Chapter 13. Browser Considerations with XML
| CONTENTS |
IN THIS CHAPTER
- Client-Side XML and Browser Support
- Client-Side JavaScript and XML
- Client-Side Transformations and XML
- Summary
The majority of XML processing in a Web application occurs on the server. One reason for this has to do with the fact that all developers know exactly what tools and configurations are available on the server. This permits greater control over the presentation of the content. They also know that those tools aren't going to change. As a result, server-side XML processing only has to be written in one way, for one configuration. This is unlike client-side XML processing, which includes code to verify access to the appropriate browser tools, and then XML processing code.
As a result, the option of client-side XML processing is often overlooked. The most common reason for this has to do with the wide variety of tools and implementations that exist across browsers and versions. Although this can be a strong factor in avoiding client-side processing, there are situations when these obstacles should be overcome and the client browser should be used to process XML.
This chapter will begin with a short discussion of the XML support in the two primary browsers, namely Microsoft Internet Explorer (IE) and Netscape. Next, we will walk through two options for client-side XML processing on both Netscape and IE. The first example uses DHTML and JavaScript to create an HTML table that displays the data contained within an XML document. The second example will also rely on JavaScript to demonstrate the repeated transformation of an XML document with different stylesheets completely on the client-side. The resulting reports provide various views of the same data that can be sorted.
Client-Side XML and Browser Support
The time has arrived when XML can be used successfully and predictably in Internet Explorer and Netscape. Although IE has provided XML support for some time now, Netscape has just recently been able to offer client-side XML and XSL support.
Netscape Gecko and Netscape 6 now include the open source Expat parser written by James Clark. He was the technical lead of the World Wide Web Consortium's (W3C) XML activity that developed the XML 1.0 recommendation. The result is that XML in Netscape is reliably parsed according to specification.
Although XML support is here, separate code must be written to take advantage of the client-side XML capabilities of both browsers due to differences in the API. In a perfect world, all browsers would have the same API, which would allow the same code to execute predictably and bug-free on all browsers.
With this in mind, there are times when client-side tools should be used. One such occasion is with systems where users typically look at many different reports generated on the same data. With many reporting systems, each time a report is sorted by the user, the server has to query the database for the same data and reconstruct the report. As a result, client-side XML processing can relieve the load on the database and Web server by reducing the number of requests, thus lowering the queries against the database.
A system that uses client-side XML processing must have the capability to control which browser versions are used. Although it is no longer necessary to only support IE, it is still necessary to require the more recent versions of Netscape.
The examples in this chapter depend upon the use of Netscape version 6.2 and Internet Explorer version 6.0. IE must also have MSXML2 4.0 installed.
Both examples also use the RStoXML.java class shown in Listing 11.4 of Chapter 11, "Using XML in Reporting Systems." This Java class converts a database ResultSet into a JDOM XML representation.
I chose not to demonstrate the use of client-side techniques that are dependent on a particular browser. One such technique is through the use of data islands, or IE-specific <XML> HTML elements.
Client-Side JavaScript and XML
The first example will use JavaScript on the client side to create an HTML table from an XML DOM. The DOM will also be created on the client from XML found inside an HTML DIV element.
The JSP begins with the output of HTML markup and JavaScript sent directly to the browser. Following that, the JSP queries the database for data. The results of the database query will then be processed into a JDOM representation and serialized to the client placed within a hidden HTML division. At this point, the client browser creates a DOM representation of the XML document found in the hidden DIV. JavaScript, combined with the data and structure of the XML, will be used to create the resulting HTML table.
The client browser will receive an HTML page that contains two divisions. The first division starts out empty and will be used to contain the resulting HTML table after it has been created. The second division is hidden, and contains the XML document resulting from the database query. The data and structure of the XML will be used to create the HTML table.
After the page is loaded, the JavaScript begins by creating a DOM representation of the XML document found in the second division. After the DOM is available, the script uses it to create the resulting HTML table. When this table has been completely built, it is displayed by appending it to the empty division.
Although this example processes the XML only once, it will demonstrate how to load an XML document in both Netscape and IE on the client side. Also, it shows the power and potential of scripting and client-side XML.
The JSP
The JSP code begins by importing the necessary packages and outputting some HTML. Contained in this HTML is the JavaScript that will perform the client-side processing.
The script begins with the sniff() function, which will set a variable indicating which browser it is executing in, as shown in the following example. The two variables are ie for Internet Explorer and ns for Netscape. The appropriate variable is set to true and is used to determine what code gets executed throughout the rest of the script:
function sniff() { if(window.ActiveXObject){ ie = true; } else if (document.implementation && document.implementation.createDocument){ ns = true; } Notice that both implementation and createDocument are detected for Netscape. The reason for this is that, at the time of writing, Netscape for the Mac contained the implementation object but did not support the createDocument() function.
Finally, the function invokes the loadXML() function only if one of the browsers has been detected successfully:
if(ns || ie) loadXML(); }
It is important to note that if the XML processing depends upon a particular version of the parser, that version should be detected to avoid client-side breakage. This can be done by creating the object in a try block and catching errors in the creation of the specific object in the catch block. In this way, you can determine whether or not the client has the necessary version installed. In this example for IE, we are not detecting the presence of a particular parser, but just that the browser is ActiveXObject-enabled.
Next, the function loadXML() begins by creating the DOM object for Netscape, as in the following code fragment. A new document element called xmlDoc is created through the use of the createDocument() function of the DOM level 2 specification. The three parameters of this function are the namespace URI, the qualified name of the root element, and the document type. These are left to empty strings and null because an XML document will be parsed into this object.
function loadXML(){ if (ns){ xmlDoc = document.implementation.createDocument("","",null); Following this, a new DOMParser, which will be used to parse the XML string, is created:
var domParser = new DOMParser();
Next, the XML string is obtained through the innerHTML property of the xmlData division in the following fragment. The string is then parsed into the xmlDoc by invoking the parseFromString() method of the domParser object. The status() function is then invoked to continue the processing:
var strXML = document.getElementById('xmlData').innerHTML; xmlDoc = domParser.parseFromString(strXML, 'text/xml'); status(); } That concludes the creation of the XML representation for Netscape. Next, the DOM is created for IE. This processing begins with the creation of a new MSXML2.DOMDocument object, as seen in the following fragment. Once created, the status function is set to handle the onreadystatechange events. These events will indicate when the parsing has completed and processing should continue.
else if (ie){ xmlDoc = new ActiveXObject('MSXML2.DOMDocument.4.0'); xmlDoc.onreadystatechange = status; Next, the xmlData division object is obtained, and its innerHTML used to load the xmlDoc as in the following fragment. When completed, xmlDoc will contain a DOM representation of the XML found within the xmlData division.
var xmlData = document.getElementById('xmlData'); xmlDoc.loadXML(xmlData.innerHTML); The following status() function is used primarily to handle IE timing and loading issues. If the DOM is used before it has completed loading, errors will ensue. One way around this problem is to associate a function to handle the onreadystatechange events, as was done in the previous example. In this way, DOM usage can be stopped until it has completed loading and its readyState is equal to 4, as shown here:
function status(){ if (ns){ createTable(); } else if (ie){ if (xmlDoc.readyState == 4){ Following this is the createTable() function, which invokes HTML DOM functions that are documented in the W3C DOM level 1 specification. The only part of this function that changes according to the browser is the case of the element name as shown here:
if (ns) tblRows = xmlDoc.getElementsByTagName('rec'); else if (ie){ tblRows = xmlDoc.getElementsByTagName('REC'); } Browser Buffering
When a browser receives an HTML document, it is processed and buffered. Slight processing differences exist between IE and Netscape. This is because both browsers process the division contents as HTML. IE will capitalize all tag names, while Netscape will convert all tag names to lowercase. (It is interesting to note that the XHTML specification from the W3C states that tag names should be completely in lowercase.) This inconsistency can be very difficult to track down, especially considering the source for both browsers doesn't display what is found in the buffer.
The createTable() function then creates the table column labels and iterates through the tblRows collection creating a new table row for each. Table cells are then added to each row containing the text node values. After the iteration is complete, the entire table is appended to the empty divResults.
The rest of the JSP consists of the code necessary to use the database and create an XML string from the results. The complete file is shown in Listing 13.1 and should be saved as webapps\xmlbook\chapter13\ClientScript.jsp. This JSP and the others in this chapter require the class RStoXML from Listing 11.4, and the presence of data in the database. Data was added to the database through the JSP in Listing 11.1.
Listing 13.1 ClientScript.jsp
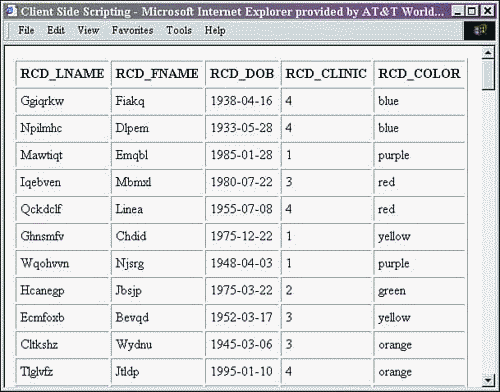
<%@page import = "java.sql.*, org.jdom.*, org.jdom.output.*, javax.xml.transform.*, xmlbook.chapter11.*" %> <html> <head><title>Client Side XML Scripting</title> <script language="JavaScript"> var xmlDoc; var ns = false; var ie = false; function sniff() { if(window.ActiveXObject){ ie = true; } else if (document.implementation && document.implementation.createDocument){ ns = true; } if(ns || ie) loadXML(); } function loadXML(){ if (ns){ xmlDoc = document.implementation.createDocument("","",null); var domParser = new DOMParser(); var strXML = document.getElementById('xmlData').innerHTML; xmlDoc = domParser.parseFromString(strXML, 'text/xml'); status(); } else if (ie){ xmlDoc = new ActiveXObject('MSXML2.DOMDocument.4.0'); xmlDoc.onreadystatechange = status; var xmlData = document.getElementById('xmlData'); xmlDoc.loadXML(xmlData.innerHTML); if (xmlDoc.parseError.errorCode != 0) alert("Parse Error!"); } } function status(){ if (ns){ createTable(); } else if (ie){ if (xmlDoc.readyState == 4) { createTable(); } } } function createTable(){ var tblRows; if (ns) tblRows = xmlDoc.getElementsByTagName('rec'); else if (ie){ tblRows = xmlDoc.getElementsByTagName('REC'); } var tblResult = document.createElement('TABLE'); tblResult.setAttribute('cellPadding',5); tblResult.setAttribute('border', 1); var tblTbody = document.createElement('TBODY'); tblResult.appendChild(tblTbody); var row = document.createElement('TR'); for (j=0;j<tblRows[0].childNodes.length;j++){ if (tblRows[0].childNodes[j].nodeType != 1) continue; var container = document.createElement('TH'); var theData = document.createTextNode (tblRows[0].childNodes[j].nodeName); container.appendChild(theData); row.appendChild(container); } tblTbody.appendChild(row); for (i=0;i<tblRows.length;i++){ var row = document.createElement('TR'); for (j=0;j<tblRows[i].childNodes.length;j++){ if (tblRows[i].childNodes[j].nodeType != 1) continue; var container = document.createElement('TD'); var theData = document.createTextNode (tblRows[i].childNodes[j].firstChild.nodeValue); container.appendChild(theData); row.appendChild(container); } tblTbody.appendChild(row); } document.getElementById('divResults').appendChild(tblResult); } </script> </head> <body onload="javascript:sniff();"> <div id="divResults" ></div> <div id="xmlData" style="visibility:hidden;" > <% String final_status = ""; String db_query = "select RCD_lname, RCD_fname, "; db_query +="DATE_FORMAT(RCD_dob, '%Y-%m-%d') as RCD_dob , "; db_query +="RCD_clinic, RCD_color from reportclientdata"; String db_location = "jdbc:mysql://localhost/xmlbook"; String db_driver = "org.gjt.mm.mysql.Driver"; Connection db_connection = null; Statement db_statement = null; ResultSet rs = null; try{ Class.forName(db_driver); db_connection = DriverManager.getConnection(db_location); db_statement = db_connection.createStatement(); rs = db_statement.executeQuery(db_query); } catch (ClassNotFoundException e){ final_status = "Error: Unable to create database drive class."; final_status += " <br />" + e.toString(); } catch(SQLException e){ final_status = "Error: Unable to make database connection"; final_status += "or execute statement."; final_status += " <br />" + e.toString(); } finally { /* We must close the database connection now */ try { if (db_connection != null) { db_connection.close(); } } catch (SQLException e) { final_status = "Error: Unable to close database connection."; final_status += " <br />" + e.toString(); } } try{ // create a resultsetbuilder to transform resultset to XML RStoXML rsxml = new RStoXML(rs, "ROOT", "REC"); org.jdom.Document jdomdoc = rsxml.build(); rs = null; rsxml = null; //create outputter to output results XMLOutputter output = new XMLOutputter(" ", true); output.output(jdomdoc, out); output = null; } catch (TransformerFactoryConfigurationError e) { final_status = "Error: Unable to create factory to transform "; final_status = "XSL and XML."; final_status += "<br />" + e.toString(); } catch (JDOMException e) { final_status = "Error: Unable to create XML from database query."; final_status += "<br />" + e.toString(); } if(final_status != "") out.print("<br><font color=\"red\"><H2>" + final_status + "</H2></font>"); %> </div> </body> </html> The results of the client-side processing can be seen in Figures 13.1 and 13.2. Note that the table labels aren't consistent across the two browsers. This is a result of the browsers processing the HTML before placing it in their buffers. It is this buffered content that was parsed into the XML DOM representation.
Figure 13.1. ClientScript.jsp in Netscape.
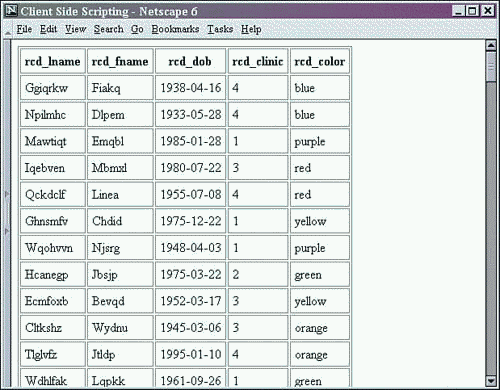
Figure 13.2. ClientScript.jsp in Internet Explorer.
With the use of DHTML and JavaScript, it is very simple to change the content of a Web page. It is also relatively simple to process XML in both IE and Netscape. Although the previous example only showed the XML being processed into a table once, it would be simple to repeatedly process the XML into different outputs using similar scripting techniques.
Client-Side Transformations and XML
Another way to create different outputs of XML data without leaving the client side is through the use of stylesheets. In this way, the viewable content can change in response to user interaction by applying an XSL stylesheet to the XML DOM representation.
The next example will build upon the previous example by using XSL stylesheets instead of scripting to create output. Each time a hyperlink is selected by the user, the XML DOM is transformed using the appropriate stylesheet, and the results are displayed.
Both of the stylesheets used in this example are from Chapter 11. The cross tab stylesheet counts the occurrences of data, while the sorting table stylesheet creates linked table labels. The links cause the report to be displayed sorted on the appropriate column. The result is a Web page that displays multiple reports on a data set without any trips back to the Web server.
The code for this example is split among four files. Two are slightly modified versions of the stylesheets from Chapter 11. Another file is a JSP that will link to a JavaScript file and create a division that contains the XML. The last file is the JavaScript source file.
The Cross-Browser JavaScript Source File
The JavaScript source file begins with the sniff() function from the previous example. It sets a variable that will tell which browser is being used, then invoke the load() function.
The load() function then switches according to those previously set variables and executes browser-dependent code. The Netscape processing begins through the creation of a DOM object representing the XML data found in the HTML division. This is repeated from the previous example.
Here is where the similarity ends. In the previous example, this DOM object was used through script to create an output table. In this example, two more DOM objects are created, and XSL files are loaded as shown here:
objTableSort = document.implementation.createDocument("","",null); objTableSort.load("TableSort.xsl"); objCrossTab = document.implementation.createDocument("","",null); objCrossTab.onload = rptCrossTab; objCrossTab.load("CrossTab.xsl"); Notice that the rptCrossTab function has been passed to the objCrossTab DOM object for its onload event handler. This will result in the invocation of the rptCrossTab function when the document has finished loading in Netscape.
Another DOM document is then created to hold the transformation results:
objOut = document.implementation.createDocument("","",null); Finally, the xsltProcessor() method is used to construct the object that will perform all the transformations:
xsltProcessor = new XSLTProcessor();
Next in the load() function you find the IE-specific code. As in the previous example, the XML is obtained from the division and loaded into a DOM representation. Then the two stylesheets are also loaded into DOM objects using the MSXML2 parser as shown here:
objTableSort = new ActiveXObject('MSXML2.FreeThreadedDOMDocument.4.0'); objTableSort.load ("TableSort.xsl"); objCrossTab = new ActiveXObject('MSXML2.FreeThreadedDOMDocument.4.0'); objCrossTab.async = false; objCrossTab.load ("CrossTab.xsl"); Note that in the previous code, the async property of objCrossTab is set to false. This causes the stylesheet download to complete before the next line of code is executed. Otherwise, the code would continue executing, and objCrossTab could possibly be used before it has completed loading.
After the stylesheets have been loaded, an XSLTemplate object is created to perform each of the possible transformations for IE:
objTrans = new ActiveXObject('MSXML2.XSLTemplate.4.0'); At this point, the rptCrossTab() function is invoked, which results in the display of the cross tab report. This simple function, shown in the following example, invokes the transform() function with the report name as a parameter. At this point, if the browser is IE, transform() is invoked on xslProc, causing the actual stylesheet and XML transformation. In Netscape, the actual transformation occurs in the JavaScript transform() function. Finally, output() is invoked to display the report:
function rptCrossTab(){ transform( "CrossTab"); if (ie){ //perform transformation for Internet Explorer xslProc.transform(); } output(); } The rptTableSort() function is next, and will result in the display of the table sort report. This function is similar to the rptCrossTab() function, except that it includes code to handle stylesheet parameters.
As shown in the following example, the rptTableSort() code for Netscape begins by getting the param element from the stylesheet DOM object using getElementsByTagName(). Note that the local element name was used, not xsl:param. Using the first element of that list, the attribute named select is obtained. The sort parameter value is then assigned as the value of the select attribute of the stylesheet parameter. After this has been completed, the stylesheet parameter has been set and transform() is invoked:
function rptTableSort(sort){ if (ns){ var nodelist = objTableSort.getElementsByTagName("param"); var nodeSort = nodelist[0].getAttributeNode('select'); nodeSort.nodeValue = sort; transform( "TableSort" ); The block of code that executes for IE is shown in the following example. It is similar, but looks like it's in a different order. The transform() method is called first, which results in xslProc using the correct stylesheet. After that is completed, the stylesheet parameter is set using addParameter() with the parameter name and value. The last parameter to this function is for a namespace URI that isn't used in this example. Now that the stylesheet parameter has been set, the transformation is performed through the use of the transform() function invoked on xslProc:
}else if (ie){ transform("TableSort"); xslProc.addParameter("Sort", sort, ""); xslProc.transform(); } Finally, the rptTableSort() function ends with the invocation of output(), which results in the display of the report.
The next function is transform(), shown in the following code fragment. This function has the stylesheet parameter and uses that string to process the correct report. With Netscape, the transformDocument() function is invoked with the appropriate parameters. One of those parameters is the objOut DOM document, created in the load() function. This is where the results will be placed.
//transform the requested xml and stylesheet function transform(stylesheet){ if (ns){ // perform transformation for Netscape if (stylesheet == "TableSort") xsltProcessor.transformDocument ( objData, objTableSort, objOut, null); else xsltProcessor.transformDocument ( objData, objCrossTab, objOut, null); With IE the stylesheet property of objTrans is set to the documentElement of the XSL DOM object, as shown in the following example. A new processor is then created with the invocation of createProcessor(). Once completed, the XML DOM is assigned as the input for the new processor. Note that for IE the actual transformation doesn't occur in this function. Rather, it occurs in the report-specific functions described earlier.
}else if (ie){ //set up transformation in Internet Explorer if (stylesheet == "TableSort") objTrans.stylesheet = objTableSort.documentElement; else objTrans.stylesheet = objCrossTab.documentElement; xslProc = objTrans.createProcessor(); xslProc.input = objData; } The last function in the JavaScript file is output(). In short, this function takes the result of the transformation and places it into divDisplay. With IE, the output of xslProc is added to the innerHTML of divDisplay as shown here:
document.getElementById("divDisplay").innerHTML += xslProc.output; With Netscape, two steps are required to display the results. The first step is to use getElementsByTagName() to obtain a list that references each table element of the transformation results. Next, the first table element found is appended to divDisplay:
}else if(netscape){ var x = objOut.getElementsByTagName('table'); document.getElementById("divDisplay").appendChild( x[0]); With that, all the JavaScript code that powers this on-demand client-side transformation is complete. The JavaScript file is shown in its entirety in Listing 13.2 and should be saved as webapps\xmlbook\chapter13\ClientTrans.js.
Listing 13.2 ClientTrans.js
var objData; var objTableSort; var objCrossTab; var objTrans; //ie only var objOut; //netscape only var xsltProcessor; //netscape only var xmlData; var divDisplay; var xslProc; var ns = false; var ie = false; function sniff() { if(window.ActiveXObject){ ie = true; } else if (document.implementation && document.implementation.createDocument){ ns = true; } if(ns || ie) load(); } function load(){ //sets up all the objects etc. divDisplay = document.getElementById('divDisplay'); if (ns){ objData = document.implementation.createDocument("","",null); var domParser = new DOMParser(); var strSome = document.getElementById('xmlData').innerHTML; objData = domParser.parseFromString(strSome, 'text/xml'); objTableSort = document.implementation.createDocument("","",null); objTableSort.load("TableSort.xsl"); objCrossTab = document.implementation.createDocument("","",null); objCrossTab.onload = rptCrossTab; objCrossTab.load("CrossTab.xsl"); objOut = document.implementation.createDocument("","",null); xsltProcessor = new XSLTProcessor(); } else if (ie){ objData = new ActiveXObject('MSXML2.DOMDocument.4.0'); xmlData = document.getElementById('xmlData'); objData.loadXML(xmlData.innerHTML); objTableSort = new ActiveXObject ('MSXML2.FreeThreadedDOMDocument.4.0'); objTableSort.load ("TableSort.xsl"); objCrossTab = new ActiveXObject ('MSXML2.FreeThreadedDOMDocument.4.0'); objCrossTab.async = false; objCrossTab.load ("CrossTab.xsl"); objTrans = new ActiveXObject('MSXML2.XSLTemplate.4.0'); rptCrossTab(); } } function rptCrossTab(){ transform( "CrossTab"); if (ie){ //perform transformation for Internet Explorer xslProc.transform(); } output(); } function rptTableSort(sort){ if (ns){ var nodelist = objTableSort.getElementsByTagName("param"); var nodeSort = nodelist[0].getAttributeNode('select'); nodeSort.nodeValue = sort; transform( "TableSort" ); }else if (ie){ transform("TableSort"); xslProc.addParameter("Sort", sort, ""); xslProc.transform(); } output(); } //transform the requested xml and stylesheet function transform(stylesheet){ if (ns){ // perform transformation for Netscape if (stylesheet == "TableSort") xsltProcessor.transformDocument ( objData, objTableSort, objOut, null); else xsltProcessor.transformDocument ( objData, objCrossTab, objOut, null); } else if (ie){ //set up transformation in Internet Explorer if (stylesheet == "TableSort") objTrans.stylesheet = objTableSort.documentElement; else objTrans.stylesheet = objCrossTab.documentElement; xslProc = objTrans.createProcessor(); xslProc.input = objData; } } //displays the transformation result function output(){ var strResult; strResult = "<a href='javascript:rptTableSort(1);' >TableSort</a><br/>" + "<a href='javascript:rptCrossTab();' >CrossTab</a><br/><br/><br/>" divDisplay.innerHTML = strResult; try{ if(ie){ document.getElementById("divDisplay").innerHTML += xslProc.output; } else if(netscape){ var x = objOut.getElementsByTagName('table'); document.getElementById("divDisplay").appendChild( x[0]); } } catch (e){ alert("Error caught in output() : " + e.description + " " + e.number ); } } The JSP
Listing 13.3 is the JSP, which holds everything together. It is very similar to the JSP found in the previous example, so it will not be explained. The changes from Listing 13.1 are noted in boldface type. Save the JSP as webapps\xmlbook\chapter13\ClientTrans.jsp.
Listing 13.3 ClientTrans.jsp
<%@page import = "java.sql.*, org.jdom.*, org.jdom.output.*, javax.xml.transform.*, xmlbook.chapter11.*" %> <html> <head> <script src="ClientTrans.js" ></script> <title>Client-Side Stylesheet Transformations</title> </head> <body onload="sniff();"> <div style="position:absolute; left:0; top:75;" id="divDisplay"> </div> <div id="xmlData" style="visibility:hidden;" > <% String final_status = ""; String db_query = "select RCD_lname, RCD_fname, "; db_query +="DATE_FORMAT(RCD_dob, '%Y-%m-%d') as RCD_dob , "; db_query +="RCD_clinic, RCD_color from reportclientdata"; String db_location = "jdbc:mysql://localhost/xmlbook"; String db_driver = "org.gjt.mm.mysql.Driver"; Connection db_connection = null; Statement db_statement = null; ResultSet rs = null; try{ Class.forName(db_driver); db_connection = DriverManager.getConnection(db_location); db_statement = db_connection.createStatement(); rs = db_statement.executeQuery(db_query); } catch (ClassNotFoundException e){ final_status = "Error: Unable to create database drive class."; final_status += " <br />" + e.toString(); } catch(SQLException e){ final_status = "Error: Unable to make database connection"; final_status += "or execute statement."; final_status += " <br />" + e.toString(); } finally { /* We must close the database connection now */ try { if (db_connection != null) { db_connection.close(); } } catch (SQLException e) { final_status = "Error: Unable to close database connection." ; final_status += " <br />" + e.toString(); } } try{ // create a resultsetbuilder to transform resultset to XML RStoXML rsxml = new RStoXML(rs, "ROOT", "REC"); org.jdom.Document jdomdoc = rsxml.build(); rs = null; rsxml = null; //create outputter to output results XMLOutputter output = new XMLOutputter(" ", true); output.output(jdomdoc, out); output = null; } catch (TransformerFactoryConfigurationError e) { final_status = "Error: Unable to create factory to transform "; final_status = "XSL and XML."; final_status += "<br />" + e.toString(); } catch (JDOMException e) { final_status = "Error: Unable to create XML from database query."; final_status += "<br />" + e.toString(); } if(final_status != "") out.print("<br><font color=\"red\"><H2>" + final_status + "</H2></font>"); %> </div> </body> </html>
The Two XSL Stylesheets
Next, we find the two stylesheets. The first, shown in Listing 13.4, is for the sorting table report and should be saved as webapps\xmlbook\chapter13\TableSort.xsl. Two differences exist between this code and the original stylesheet in Listing 11.6. First, the Page stylesheet parameter element has been removed. Second, the href attribute value of the anchor element has changed.
Listing 13.4 TableSort.xsl
<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:param name="Sort" select="1" /> <xsl:output method="html" /> <xsl:template match="/"> <table border="1" cellpadding="5"> <thead> <xsl:call-template name="header"/> </thead><tbody> <xsl:apply-templates select="*/*"> <xsl:sort select="*[$Sort]" /> </xsl:apply-templates> </tbody><tfoot /> </table> </xsl:template> <!-- creates the table headers from the tag names --> <xsl:template name="header"> <tr> <xsl:for-each select="*/*[1]/*"> <th> <A href="javascript:rptTableSort({position()} );"> <xsl:value-of select="local-name(.)" /> </A> </th> </xsl:for-each> </tr> </xsl:template> <!-- creates a row for each child of root, and cell for --> <!-- each grandchild of root --> <xsl:template match="*/*"> <tr> <xsl:for-each select="*"> <td><xsl:value-of select="." /></td> </xsl:for-each> </tr> </xsl:template> </xsl:stylesheet> The next stylesheet, shown in Listing 13.5, is for the cross tab report. This stylesheet has also changed only minimally from its original use in Listing 11.7. The only change is the addition of logic to handle the XML tags' change of case; this change is noted in boldface type in the following code. The change of case has to do with the browsers processing the XML as HTML before it is parsed into a DOM representation. IE capitalizes element names, while Netscape makes all letters lowercase. Save this file as webapps\xmlbook\chapter13\CrossTab.xsl.
Listing 13.5 CrossTab.xsl
<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:param name="NumClinics" select="5"/> <xsl:output method="html" /> <xsl:template match="/"> <table border="1"> <!-- crosstab labels of first row--> <thead> <tr><th> </th><th>Blue</th><th>Green</th><th>Orange</th> <th>Purple</th><th>Red</th><th>Yellow</th><th>Totals:</th> </tr> </thead> <!-- begin loop to create crosstab body --> <tbody> <xsl:call-template name="crosstab" > <xsl:with-param name="Clinics" select="1"/> </xsl:call-template> </tbody> <tfoot></tfoot> </table> </xsl:template> <xsl:template name="crosstab"> <xsl:param name="Clinics"/> <tr><th><xsl:value-of select="$Clinics" /></th> <td><xsl:value-of select="count(*/*[(rcd_color='blue' and rcd_clinic=$Clinics) or (RCD_COLOR='blue' and RCD_CLINIC=$Clinics)])" /></td> <td><xsl:value-of select="count(*/*[(rcd_color='green' and rcd_clinic=$Clinics) or (RCD_COLOR='green' and RCD_CLINIC=$Clinics)])" /></td> <td><xsl:value-of select="count(*/*[(rcd_color='orange' and rcd_clinic=$Clinics) or (RCD_COLOR='orange' and RCD_CLINIC=$Clinics)])" /></td> <td><xsl:value-of select="count(*/*[(rcd_color='purple' and rcd_clinic=$Clinics) or (RCD_COLOR='purple' and RCD_CLINIC=$Clinics)])" /></td> <td><xsl:value-of select="count(*/*[(rcd_color='red' and rcd_clinic=$Clinics) or (RCD_COLOR='red' and RCD_CLINIC=$Clinics)])" /></td> <td><xsl:value-of select="count(*/*[(rcd_color='yellow' and rcd_clinic=$Clinics) or (RCD_COLOR='yellow' and RCD_CLINIC=$Clinics)])" /></td> <td><xsl:value-of select="count(*/*[rcd_clinic=$Clinics or RCD_CLINIC=$Clinics])" /></td> </tr> <!-- continue looping when condition met --> <xsl:if test="$Clinics < $NumClinics"> <xsl:call-template name="crosstab"> <xsl:with-param name="Clinics" select="$Clinics + 1"/> </xsl:call-template> </xsl:if> <!-- table foot --> <xsl:if test="$Clinics=$NumClinics"> <tr><th>Totals:</th> <td><xsl:value-of select="count(*/*[rcd_color='blue' or RCD_COLOR='blue'])" /></td> <td><xsl:value-of select="count(*/*[rcd_color='green' or RCD_COLOR='green'])" /></td> <td><xsl:value-of select="count(*/*[rcd_color='orange' or RCD_COLOR='orange'])" /></td> <td><xsl:value-of select="count(*/*[rcd_color='purple' or RCD_COLOR='purple'])" /></td> <td><xsl:value-of select="count(*/*[rcd_color='red' or RCD_COLOR='red'])" /></td> <td><xsl:value-of select="count(*/*[rcd_color='yellow' or RCD_COLOR='yellow'])" /></td> <td><xsl:value-of select="count(*/*)" /></td> </tr> </xsl:if> </xsl:template> </xsl:stylesheet>
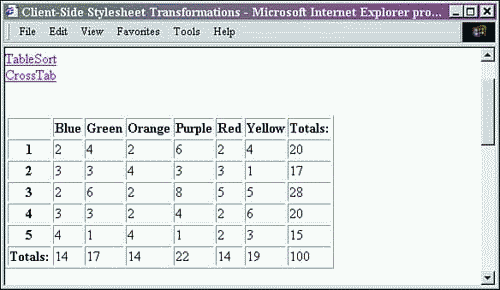
Combine them all together, and the cross tab report is displayed as shown in Figures 13.3 and 13.4.
Figure 13.3. Netscape client-side cross tab report.
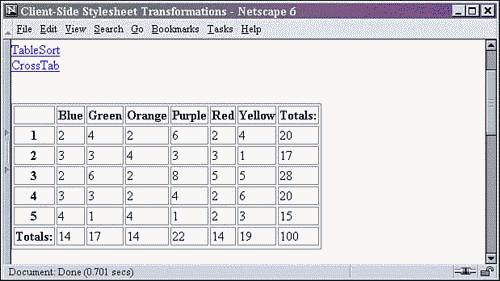
Figure 13.4. Internet Explorer client-side cross tab report.
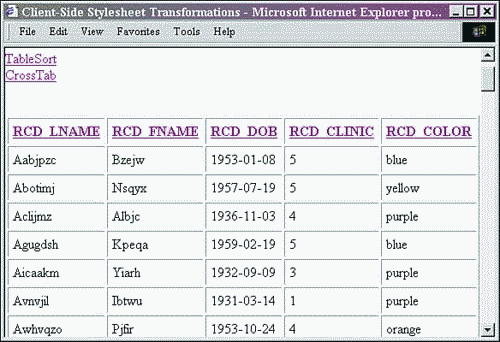
Figures 13.5 and 13.6 show the table sort report part of this Web page. Note the linked table labels that provide a mechanism for re-sorting the data on the client side. Those links are capitalized differently in Netscape and IE because of the processing of the XML as HTML when it was stored inside the hidden division element.
Figure 13.5. Netscape client-side table sort report.
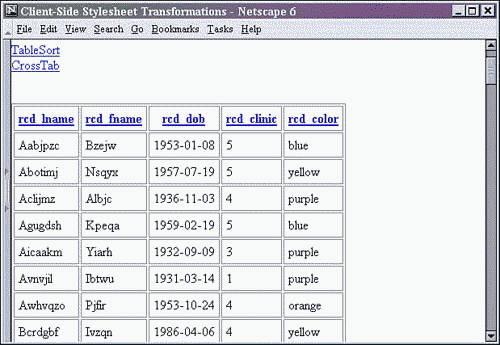
Figure 13.6. Internet Explorer client-side table sort report.
Using script and transformations are only two of the possible methods for displaying and formatting XML data. Another way is through the use of cascading style sheets (CSS). Using CSS, XML data can be formatted across platforms and devices for both display and printing. Although both browsers support CSS, Netscape has been more thorough in implementing the W3C's CSS specification.
Summary
Three main choices exist for the client-side manipulation of data. One is through the use of JavaScript. Another is through the use of the XML DOM. The last is by using the DOM Level 2 CSS Interface from the W3C. Each of these choices provide the means for manipulating data, allowing it to be dynamically reformatted, hidden, and shown.
| CONTENTS |
EAN: N/A
Pages: 26