Failover Clustering
|
|
Failover clustering is the most effective high availability option in a SQL Server environment. It uses Microsoft Clustering Services (MSCS) to manage the servers. With MSCS, if a failure occurs in a critical hardware component or in the SQL Server service, the drives, SQL Server, and associated services will fail over to the secondary server. The main components of clustering SQL Server are as follows:
-
Cluster node A cluster node is a server that participates in the cluster. With Windows 2000 Data Center, you can have up to four, and with Windows 2000 Advanced Server, you can have up to two cluster nodes.
-
Shared disk resource SQL Server places its data files on a shared disk, whether through SAN storage or a shared SCSI.
-
Private disk resource When you cluster SQL Server, you will also need a private disk for installing the SQL Server executables.
-
Heartbeat MSCS will execute a query against the SQL Server every five seconds to ensure that the SQL Server is online. If the heartbeat doesn't receive a response, a failover occurs.
-
SQL Server virtual IP address Your applications will actually connect to your virtual IP address (VIPA) when they want to connect to your database. This IP address will move to whichever node owns SQL Server.
-
SQL Server network name Like the VIPA, the SQL Server network name moves with the other SQL Server resources. Your applications will connect to the SQL Server network name instead of the real name of the server when they want to connect to SQL Server.
-
SQL Server resources Each of the SQL Server services is represented in MSCS: SQL Server, SQL Server Agent, and SQL Server Fulltext.
-
Quorum disk The quorum disk is a shared disk between the nodes that contains information about the state of the cluster and MSDTC.
-
Windows virtual IP address and name Although not related to SQL Server, it's worth mentioning that Windows also has a VIPA and network name.
In Figure 10-18, you can see the basic topology of an MSCS cluster. I'll discuss how it all integrates together in just a moment.
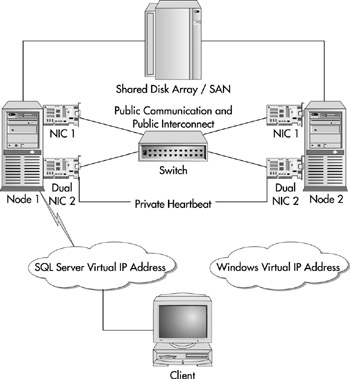
Figure 10-18: Basic clustering configuration
The Failover
MSCS will perform two types of checks using the heartbeat connection to confirm that the SQL Server is still operational: LooksAlive and IsAlive. These checks are performed at both the operating system and SQL Server levels. The operating system performs these types of checks by having each node compete for the cluster's resources. The node that currently owns a given resource reserves it every 3 seconds, and the other nodes attempt to gain ownership of the node every 5 seconds. This process lasts for 25 seconds before restarting.
On the SQL Server side, the node that currently owns the SQL Server resource does a light LooksAlive check every 5 seconds by checking to see if the SQL Server service is still started. Even if the SQL Server service is started and passes the LooksAlive check, it may in actuality be down. The IsAlive check performs a more exhaustive check by running a SELECT @@SERVERNAME query against the SQL Server. If the query fails, it is retried 5 times. If all 5 attempts fail, the resource fails over.
When the resource fails, MSCS will either restart the service on the same node or fail it over to one of the secondary nodes. This is dependent on what the failover threshold is set at. I'll discuss the configuration of MSCS in the next chapter.
| Note | When SQL Server service restarts on the new node or on the existing node, it may take some time for the SQL Server to roll forward the transactions and incomplete transactions to roll backward. |
Upon failover, SQL Server stops and starts the SQL Server and supporting services, which disconnects all active connections. The drives, SQL Server network name, and VIPA all fail over with the SQL Server service. Since the application uses the SQL Server network name and VIPA, the application doesn't care which node owns the database. From the application perspective, the application will need to reconnect to the SQL Server. If you've built a web application, users would probably just be required to refresh their browser.
| Tip | You will want to ensure in your application that you have proper reconnect logic built into the program. This can be done by using the clustering API or with reconnect logic. The clustering API is the preferred method to detect failover in your application and details can be found in Microsoft article Q273673. You can also build logic into your application that will check if the connection is dropped, then attempt to reconnect every five seconds. If you cannot afford to lose any transactions, you may want to use some type of middleware application like BizTalk, MTS, or Microsoft Message Queue (MSMQ). These types of programs will queue transactions in event of a failure. |
Single Point of Failure Options
Before we go into the various types of clustering, it's important to show you a few of the architectural decisions you'll need to make before you begin clustering. Primarily, you will need to prepare yourself for what points of failure are acceptable to you in your clustering scheme. In this section, I'll discuss the various types of supportable hardware configurations you can do for your cluster.
The minimum supportable configuration for MSCS is to have two network cards for each node as shown in Figure 10-19. In this configuration, your heartbeat is handled through NIC 1. This can simply be done through a cross-connect cable to make things simple for you. The second network card handles public communication and also backs up the heartbeat (out of NIC 1) in case of a failure. Your applications would communicate to the cluster out of NIC 2, though, which does present a single point of failure.
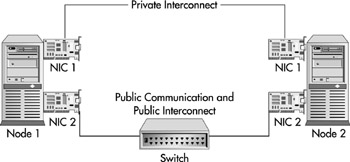
Figure 10-19: Minimum supportable cluster configuration
As I just mentioned, the previous has a single point of failure with NIC 2. If that card were to fail, all external communication to the cluster would cease. The cluster would essentially be down. A more common solution that I would recommend at a minimum is what is seen in Figure 10-20. In this figure, you can see that we've switched NIC 2 to a dual NIC, which has two Ethernet ports, one for the heartbeat (private communication) and the second for public communication. The public communication out of NIC 2 backs up NIC 1 in case of failure. NIC 1 also backs up NIC 2's private heartbeat. This server layout would eliminate any single point of failure for the communication in a cluster. Figure 10-20 does not include the power supplies and UPS system in the diagram. This would also need to be separated out for full redundancy. You wouldn't want a single bad UPS to bring down your entire cluster.
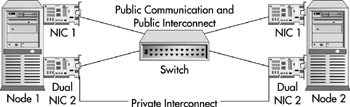
Figure 10-20: Minimum recommended cluster configuration
To completely eliminate single points of failure on the network side of the cluster, you would have to use something similar to Figure 10-21. As you can see, we've changed the dual NIC in Figure 10-20 with two network cards, for a total of three. Private communication is handled out of NIC 1's cross-connect cable. NIC 2 and 3 both back up private and public communication. We've also added an extra switch to make sure it's not a single point of failure.
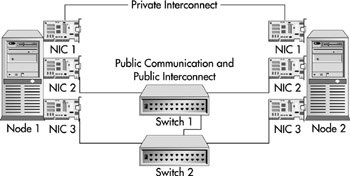
Figure 10-21: No communication single point of failure server configuration
| Tip | I prefer to use cross-connect cables for the private heartbeat communication. This communication is quite chatty on the network and is faster when done with a cross-connect. Also, if there is any 'hiccup' in the network, it could cause MSCS to think the node is down and fail over the cluster. |
Single-Instance Clusters
The most basic type of cluster is a single-instance cluster, which previously was called an active/passive cluster. Most administrators who have been clustering servers for a while use the two terms interchangeably. A single-instance cluster is where you have a single instance of SQL Server between both nodes running at any given time. Even though you have two servers, you need only pay the license for the active node (node that has SQL Server started) since the SQL Server service is turned off on the passive node (or the server that has not reserved SQL Server).
In a SQL Server single-instance cluster, if you were to go to the Services applet on both nodes you would see that only one node has the SQL Server service started at any normal time. Table 10-4 shows you how MSCS manages the SQL Server services in a single-node cluster (SQL Server, SQL Server Agent, and Fulltext). Although MSCS allows you to start SQL Server through the Services applet, always start SQL Server through the Cluster Administrator unless there is a cluster problem. I'll talk about the clustering tools, such as Cluster Administrator, in the next chapter.
| When Node 1 Owns SQL Server | When Node 2 Owns SQL Server | ||
|---|---|---|---|
| Node 1 | Node 2 | Node 1 | Node 2 |
| Services Started | Services Stopped | Services Stopped | Services Started |
| Note | I personally don't like creating one-instance clusters, because you have only a single node answering requests while the other site is idle. You can make the second node a file server or an analysis server if you want to use the second node for something and don't want to choose multiple instances. |
Multiple-Instance Clusters
Multiple-instance clusters were formerly called active/active clusters. Essentially, they allow you to overcome the big disadvantage of single-instance clusters. That disadvantage is that you have two expensive servers and one is sitting idle, not taking any types of database requests. A multiple-instance cluster allows you to install a second instance (or more) on the other node. You can install up to 16 instances total in the cluster.
| Note | You are required to license a multiple-instance cluster as two servers, which will require two individual SQL Server Enterprise Edition licenses. |
If you were to go to the Services applet in Windows, you would see a slightly different service configuration. After the first instance of SQL Server, each following one would be a named instance. For example, the second instance installed on the second node would use the named instance standard of MSSQLServer$InstanceName for the SQL Server service name. You would see this service installed on each of the nodes. In Table 10-5 (see above), you can see how the services would be configured for both instances of SQL Server in a multiple-instance environment if everything is failed over to the proper location (1 is the default instance on Node 1, and 2 is the second instance on Node 2).
| Node 1 | Node 2 |
|---|---|
| (1) Services Started | (1) Services Stopped |
Upon failure of Node 1, the SQL Server service will stop on Node 1 and start on Node 2. At that point, both SQL Server services will be running on Node 2 as shown in Table 10-6.
| Node 1 | Node 2 |
|---|---|
| (1) Services Stopped | (1) Services Started |
Because at any given time both instances of SQL Server may be running on one machine, you will need to make sure that each node has enough resources to handle the added load. You will also need to make sure that RAM usage has a ceiling, preventing one SQL Server service from suffocating the other.
| Note | There's no magic button to go from a single-instance to a multiple-instance cluster. You must install the second instance of SQL Server to make it a multiple-instance cluster. |
Other Preclustering Considerations
Before you get ready to cluster, there are a few more items to make sure you've considered. You'll need extra IP addresses since you're dealing with virtual network names. There are also some added firewall concerns with clustering that will need to be managed.
IP Addresses
I'm not sure about your environment, but in mine, static IP addresses are at a premium and take a week to obtain. Because of that, you will need to plan out your SQL Server cluster carefully. At a minimum in a two-node single-instance cluster, you will need six IP addresses. As you add additional instances, you will need additional IP addresses for each instance. At minimum, you'll need IP addresses for the following:
-
Two IP addresses for each of the Windows servers (two in our example cluster). These will act as the real IP addresses for the server. One IP address per server will be used for the private heartbeat communication (generally a cross-connect cable). The second is for public communication. The heartbeat IP address could be a private IP address since you'll be using a cross-connect cable.
-
One VIPA for the Windows cluster name.
-
One VIPA for each node instance you install of SQL Server.
| Tip | When configuring your network cards, do not use the Autodetect setting for your network card. Set all public network cards to 100MB full-duplex if they have the option, and the private heartbeat connection should be set to 10MB half-duplex. |
Firewall Considerations
The first instance of SQL Server is given port 1433 by default and the following installations are given new ports. You can share the default port across all SQL Server, although I would recommend against it. As a best practice, always use a different port for each instance of SQL Server. There are a number of bugs and unexpected behavior that you may encounter by leaving the same port across all nodes of SQL Server.
If you have a firewall, you must also enable the ports for MS DTC to communicate to the application if you use its functionality. MS DTC calls come into the VIPA but respond out the server's real IP addresses. MS DTC also uses a range of ports that may be unpredictable. You can pin down what ports MS DTC communicates on by modifying the registry on both nodes of SQL Server and the web server. Information on how to adjust this registry setting can be found in Microsoft KB article Q250367.
Many programs, such as BEA Software's WebLogics, can only see one instance of SQL Server per server unless you use a unique port per SQL Server. This is another reason why you should have a unique port for each instance.
Services
After each step of the cluster installation it's critical that you check the Windows System and Application logs to ensure there are no errors. You also want to ensure that the services listed in Table 10-7 are started before beginning the SQL Server cluster installation.
| Alerter | Plug and Play |
| Cluster Service | Process Control |
| Computer Browser | Remote Procedure Call (RPC) Locator |
| Distributed File System | Remote Procedure Call (RPC) Service |
| Distributed Link Tracking Client | Remote Registry Service |
| Distributed Link Tracking Server | Removable Storage |
| DNS Client | Security Accounts Manager |
| Event Log | Server |
| License Logging Service | Spooler |
| Logical Disk Manager | TCP/IP NetBIOS Helper |
| Messenger | Windows Management Instrumentation |
| Net Logon | Driver Extensions |
| Windows NT LM Security Support Provider | Windows Time Service |
| Network Connectors | Workstation |
You also want to ensure that services like SNMP and any firewall software are stopped. I also stop any services that are provided by the hardware vendor. These services will sometimes interfere with the cluster installation and can be started again once the server is restarted after the successful installation.
Domain Considerations
You will need to ensure that all servers in a cluster are on the same domain. Before you begin, you'll need an administrative account to set up clustering with. You'll also want to make sure that the two servers can see the DNS server, and it is also recommended to have a WINS server for name resolution.
Now that you know about the basic architecture and terminology of clustering, the next chapter will jump into actually creating your first cluster.
|
|