). Transfer encoding helps if you need to send character data from a system to another through a third system that cannot handle 8-bit quantities properly. The third system could even be a mail server that operates on ASCII data only, assuming that every character fits in 7 bits. In some situations, even some ASCII characters might cause problems. In any case, you need a method for encoding octets in a format that can be sent in a safe manner and then restored to the original format by the receiving system. Thus, the purpose of a TES is to make the data, as an octet string, acceptable to applications and software that might fail to process the original octet string correctly. This especially means avoiding octets that are known or suspected to cause problems. When you send email on the Internet, for example, your email program may apply some TES on the outgoing mail. It may (and indeed should) be capable of interpreting any commonly used TES in incoming data. Normally this happens without your knowing. If you are curious, you may view the "raw message source" with some special command (e.g., via File MIME-Version: 1.0 Content-Type: text/plain; charset="iso-8859-1" Content-Transfer-Encoding: quoted-printable Here, the encoding is iso-8859-1, which means that each character (in the ISO 8859-1 repertoire) is represented as one octet. However, the additional TES modifies this. The QP encoding converts the octet string so that the result contains only a limited repertoire of octets, corresponding to a subset of ASCII. If you view the "raw message source," you will see things such as =E4 where the data contains non-ASCII characters like ä. Although any TES is normally transparent to users, you may need to get involved in TES issues in email in some cases:
3.5.2. Encodings for UnicodeOriginally, before extending the code range past 16 bits, the "native" Unicode encoding was UCS-2, which presents each code number as two consecutive octets m and n so that the number equals 256 x m + n. This means, to express it in computer jargon, that the code number is presented as a 2-byte integer. According to the Unicode Consortium, the term UCS-2 should now be avoided, as it is associated with the 16-bit limitations. UTF-32 encodes each code position as a 32-bit binary integeri.e., as four octets. This is a very obvious and simple encoding. However, it is inefficient in terms of the number of octets needed. If we have normal English text or other text that contains ISO Latin 1 characters only, the length of the Unicode encoded octet sequence is four times the length of the string in ISO 8859-1 encoding. UTF-32 is rarely used, except perhaps in internal operations (since it is very simple for the purposes of string processing). UTF-16 represents each code position in the BMP (Basic Multilingual Plane) as two octets. Other code positions are presented using so-called surrogate pairs, using some code positions in the BMP reserved for the purpose. This, too, is a very simple encoding when the data contains BMP characters only. For the BMP, it is also efficient in processing in the sense that you can directly address the nth character of a string, since all characters occupy the same number of storage locations. UTF-8 is the most common encoding used for Unicode, especially on the Internet. Using it, code numbers less than 128 (effectively, the ASCII repertoire) are presented "as such," using one octet for each code (character). All other codes are presented, according to a relatively complicated method, so that one code (character) is presented as a sequence of two to six octets, each of which is in the range 128255. This means that in a sequence of octets, octets in the range 0127 (bytes with the most significant bit set to 0) directly represent ASCII characters, whereas octets in the range 128255 (bytes with the most significant bit set to 1) are to be interpreted as multiple-octet encoded presentations of characters. UTF-8 is efficient in terms of storage required, if the data consists predominantly of ASCII characters with just a few "special characters" in addition to them, and reasonably efficient for dominantly ISO Latin 1 text. The document "IETF Policy on Character Sets and Languages" (RFC 2277, BCP 18) clearly favors UTF-8. It specifies that new Internet protocols must support UTF-8; they may support other encodings as well. UTF-7 was designed to deal with situations where data cannot be safely transmitted using arbitrary 8-bit bytese.g., on connections that use the first bit of an octet for parity checks, passing just 7 bits through as actual data. In UTF-7, each character code is represented as a sequence of one or more octets in the range 0127 (bytes with most significant bit set to 0, or 7-bit bytes, hence the name). Most ASCII characters are presented as such, each as one octet, but for obvious reasons some octet values must be reserved for use as "escape" octets, specifying that the octet together with a certain number of subsequent octets forms a multioctet encoded presentation of one character. As you can see, the number in the names UTF-32, UTF-16, UTF-8, and UTF-7 indicates the size of the code unit in bits. Figure 3-6. Choice of encoding settings in BabelPad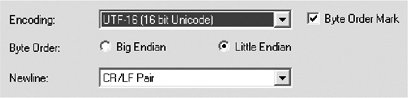 3.5.3. Saving as UnicodeMany programs let you save your data in different encodings. Even the Save As dialog in Notepad has some alternatives, such as "ANSI" (which means windows-1252), "Unicode" (which means UTF-16), "Unicode big-endian" (which means UTF-16 with swapped byte order), and "UTF-8" (which surprisingly means UTF-8). Advanced software that has been especially designed for multilingual applications typically contains explicit options for setting the encoding. Figure 3-6 illustrates this for BabelPad, the editor discussed in Chapter 1. You can choose UTF-8, UTF-16, or UTF-32 (as Character Encoding Scheme) from a drop-down menu, and then (when applicable) select the byte order. There is also a setting for the newline conventioni.e., which character or characters are used to indicate a line break (see Chapter 8); this is logically distinct from any encoding issues but often presented along with encoding for practical reasons. On the other hand, many text-processing and other application programs do not let you control the character encoding. They use their built-in settings for that, and might even use a data format of their own that contains information about the encoding. |
 Properties on Outlook Express). There you can see headers such as:
Properties on Outlook Express). There you can see headers such as: