6.1 Authoring XML You can hardly name an area in modern computer science where XML is not used. With such a wide applicability domain, the requirements of XML authors are naturally quite diverse. No software, "industry standard" or no "industry standard," can reasonably claim to satisfy all such requirements. Don't feel envious if your authoring tool isn't the latest buzz; chances are you don't need most of the features you are reading about in press releases, but instead need something completely different. In our own area, web development, we can distinguish at least three very different usage patterns and corresponding sets of requirements. Most users of XML authoring tools will likely belong to one of the following three classes: -
site developersthose who create the site's source definition, schemas, and stylesheets; -
content authorsthose who write original content for the web site; and -
site editorsthose who maintain the site, update pages, post stories submitted by authors, and so on. The features that these categories of users want in an XML authoring tool are not only different but in some aspects even contradictory. Developer's workbench. The ideal XML editor for a site developer is, above all, an XML editor. It must be a powerful tool fluent in both XML in general and many XML vocabularies and formalisms in particular. It must not be restrictive in any way; if the tool cannot perform a task automatically, it must at least not prevent the developer from doing it manually. Smart tools are good, but they should not try to be smarter than their user . Usually, source-oriented editors ( 6.1.1 ), such as Topologi's CME, [1] best suit this category of users. [1] www.topologi.com
In short, a developer's XML editor must be a versatile workbench, with all sorts of devices and appliances for any imaginable taskfrom sophisticated and almost intelligent power tools to a mere screwdriver. Author's writing desk. An XML editing application for a content author is a different story altogether. Since the job of authors is creating content for web sites, what they need is, above all, a content editor aware of XML. Note the word "aware"; such a tool must not require (or demonstrate ) more XML knowledge than absolutely necessary. Authoritative and therefore restrictive, yet friendly and forgiving these are the qualities that will help such a tool to fulfill its primary purpose: help the author concentrate on content while producing valid and sensibly structured XML documents. For most authors, word processor XML editors ( 6.1.4 ) such as Morphon [2] work best, although for database-like XML, form-based editors ( 6.1.3 ) are preferable. [2] www.morphon.com So, if the developer's editor is a workbench, then for the author, a good metaphor would be an austere writing desk with nothing but an ink pot and a sheet of white paper (or an empty form to fill). A dictionary would be handy too. Editor's assembly line. A small site with occasional updates does not need any specific maintenance software, and this is especially true for an XML-based site whose source is so transparent. If, however, you frequently update a huge site, what you need is not a standalone editing tool but a complete content management system (CMS). CMS software is not specific to XML; in fact, much of it still does not support XML too well. Those systems that are XML-aware (e.g., Lenya [3] ) implement one of the traditional XML editing approaches (such as form-based editing, 6.1.3 ). [3] cocoon.apache.org/lenya; formerly known as Wyona. What differentiates CMS tools from regular editors is their ability to work with many documents at once. Ability to combine documents into projects, storage and retrieval automation, versioning, scheduled updatesthese features make a CMS similar to an assembly line where long queues of documents are being worked on in a semiautomatic fashion. What lies ahead. CMS software is in a world of its own, but it is not directly related to XML and therefore is not analyzed in this book. Instead, we'll start this chapter with an overview of the main categories of XML authoring tools. Several approaches to XML editing exist today. Some tools implement more than one approach and let you switch between them on the fly; others focus on one approach only. Below we'll examine these approaches, discuss their advantages and disadvantages, and look at some example implementations . 6.1.1 Source editing It's as simple as that: What you have in front of you is the full and complete source document, the way W3C intended it to be. Nothing but straightforward, uncompromising , truly open source XMLas in, for instance, this book's markup examples. You can do it too. There's no arguing that XML source editing is more suitable for developers than for authorsbut not by much. After all, one of the main goals of XML was to make documents as human-readable and human-editableas possible. By properly designing your source definition (choosing logical names , separating site-wide metadata, abbreviating addresses, etc.), you can push this editability even higher. In fact, the entire book you are reading is devoted to the ways of making XML transparent and accessible to anyone , not only developers. 6.1.1.1 Features Source editing of XML is not the same as plain text editing. Most of the convenience of source-oriented editors is in their XML-specific features. Below is an attempt at classifying these goodies . -
Generic XML features are those capabilities that can be useful for any XML document, no matter what schema it conforms to (if any). These are the most basic and frequently used commands, such as closing the currently open element, navigating to the start tag or end tag, commenting or uncommenting a fragment, highlighting well- formedness errors, indentation, and manipulating character data (e.g., replacing all special characters with their numeric character references and vice versa). Some of these features require that the entire document be well- formed , but many will work regardless. -
Schema-specific features , often called guided editing , take advantage of knowing the schema of the document you're working with. Only a grammar-based schema ( 2.2.1 ) can be used in this waySchematron is useless for guided editing (except for simple validation). Guided editing features usually include listing element types or attributes that are valid at a specific point, automatic insertion of required constructs and fixed values, and validation of the edited document (highlighting errors and providing suggestions on how to fix them). -
Syntax coloring is a simple but extremely handy feature that can make a world of difference in terms of usability. Unfortunately, many editors treat syntax coloring simplistically, offering separate colors only for generic classes of constructs such as comments, elements, entities, and character data. Such generic syntax coloring is the absolute minimum you might require from an XML editor. Much more useful is specific syntax coloring, which allows you to separately color distinct namespaces, elements, and attributes. Coloring of some element might determine or affect the color of its children or character data. In some situations, even monolithic character data can be usefully parsed and coloredfor example, the expressions inside { curly braces } in attribute values in XSLT. Traditionally, source editors use a single monospaced font for displays. However, more sophisticated editors can assign not only different colors but also different font sizes and faces to source constructs. This is the approach used for the source code examples in this book (you cannot use color in a black-and-white book anyway); of the editors mentioned in this chapter, XEmacs (Figure 6.1) demonstrates this capability. Such advanced syntax coloring is reminiscent of the word processor XML editing mode ( 6.1.4 )except that it does not attempt to hide anything. Figure 6.1. XEmacs: Editing an XSLT stylesheet with generic XML editing commands. 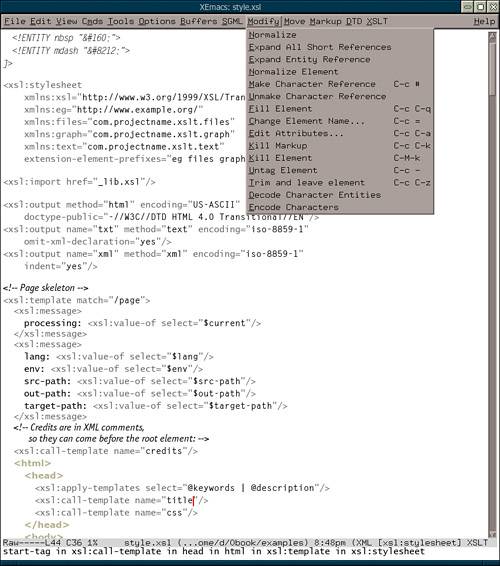
-
XPath tools are not confined to XSLT stylesheets; they come in handy for various editing operations. Running an XPath expression against the document you are editing to see the result(s) highlighted is a good complement to (or even a substitute for) the traditional plain-text or regexp search. It is especially useful, of course, for writing and debugging XSLT stylesheets; yet after a while, you'll probably learn to "think in XPath" and start using XPath expressions in other XML editing tasks (see also 6.3.2 ). -
External processing may include XSLT transformation, validation with external tools, and running various previewing or visualization applications. Basically it is just a way to save you switching to a command line to run a command on the document you are currently editing. -
Project management is an optional but very useful addition to the feature set of a source-oriented XML editor. It allows you to define a group of documents as a project , after which some commands may act on the project as a whole. For example, you might be able to transform or validate all *.xml files of the project (similar to the batch processing mode of the stylesheet, 5.6 ), or run a text search or an XPath expression against the entire project. Moreover, sometimes you can define various relationships between members of a project, such as dependence (if one document is changed, the one depending on it is also considered changed and should be transformed again; compare 6.5 ). Most of these features are a boon for all three categories of XML users (developers, authors, editors). Developers will especially enjoy XPath tools and external processing. Authors may benefit from syntax coloring (so that the document markup is appropriately subdued in appearance and does not interfere with the text) and, of course, guided editing (so that there's no need to remember the exact names of element types or their usage patterns). Finally, editors will appreciate good project management tools that may make an XML editor comparable to a CMS. 6.1.1.2 Examples Source XML editors come in two main flavors: generic text editors enhanced for XML and specialized XML editors. It's time for some nice screenshots! Emacs [4] is a venerable tool. One of the oldest text editors in existence, it is immensely powerful, customizable, and extensibleand as widely used nowadays as ever. If I am to provide only one example of a text editor, it's got to be Emacs. [4] www.gnu.org/software/emacs Along with GNU Emacs, there is a popular variant called XEmacs; [5] it has some benefits compared to GNU Emacs, but overall, the user-visible differences between the two editors are minimal. All information in this section applies to both GNU Emacs and XEmacs, but the screenshot (Figure 6.1) features XEmacs. [5] www.xemacs.org The most popular extension for editing XML (and SGML) in Emacs is called PSGML. [6] It implements a validating XML parser that can use a document's DTD (but not a schema in XSDL or any other schema language) for guided editing. Most generic XML editing commands are also available. [6] psgml.sf.net Other than that, PSGML has little to offer by itselfbut it can work together with other Emacs tools to provide additional functionality. Thus, external processing is not included in PSGML, but you can either program it into Emacs yourself or use other Emacs packages such as XSLT-process ( 6.4.3.2 ). Similarly, the syntax coloring provided by PSGML is generic, but you can define your own coloring regexps to cover the namespaces, element types, or other constructs that you use most frequently. XPath is not yet supported by any Emacs tool, but external XPath utilities ( 6.3.2 ) may be called from within Emacs. An XEmacs window with our stylesheet ( style.xsl , Example 5.21) is shown in Figure 6.1. It demonstrates custom, specific syntax coloring (e.g., XSLT instructions are easy to distinguish from HTML literal result elements) using both different colors and different font faces as well as a menu of generic XML editing commands. Overall, Emacs requires a significant investment in terms of learning time and effort, but the return on this investment may be really good, giving you power and freedom that are hard to achieve with more specialized tools. For an example of a specialized XML editor, let's look at < oXygen /> [7] (Figure 6.2). Written in Java, it is pretty typical of this kind of software. Mostly source-oriented, <oXygen/> also offers a tree editing mode ( 6.1.2.1 ). Here's this editor's scorecard: [7] www.oxygenxml.com -
The guided editing features of <oXygen/>in particular, context-sensitive element and attribute suggestionsare branded under the name "Code Insight." They can use both DTDs and XSDL schemas as the grammar definitions for a document. The interesting part is that <oXygen/> can generate a DTD itself from a well-formed XML document (see also 6.3.3 ). This means that a partially written document can "guide itself," helping the author keep its structure consistent. -
Syntax coloring is generic. You can define colors for elements, attributes, attribute values, etc., but you cannot differentiate, for example, XSLT instructions from literal result elements in a stylesheet. Unlike a generic text editor such as Emacs, you cannot implement this functionality yourselfthis is the price you pay for the convenience of an all-in-one package. -
The XPath capability is very handy. Right above the document editing window, you type your expression into a text field and hit Enter . A frame pops up at the bottom of the window listing the results of the query. As you select one of these results, the corresponding fragment in the editing window is highlighted. -
The editor has a built-in XSLT processor that can conveniently be used for transforming the documents you edit, optionally rendering an XSL-FO transformation result into PDF (using FOP [8] ). Besides, the external processing feature in <oXygen/> lets you run any program on your documentfor example, you can validate a document with an external Schematron validator (by itself, <oXygen/> does not support Schematron). [8] xml.apache.org/fop -
Project management is quite simpleno file dependencies, no batch transformation or validation; <oXygen/> projects are little more than a convenient way to open a group of files at once. Figure 6.2. <oXygen/> XML editor: Project view, document source, and an XPath expression. 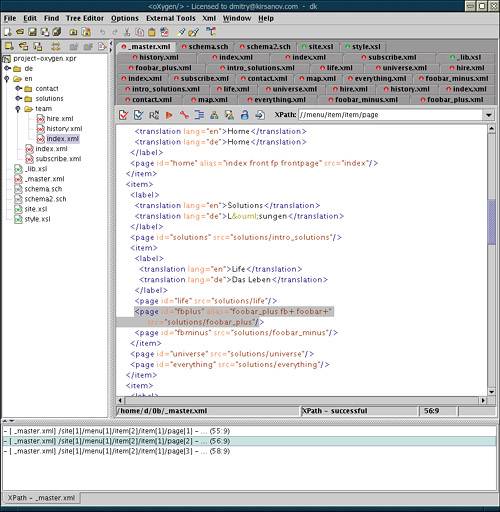
Topologi's Collaborative Markup Editor [9] is another source-oriented XML editor written in Java, notable for its extensive code formatting features and groupwork support. Perhaps most interestingly, CME is one of the very few XML editors to support interactive Schematron validation (in addition to other schema types); it highlights offending constructs and displays the corresponding diagnostic messages in the status bar. Like <oXygen/>, CME can deduce a grammar from an existing document using the feature called "Examplotron." [9] www.topologi.com Transforming Editor. Previous examples of source-oriented XML editors (both generic and specialized) demonstrated some of the ways to combine traditional text editor functionality with XML-specific additions, such as evaluating XPath expressions, for efficient editing of XML documents. However, the powerful concepts of XML and XPath are applicable to more than XML editing. I have written a proposal [10] for a new kind of all-purpose text editor that uses trees of nodes as its data model and an XPath-enabled language such as XSLT for transforming these trees. The two key ideas are representing the document being edited as a number of synchronized trees called views , each reflecting a different level of abstraction over document content, and automatic propagation of changes made to any of these views by transforms that link the views together. [10] www.kirsanov.com/te
An XPath interface to all active document views allows the user to program new editing functionality at the appropriate abstraction level, using any XPath-enabled scripting language. Views take much of the boring work out of creating editor commands; for example, you can use XPath to access a view where your document is preparsed into words, or paragraphs, or XML constructs. You can modify, rearrange, or syntax-color any element of any view, and the change will be reflected in all other views of the document down to the lowest -level "characters" view that directly corresponds to the editor's screen display. Any feedback from readers who find this idea interesting or might be able to help with the implementation will be much appreciated. [11] [11] dmitry@kirsanov.com 6.1.2 Graphical XML editing The main advantage of source editing is its transparency: Nothing is hidden; the document is visible down to the smallest detail. However, the flip side of this advantage is that too much detail may sometimes distract you from the task you want to perform. A lot of syntax details of serialized XML (such as the exact layout of whitespace inside tags) do not affect the meaning of the document, yet they take up screen space and require extra keystrokes when editing. On the other hand, the hierarchical structure of an XML document may not be obvious from the mess of names and angle brackets on your screeneven with specific syntax coloring ( 6.1.1.1 ). In view of this, several approaches to XML editing have emerged that try to reduce the amount of information that you have to mentally parse when looking at a document. Also, these approaches attempt to make the markup look more consistent, more distinct from the data, and more explicitly hierarchical. One thing that is common to all these approaches is the use of various graphic icons or metaphors to represent the structures described by the XML markup. 6.1.2.1 Tree metaphor The most obvious graphical representation of an XML document is, of course, a tree. In a source view, the tree structure is not explicit; for example, you have to count the unclosed open elements in order to find out at which level of the tree hierarchy you are standing. Many XML editors therefore offer a separate tree view of the document. An example of such a tree view is provided by the <oXygen/> editor (Figure 6.3). The branches of the tree can be expanded or collapsed as needed. Attributes are represented as separate leaves of the tree, as is the data content of elements. Branches can be copied -or-moved by drag-and-drop or copy-and-paste and, of course, all names and values are editable without leaving the tree editor. Figure 6.3. <oXygen/> XML editor: The tree view of an XML document and an XPath expression. The information in the panes at right (the current element's content model, lists of all defined elements and entities) comes from the DTD, which in this case was generated automatically by the program from a sample document. 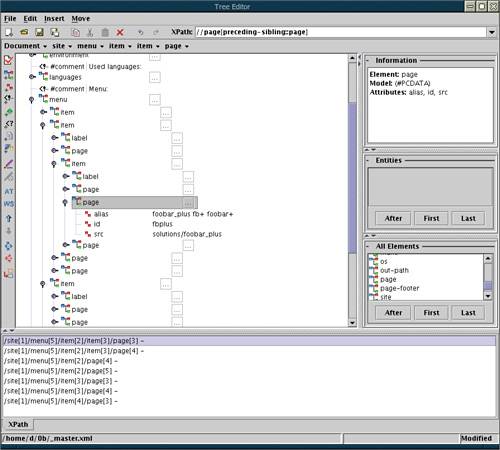
<oXygen/> is a pretty straightforward realization of the tree metaphor. It may be handy for a quick overview of the structure of a document, but it is hardly suitable for real document editing sessionsicons are noisy , and the tree looks kind of awkward . Is there a better alternative? 6.1.2.2 Frames metaphor Let's have a look at the open source Java-based XML editor called Pollo [12] (Figure 6.4). Its display is somewhat tree-like, but the advantages it offers over a traditional tree representation are significant. Instead of icons hanging from the branches of a tree, elements in Pollo are represented by colored frameswhich is quite natural if you consider that an element in XML is supposed to enframe its content. Instead of drawing connection lines symbolizing tree branches, Pollo simply nests these element frames into one another like matryoshka dolls . [12] pollo.sf.net Figure 6.4. Pollo XML editor: Tree-like view with "frames" representing elements. Lists of allowed element types in the panes at right implement guided editing based on a DTD or an XSDL schema. An XPath expression highlights the first match and lets you scroll the list of all matches. 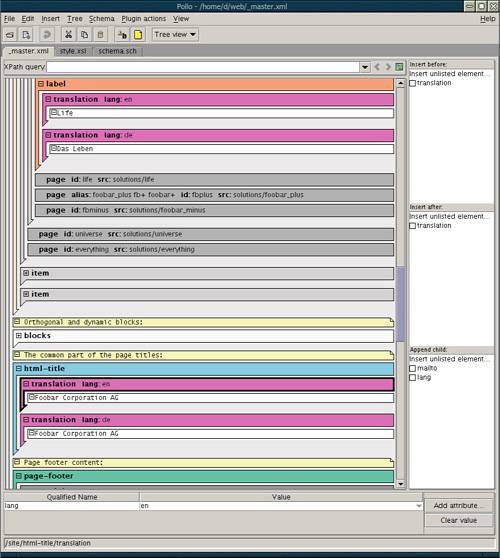
This approach is similar to a tree view in that the nesting level of any node is immediately visible. However, since element frames are painted with different colors, you can get a visual clue as to exactly which elements are the ancestors of the current one, not only how many of them there are. All elements of one type are represented by frames of the same color. These colors can be generated by the program randomly , or you can set an exact color for each element type in a "display specification" associated with your schema. Thus, Pollo's implementation of specific syntax coloring ( 6.1.1.1 ) creates a visually rich but consistent and easy-to-navigate display. Attributes are conveniently positioned on the top bar of an element's frame. At the bottom of the window, an editing area lets you change the values of attributes and edit text nodes. Just like a branch in a tree, any frame with its content can be collapsed into a plain horizontal bar. Admittedly, Pollo's XML display is not the best for freeform documents (for example, mixed content looks awkward when inline elements are stacked vertically between two text nodes). However, for predictably structured XMLsuch as configuration files, a web site master document, or a Cocoon sitemap ( 7.2.3 )this interface is very intuitive and convenient. Overcaffeinated! Why is so much XML software written in Java? One reason is Unicode: The XML specification requires that any XML processor must understand Unicode, and Java does that natively. Another reason is that Java, being a nice high-level language, makes it easy to write complex programs (and XML programs are complex, even though XML itself is so simple). But most importantly, it's a snowball effect: The more XML software is already written in Java, the more likely it is that a new XML project will choose this language too (especially contagious in this respect is, of course, open source software). However, other languages' XML snowballs are already rolling (Python shows a lot of potential), and they may one day overtake the Java snowball . 6.1.2.3 Iconic tags Yet another approach to representing XML graphically is similar to the frames metaphor in that each element is enclosed in a graphical envelope. This time, however, these envelopes are not arranged in any semblance of a tree; instead, the opening and closing tags of each element are shown as icons bearing the name of the element type. It might be argued that this approach is betterif only marginallythan direct source editing. It helps markup stand out from the text and hides most nonessential syntax details of XML. Also, it removes some of the clutter from document presentation by hiding attributes (they are usually only displayed for one element at a time by a special command). Iconic tags are a convenient way to edit text-oriented documents concentrating on the data but keeping the markup structure in sight. This approach to presentation is often combined with CSS-controlled formatting of element content, as in word-processor-like editors ( 6.1.4 ), for additional visual clues on the roles of element types. The Morphon [13] XML editor demonstrates this feature in Figure 6.5. Microsoft Word 2003 Professional Edition operates similarly, but uses Word's own style tools rather than CSS. [13] www.morphon.com Figure 6.5. Morphon: Editable CSS-controlled presentation of an XML document. Icon tags let you see what element you are editing, but they can be turned off for a pure word-processor-like interface. 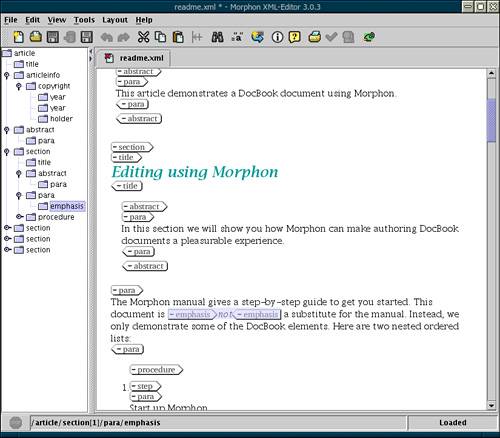
6.1.3 Form-based editing Up to this point, all XML editing paradigms we discussed (source editing, graphical editing) were primarily developer-oriented . An author or editor might use them too, of course; yet, without XML experience, it is easy to be overwhelmed by a rich detailed display (even in a graphical mode) and a plethora of commands and options (even with guided editing). It may be difficult to fully concentrate on the content when what your editing tool shows you is so in-your-face XML. The remaining two approaches to XML editing that we'll now discuss are therefore more author-oriented than developer-oriented. Their goal is to hide as many nonessential details as possible, yet not let the user stray from a valid document structure. The first of these approaches is form-based XML editing. It is perhaps the simplest possible interface for the user: no need to know XML, no need to think what is what and how to name anythingjust fill out the form. Given the sheer number of forms we have to do in our lives, this must be relievingly easyprovided the form is well laid out and the fields are clearly labeled and commented. Generally, a form-based XML editing interface is a good idea if: -
you need to manually create lots of similar XML documents (and cannot automate this process); -
the users of this interface have minimal experience with XML or are too numerous to rely on their level of experience (e.g., in a distributed data entry project); and -
your document structure is regular and database-like, not freeform (in particular, mixed content does not usually mix well with forms). Naturally, to enable an efficient form-based interface, the developer must create a logically laid out, nicely formatted, and helpfully commented form design. Form-based XML editors, such as Ponton XE [14] and Microsoft InfoPath, [15] provide various tools for this task. The starting point is usually a schema or DTD that is transformed into a form with one input field per attribute or element. You can then rearrange these fields, format them as appropriate, add explanatory labels, and so on. [14] www.ponton-consulting.de/english/xe.html [15] www.microsoft.com/office/preview/infopath All types of interface widgets can be creatively used for a rich but logical form interface. For example, portions of the form sheet may expand or collapse, making it similar to the tree XML view ( 6.1.2.1 ). Indeed, a form is sometimes accompanied by a parallel tree view of the same document. Tabular forms. Closely related to form-based editing is the table metaphor, often found even in those XML editors that are otherwise freeform text-oriented. When a document contains a sequence of similarly structured elements, a table can be compiled from their content and attributes. This makes it easy to compare and modify parallel structures in predictably structured (database-like) XML. Smart forms. You may want to embed various validation checks into your form, such as calculations or comparisons triggered by the completion of a field, a group of fields, or the entire form. Note that the structural validity of the resulting document is already ensured by the structure of the form itself, so there's little sense in DTD validation. XSDL is more useful, as it can perform data type checks of the form's values. However, XSDL cannot work with an incomplete document and therefore does not support on-the-fly checks in a form being filled in. There are two main approaches to building "smart forms" capable of controlling their interaction with the user. One is form scripting : Just as you use JavaScript with HTML forms, you can use a scripting language in your XML form to perform any interface actions or data processing in response to events (such as the user entering a value). In fact, a simple form-based XML editor might be built out of a plain old HTML form coupled with a script that saves the form input as XML. Another example of a script-based editor is Microsoft's InfoPath ( 6.2.3.4 ); although it attempts to reduce the amount of programming necessary to create a form and in many cases eliminate it completely, the resulting automatically coded form scripts may be quite entangled. Another approach to implementing smart forms is more attractive: Instead of programming various constraints and dependencies, you can simply declare them using a Schematron-like language with XPath expressions for accessing components of a form. For example, if you want a price field to be recalculated when a new currency is chosen from a drop-down list, you just state that the price field (identified by its XPath address within the form) is bound to the currency field with a simple formula. No event tracking, no function callsjust a static declaration. This is the approach of the XForms language, which we'll look at in some detail in the next section. 6.1.3.1 Using XForms The W3C XForms [16] standard has emerged as a versatile and powerfulyet not overly complextechnology that enables, among other things, an excellent interface for form-based XML editing. The XForms standard is positioned by the W3C as the next generation of HTML forms, so an XForm must be able to send its input to a web server just as an HTML form does. However, unlike HTML forms, XForms can do lots of other useful things. For our purposes, it is important that: [16] www.w3.org/MarkUp/Forms -
The result of filling out an XForm is stored in an XML document that is based on a template, called an instance , which is embedded in (or referenced from) the form and may be optionally controlled by an XSDL schema. -
Along with using a schema, an XForm can verify its input with Schematron-like declarative constraints, applying arbitrary calculations to any values in the form. -
The filled-out instance document can be saved to a local file. -
XForms constructs can be embedded into any other XML vocabularyin particular, into XHTML while using CSS for styling. Let's see what is involved in building an XForms interface for editing our own predictably structured XMLthe master document of our sample site. Example 6.1 can only display and edit the environment elements, but you can expand it to implement an almost complete master document editor. Figure 6.6 shows how this form is rendered by X-Smiles [17] a nice Java-based XML browser offering a fairly complete implementation of XForms (as well as many other XML standards). [17] www.xsmiles.org Figure 6.6. X-Smiles: Editing a subset of master document with an XForms interface from Example 6.1. 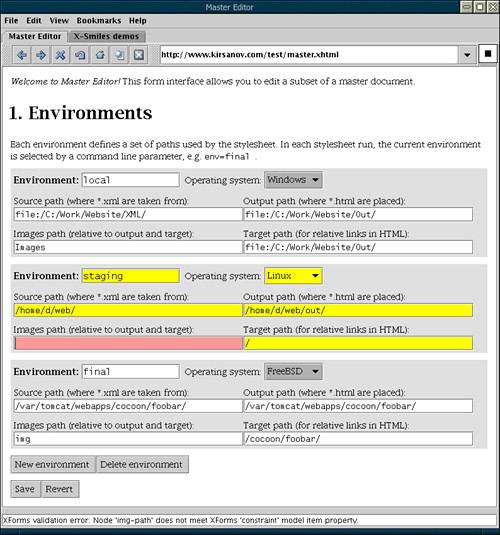
Example 6.1. master.xhtml : An XHTML document with an embedded XForm for editing a master document. < ?xml version="1.0" encoding="utf-8"? > <html xmlns="http://www.w3.org/1999/xhtml" xmlns:xfm="http://www.w3.org/2002/xforms/cr" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:ev="http://www.w3.org/2001/xml-events"> <head> <link rel="stylesheet" type="text/css" href="master.css"/> <title> Master Editor </title> <xfm:model id="master"> <!-- Source document to be edited: --> <xfm:instance src="file:/home/d/web/_master.xml"/> <!-- Save edited instance to: --> <xfm:submission id="submit1" localfile="/home/d/web/_master.xml"/> <!-- Constraint: children of 'environment' must not be empty --> <xfm:bind nodeset="/site/environment/*" constraint="string-length() > 0"/> </xfm:model> </head> <body> <p><em> Welcome to the Master Editor! </em> This form interface allows you to edit a subset of a master document. </p> <h1> 1. Environments </h1> <p> Each environment defines a set of paths used by the stylesheet. In each stylesheet run, the current environment is selected by a command-line parameter, e.g., <code> env=final </code>.</p> <!-- Repeat for each/site/environment in the instance: --> <xfm:repeat nodeset= "/site/environment" id="env-repeat"> <div class="env"> <div> <span> <!-- Bind this input field to/site/environment/@id: --> <xfm:input ref=" @id " class="section"> <xfm:label class="section"> Environment: </xfm:label> </xfm:input> </span> <span> <!-- Bind this list to/site/environment/os: --> <xfm:select1 ref=" os " appearance="full" class="os"> <xfm:label>   Operating system: </xfm:label> <xfm:choices> <xfm:item> <xfm:label> Linux </xfm:label> <xfm:value> Linux </xfm:value> </xfm:item> <xfm:item> <xfm:label> Windows </xfm:label> <xfm:value> Windows </xfm:value> </xfm:item> <xfm:item> <xfm:label> FreeBSD </xfm:label> <xfm:value> BSD </xfm:value> </xfm:item> </xfm:choices> </xfm:select1> </span> </div> <!-- Four text fields for *-path elements: --> <div> <xfm:input ref= "src-path" > <xfm:label> Source path (where *.xml are taken from): </xfm:label> </xfm:input> <xfm:input ref= "out-path" > <xfm:label> Output path (where *.html are placed): </xfm:label> </xfm:input> </div> <div> <xfm:input ref= "img-path" > <xfm:label> Images path (relative to output and target): </xfm:label> </xfm:input> <xfm:input ref= "target-path" > <xfm:label> Target path (for relative links in HTML): </xfm:label> </xfm:input> </div> </div> </xfm:repeat> <div> <!-- Button to insert a new empty environment: --> <xfm:trigger id="insertbutton"> <xfm:label> New environment </xfm:label> <xfm:insert ref= "/site/environment" at="xfm:index('env-repeat')" position="after" ev:event="DOMActivate"/> </xfm:trigger> <!-- Button to delete the highlighted environment: --> <xfm:trigger id="deletebutton"> <xfm:label> Delete environment </xfm:label> <xfm:delete ref= "/site/environment" at="xfm:index('env-repeat')" ev:event="DOMActivate"/> </xfm:trigger> </div> <div> <!-- Submit saves the instance: --> <xfm:submit name="Submit" submission="submit1"> <xfm:label> Save </xfm:label> </xfm:submit> <!-- Reset undoes all changes and reverts to loaded values: --> <xfm:trigger> <xfm:label> Revert </xfm:label> <xfm:reset model="master" ev:event="DOMActivate"/> </xfm:trigger> </div> </body> </html>
This section is not an XForms tutorial, but only a teaser to whet your appetite. Still, comparing the X-Smiles rendering with the source in Example 6.1 might be a good first lesson in XForms. We will now discuss the main components of this XForms-in-XHTML example without going into too much detail. The role model. Within the head of the XHTML document in Example 6.1, the xfm:model element describes the model of the form. An XForms model combines the XML instance that the form will populate with data, its schema (not used in this example), any additional constraints, and the submission action to be taken when the form is completed. Loading and saving. In this case, the xfm:instance element takes an external document at file:/home/d/web/_master.xml as the instance. This means that the form, when activated, will load this document and distribute its data into the corresponding form controls as default values. You can therefore provide an empty instance document as a template, or you can link your form to an existing master document with real data and use the form to change some of its values. Conversely, when the form is filled out and the submission action is triggered by the user, the xfm:submission element will save the resulting XML into the local file at /home/d/web/_master.xml . Since this is the same file as that referred to in xfm:instance , the form will effectively edit that document and save it back. If you revisit the form later, it will load the document again and display it with all the changes you made last time. Constraining input. An XForms model can also contain arbitrary constraints, exemplified here by the xfm:bind element. Such a constraint is very much like a Schematron rule in that it uses XPath to specify its context (the nodeset attribute) and the expression that must be true in that context (the constraint attribute). In the example, we declare that all children of an environment must be nonempty . A conformant XForms browser will refuse to submit the form until this constraint is satisfied. The xfm:bind element can also be used for many other purposes, such as assigning a data type to the selected nodes, controlling whether these nodes are included into the submission, or calculating values of nodes based on other nodes in the instance. Please type. In the body of the document, interspersed with arbitrary text and XHTML markup, XForms controls constitute the visible part of the form. Each control uses an XPath expression in its ref attribute to link itself to a node of the XML instance in the form's model. This link works both ways: If a node value is changed by a control or by a calculation inside the model, this change is reflected in all controls that reference that node. In our example, the xfm:repeat element iterates over all environment elements in the source. Within it, several xfm:input fields and one xfm:select1 list are linked to the child elements and an attribute of each environment . Growing the document. XForms not only makes it possible to fill in values of elements and attributes that are already present in the instanceyou can add new elements, too. Two button controls after xfm:repeat allow you to remove the current environment or add a new empty one after the current. An XForms browser is supposed to keep track of user input and always designate one of the repeat ed sections as current. For example, X-Smiles uses yellow highlighting for the section that you are currently editing (in Figure 6.6, it is the staging environment in the middle). When you're done. Finally, the last two buttons do form submission (i.e., saving the document; you will be prompted to confirm if the file already exists) and form reset (i.e., returning to the values loaded from the instance document, losing all changes you've made in this session). Before the form is submitted, all constraints defined in the model are verified . For example, in the screenshot, the img-path field within the staging environment is empty, so the browser paints it red and refuses to submit the form until a value is provided. Limitations. This example demonstrates how you can quickly and painlessly implement a rich form-based editing interface for your XML documents using XForms. Sure enough, this approach has its share of problems as well. The most important ones are these: -
The locations for the source instance and the document to be saved are hardwired into the form. That means you cannot select an arbitrary document for editing and save it to an arbitrary location (unless your XForms processor provides this functionality as an extension). This may actually be an advantage. Remember that the goal of the form-based interface is to make editing simple . From this viewpoint, there is nothing wrong with the fact that you don't need to worry about filenames and cannot mess up a document by saving it in the wrong directory. Just select one of the forms from your XForms browser's bookmarks, edit, and press one button to save. Are there examples of database-like documents that don't need to be created anew or moved from one place to the other, but only edited where they are? The master document of a web site is one such example; others are various configuration files in XML. Thus, configuring the X-Smiles browser itself is done via an XForms page that displays the options from an XML configuration file and lets you edit and save them. -
As mentioned previously, form editing is hardly appropriate for freeform XML. Unfortunately, XForms cannot handle any mixed content, even if it is but a small part of an otherwise database-like document with a predictable structure. For example, with XForms you can edit the contact-webmaster element of our master document (see Example 3.2, page 143) but you will lose its child mailto link and any other inline markup. XForms browsers may provide extensions [18] to overcome this limitation. Another approach might involve using one of the text-to-XML converters ( 6.2.1 ) to produce mixed content from structured text entered in an XForms textarea . [18] One such proposed extension is described at www.dubinko. info /writing/htmlarea. The InfoPath forms editor, which does not use XForms, is one that is capable of handling mixed content, as long as it conforms to XHTML. 6.1.4 Word processor editing If filling out forms is the fastest and most natural way to author database-like XML, then for freeform XML it is the word processor interface that is most familiar to users. Editing XML with the convenience of a word processorand yet producing valid and sensibly structured XML documentsis one of the main directions of development in today's XML authoring tools. Syntax formatting. At first sight, word processor display is in direct opposition to XML editing: The former is largely about appearance, while the latter is strictly about content. However, undiluted abstractions rarely work entirely as intended. The ubiquity of syntax coloring in all sorts of text editors is a clear indication that appearance does matter even when you deal with purely abstract structures, because it helps a human reader parse and navigate those structures. From this viewpoint, word-processor-like XML editing is nothing but "syntax coloring on steroids"or "syntax formatting" if you wish. Of course, to be applicable to the highly regular XML, the appearance aspect of a document must itself be regular and consistent. Unattached bits of "formatting for formatting's sake" are inadmissible. Do we have a robust technology that would allow us to assign rich formatting properties to XML elements without changing the XML document itself in any way? Yes, we doit's called CSS. [19] [19] www.w3.org/TR/REC-CSS2 Cascading Style Sheets. Granted, from the design and typography perspective, CSS is less sophisticated than, say, XSL-FO. But we don't need a high level of sophistication for presenting different elements differently. What may be more important is that, unlike XSL-FO which is only good for printed documents, CSS can naturally accommodate various presentation modes, including the screen presentation of information. This paradigmwhereby you edit a nicely formatted CSS-controlled presentation of your document and get valid semantic XML as a resultis adopted by many XML editors these days. It has its limitations, though. Memory for faces and memory for names. The most important limitation is that the number of different formatting styles that you can reliably remember and recognize is usually much less than the number of element type names you can memorize and apply. That is, names attached to markup constructs are easier to remember for many people, even though visual formatting styles may look sexier. When creating markup, you can make use of guided editingfor example, by choosing from a list of markup constructs valid at the current point (such lists may display the names of constructs, or the corresponding formatting samples, or both). However, when editing existing markup, you will often find it difficult to guess what element you are in, judging solely by the formatting style at the cursor. Certainly, distinguishing a heading from a paragraph of text is easy. But some widely used vocabularies, such as DocBook, contain hundreds of element types. Assigning a recognizable set of visual properties to each element type may therefore be difficult if not impossible . As a response to this problem, many word processor XML editors can optionally display element tags without removing CSS formatting. The tags are usually rendered as icons. You can use them while you are learning a new vocabulary and then switch them off, or you can enable them periodically to remind yourself of the inner workings of your document. The Morphon XML editor is a typical example (Figure 6.5, page 298). What you see is what you pay for. Other limitations of the word processor XML editing paradigm may seem less important, especially for those who have always used traditional word processors for authoring. Yet they are limitations, and you as a developer should be aware of them in advance. -
XML comments are invisible and inaccessible. Consequently, if you want the authors to be able to comment their content, you have to provide a special element type for this (to be ignored or converted into XML comments by the stylesheet). -
Attributes are also invisible, although they can affect presentation of content. For example, element[attr="foo"] in CSS2 selects an element based on its attribute value, much as element[@attr="foo"] matches it in XSLT. An XML editor may of course provide a command to view and modify attribute values for an element, but by the very nature of the word processing approach, this can only be done through a special dialog, and not as a routine editing operation. -
Nesting of elements is not obvious. For example, if I see a green sentence inside an italic paragraph, does that mean that the "green" element is a child of the "italic," or is this two "italic" elements with a "green" one in between? It may be very difficult to combine unambiguously several formatting styles that correspond to several element ancestors of the current text fragment. Despite the "cascading" in "CSS," many editors do not even attempt to visualize nesting in any way, effectively reducing XML to the flat styles of conventional word processors ( 6.2.3.3 ). On the other hand, as we'll see below ( 6.1.5.1 ), it is possible to use the CSS frame and background properties to visualize the hierarchical structure of the top-level elements of a document. 6.1.5 Writing CSS for XML visualization You will need CSS style sheets for visualizing your XML if you want to author your custom-vocabulary XML in a word-processor-like XML editor. But it is also very useful to be able to view your XML documents quickly, without transformation, in an XML/CSS-capable web browser. But we already have a web site? Creating CSS for XML is not much of a graphic design job; the style sheets may have very little in common with the way this same material looks on the web pages after transformation. Our goal is to render source XML in a consistent and visually unambiguous way so it is easy to review and edit. This means the document structure must be expressive and laconic at the same time. HTML text in the XML structure. It may, however, make sense for our CSS style sheet for XML to imitate to some extent the character formatting of the transformed HTML pages. This imitation will let site authors and editors see at once where elements in their XML editor window will end up on the web page. On the other hand, the visualization of document structure cannot and should not be in any way influenced by the layout of the web page, if only because a web page will contain components (such as navigation) that are absent from that page's source XML. 6.1.5.1 Nested boxes Thus, we have to find a clear yet unobtrusive way to use CSS to reflect the hierarchical structure of XML. The Pollo XML editor ( 6.1.2.2 ) suggests the idea of using nested rectangular frames with different visual properties. Indeed, with CSS, you can easily present content blocks as boxes with different border types, specify colors of their borders and backgrounds, and adjust margins for better recognizability. 6.1.5.2 Links and images Compared to XSLT, CSS is very limited when it comes to manipulating data. For instance, you cannot pull information from one place in a document and insert it into another (let alone into a different document). Luckily, we don't need this ability for straightforward XML visualization, especially given that our page documents (Example 3.1, page 141) are so simple. Thus, you cannot create clickable links from abbreviated link addresses ( 3.5.3 ) in your XML because CSS lacks facilities for proper unabbreviation. (A simple XSLT stylesheet can be added to handle thisbut then, why use CSS at all?) But perhaps you don't need the visualized links to be clickable; much more useful for editing is to see the link address in its original abbreviated form. However, you'll still want such a link to stand out from the surrounding text so that its link status is clear. Similarly, CSS cannot be used to fetch images and insert them into the displayed document. [20] Instead, we will simply show the (abbreviated) image references as they are given in the source. Technical validity of both links and image references can be checked by a Schematron schema ( 5.1.3 ); what we are interested in when editing the document is that these references actually make sense , and this is where seeing the original abbreviated addresses can really help. [20] At least not if you use an XML-capable web browser such as Mozilla for displaying XML documents with a CSS style sheet. XML word processors may use special tricks to add this functionality for certain XML vocabularies; for example, Morphon uses special plugins for inserting images referred to from a DocBook document. 6.1.5.3 Example and demonstration A CSS style sheet for visualizing the structure of our sample page documents (such as the one in Example 3.1) is given in Example 6.2. Note that unlike the XHTML+CSS combination, CSS applied to a generic XML document has no default properties associated with any element types. You'll have to define everything explicitly, including the display: block property for block-level constructs such as paragraphs. Example 6.2. A CSS style sheet for visual rendition of an XML page document (see Figure 6.7). page { background-color: white; padding: 5pt; margin: -5pt; } page title { letter-spacing: 0.5em; margin: 5pt; } block { display: block; padding: 10pt; margin: 5pt; border: lightgray 4px solid; } section { display: block; padding: 0pt 10pt 10pt 10pt; margin: 5pt; border: black 2px dashed; } section > head { display: block; background-color: #cccccc; padding: 5pt 10pt 5pt 10pt; margin: 0pt 0pt 0pt -10pt; font-weight: normal; font-size: large; } section > subhead { display: block; background-color: #eeeeee; padding: 5pt 5pt 5pt 1cm; margin: 0pt -10pt 0pt -10pt; font-style: italic; } p { display: block; padding: 5pt; margin: 5pt; border: black 2px dotted; } block[src]:before { content: "[Orthogonal block reference: " attr(src) " ]"; color: gray; font-family: monospace; font-size: small; } section[image]:before { content: "[Image: " attr(image) " ]"; display: block; padding: 3pt; color: gray; font-family: monospace; font-size: small; } int, link[linktype="internal" ] { color: green; border-bottom: 1px solid; } ext, link[linktype="external" ] { color: blue; border-bottom: 1px solid; } int:after, link[linktype="internal"]:after { content: "[int: " attr(link) "]"; color: gray; font-family: monospace; font-size: x-small; } ext:after, link[linktype="external"]:after { content: "[ext: " attr(link) "]"; color: gray; font-family: monospace; font-size: x-small; } em { font-style: italic; } code { font-family: monospace; }
If your CSS visualization is to be used by content authors or site maintainers, it makes sense to create a "legend" XML document that uses all of your source XML vocabulary and explains the formatting conventions of the CSS visualization. A browser screenshot of such a sample document is shown in Figure 6.7. Figure 6.7. A "legend" XML document using most of the element types defined for the page documents, rendered by Mozilla with the CSS style sheet from Example 6.2. 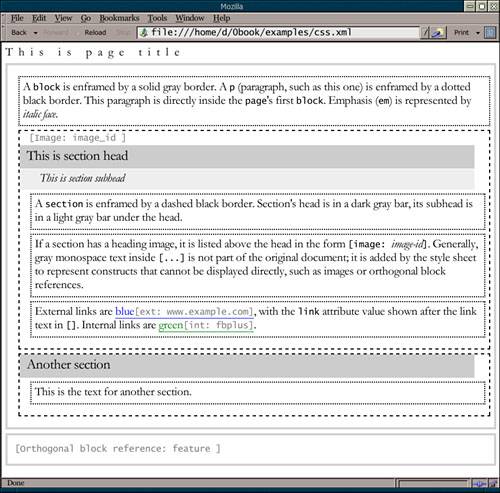
 |