1.1 Content, presentation, structure If you ask around, "What is the main problem that XML is supposed to solve?" of those who can answer this question most people will probably speak about "separating content from presentation." This is correct, but invites another interesting question: How come this is a problem at all? Was it a problem before XML? Or before computers? Generally, our ability to discern concepts is directly related to our language's ability to tell them apart. Linguists know that primitive languages are often characterized by their inability to express abstract or generalized ideas; such a language may have a single word for a "high wind" while lacking more general words for "just wind" or "just high." We can therefore be sure that the idea of style as something separate from content could not have appeared before the first written document was authored . And for a long time, such separation didn't offer anything useful for practical handling of documents, remaining a purely philosophical speculation. Thus, publishers have long used "tags" to mark up authors' manuscripts for typesetting, but these tags did not tell the typesetter what each fragment of text is , only what font face to use for itwhich means that style and content were always commingled. Computer as a language. All this changed with the advent of computers. A computer can be compared to a well-developed human language; both are created by humans (even though the latter is much less "artificial" than the former), and both can represent and communicate any type of information by using special notations. Not surprisingly, very early in the history of computerized document processing, the idea of separating presentation from content was conceived. As far back as 1969, the Generalized Markup Language (GML) was created at IBM out of the necessity to store and process different kinds of documents in order to integrate multiple applications in a mainframe-based publishing system. The language was later standardized by ISO as SGML (Standard Generalized Markup Language). Starting in 1996, a simplified and streamlined version of SGML called XML [1] has been developed by the W3C. [1] www.w3.org/XML It thus became possible (and necessary!) to imagine the different aspects of a document apart only because computers made it possible to say them discernibly. A computer is a tool not only for expressing ideas, but alsoand more importantlyfor setting them to work. That's how computers, probably for the first time in history, made philosophy an applied science. 1.1.1 The stairway of abstractions The word "abstraction" may sound vague, but it is an important and very practical concept. When you are developing and later applying an XML markup vocabulary, what you are doing is exactly this abstracting out various aspects of the document and tagging them as you go. Let's look at this process in detail. There are many different ways in which a document could be represented in the computer. It is natural to order all these representations in such a way that a next one can be obtained from the previous, but not vice versa, in a completely automatic and reliable fashion. [2] [2] In fact, any such conversion will still include certain manual components . An accurate definition of a "completely automatic conversion" would be, "A conversion where the amount of manual work does not depend on the size of the document being converted." For example, a TEX document can be translated into PostScript automatically. This works for all correct TEX documents and, once you've tested the conversion on a few samples, can be run unattended. A reverse conversion, however, is not doable with standard tools. You can try to automate some components of this backward conversion, but it will always require manual checks and fixes, and will always be unreliable and not universal. We will therefore say that a TEX document is at a higher level of abstraction than a PostScript document. Similarly, PostScript is higher than a bitmap representation of the same document (e.g., a JPEG image of the page), [3] while TEX is lower than LATEX. If two representations can be automatically converted both ways, they are said to be at the same level of abstraction. [3] A bitmap is an abstraction too, even though a very low-level one. There are no pixels on paper, so we had to abstract them when representing a paper page in the computer. 1.1.2 Document oppositions All computerized document formats thus make a giant stairway of abstractions that stretches all the way from least to most abstract representations. Your work as a document engineer consists of building the most abstract representation appropriate for your documents and programming the most flexible, robust, and fast descents to the target low-abstraction representations. Going up the stairway is highly unnatural and must be avoided if at all possible. To help you get a coherent picture of this stairway of abstractions, here are the most important oppositions that characterize documents at its different steps: -
Convertibility. By definition, the higher a document is on the abstractions stairway, the wider is the choice of other formats it can be converted into by moving downward. The formats at the bottom are thus dead ends only suitable for direct perusal; those at the top are best for authoring, storage, exchange, and analysis. -
Style separation. The amount of "in-place" style information that is embedded into the document to control its presentation decreases as you ascend the stairway. -
Low-level representations (e.g., bitmap images or PostScript) specify exactly each tiny detail of a page, and you cannot separate what is being said from how it is being said. Even exporting a document into the style-less plain text format is often not trivial. -
Mid-level representations (e.g., HTML) simplify and generalize style information into instructions that need to be interpreted to yield a page image. Sometimes, style information is separated from the document itself (e.g., into a CSS style sheet), and in most cases, you can reliably export the document into plain text. -
Finally, high-level abstractions do away with style altogether. Such documents are not for viewing at all, and even before you can attach any style to them, they usually must undergo some transformation and/or aggregation. An example of a high-level document representation is semantic XML the sort of XML markup that we will develop in this book for source documents of a web site. Semantic means "related to the meaning" or, in our terms, "content-only and style-less." Actually, being semantic is only one of the properties of a website's XML source, but it is the most important one. In practice, the line between style and content is not always easy to draw. The definition of the abstractions stairway, however, gives you a simple key: If you can derive some of the document's information automatically (based on the rest of the document or on external data such as a style sheet), then this information is style, not content. Numbers in numbered headings give an example of such a "seemingly content but actually style" bit of a document. -
Richness of structure. Documents steadily become more varied in structure as you ascend the stairway. Low-level representations use long rows of elements belonging to a handful of types, while high-level ones may have a huge variety of possible element types but only a few element instances per document. Thus, a bitmap image has only one "element type," pixel; PostScript has dozens of primitives; a high-level semantic XML vocabulary such as DocBook may have hundreds of element types. -
Modularity. Low-level representations tend to be monolithicusually one big file includes all the text, images, styles, fonts, and everything else. High-level representations are more often modular, with components of a document residing in separate files and (explicitly or implicitly) linked from some "root" document that often contains only the textual part of the document content. -
As a direct consequence of the previous points, size of documents decreases as the level of abstraction increases . After all, the very idea of abstraction is reducing the real-world variety to a few generic principlesand of course, these principles don't need as much storage space as the real thing. Bitmap representations are the largest; PostScript files may be quite sizeable too; the top of the line, semantic XML, is usually the smallest representation of a document. 1.1.3 The role of XML It is important to understand that by itself, XML is not an abstraction; it is just a notation for structured data . Since all computer data, including document representations, is structured, in principle XML can be successfully used on any step of the stairway. In other words, XML does not necessarily have to be semantic. Indeed, it is possible to devise , for example, an XML-based bitmap format where each pixel is represented by an XML element. Another example of a nonsemantic XML vocabulary is XSL-FO ( 5.5.3.2 ). However, any such formats tend to be awkward and bulky, [4] which suggests that the true usefulness of XML is on the higher steps of the stairway. [4] This book's chapters in XSL-FO are slightly larger than in PDF, even though PDF is at a lower level of abstraction. Remember that XML is -
human-readable : this is more important for the higher steps of the stairway, as documents there are more often authored by humans; -
arbitrarily rich: you can easily create vocabularies of any breadth and depth, which, again, is more important for abstract document representations; -
rather bulky: [5] this may be a disadvantage for low-abstraction formats, as they are more often processed automatically and are therefore more efficiency-sensitive. [5] One of the XML design goals states, "Terseness in XML markup is of minimal importance." This book is not about XML or XSLT for their own sakes; it is about building highly abstracted semantic representations of web site documents and programming their transformation into a lower-level browser-viewable representation. We just use XML and XSLT as very convenient tools for these jobs. 1.1.4 The role of HTML As for the target representation that we are interested in, it is not something we have much choice about. The only format that is reliably displayed by all modern browsers and is sufficiently rich for the interface of modern web sites is HTML. What you can and cannot do with HTML. HTML is a mid-level document format. It can implement a very simple semantic markup (with external CSS style sheets) and is sufficiently compact to be sent over the network. It is also partially modular in that images and some other types of objects are stored separately and referenced from within HTML code. On the other hand, HTML is not suitable for richly structured documents, since its vocabulary of element types is limited and not extensible. Its modularity is also limited: It can only factor out non-HTML data, but there's no easy mechanism to break into parts and reassemble an HTML document itself (other than by using an external scripting layer). Besides, the amount of control over presentation offered by the latest version of CSS alone is hardly sufficient for practical web site interfaces. As a result, the real-world HTML todaywith its embedded scripts, cross-browser workarounds, layout tables, spacer images, and other presentation-related stuffis quite messy and not at all semantic. Even though originally, HTML was designed as an SGML-based semantic markup language, most web authors and browser creators viewed it as an equivalent of some annoyingly poor and old-fashioned word processor format. HTML was thus forced onto a wrong step of the abstractions stairway, which could not but result in gross misuse and all sorts of structural problems. The advance of CSS has stopped the trend of HTML degradation but has failed to reverse it. This is why a high-level abstract representation, using a semantic XML vocabulary, is such a good ideafor web pages as well as for most other kinds of documents. Authoring and editing is done much more naturally and conveniently in semantic XML; when the source XML documents are ready, they are automatically translated by an XSLT stylesheet into the target format (such as HTML). Figure 1.1 schematically depicts this process, and the rest of the book describes it in detail. Figure 1.1. An XSLT transformation, controlled by a stylesheet, converts an XML source of a page into HTML which is then displayed by the browser. 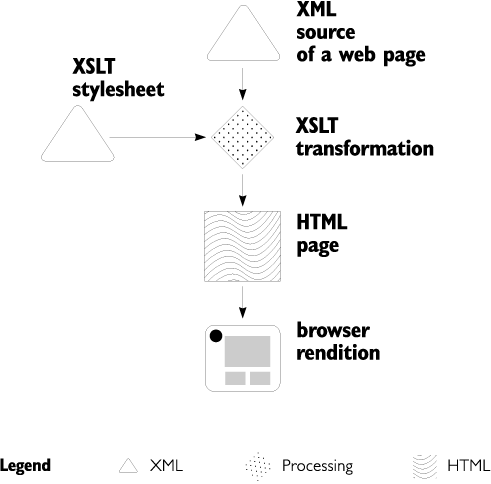
Other target formats. No techniques described in this book cover browser-specific HTML. You know what I'm speaking about: one version for MSIE, another for Netscape ... luckily, you can now leave this ugly stuff behind forever (unless you target some very old or very weird browsers). Instead, if you are willing to sacrifice universal accessibility for something else (presumably more important to you), you can write an XSLT stylesheet to generate almost any other document format in place of HTML: WML, PDF, SVG, even RTF or Flash. While generating binary formats requires using some additional software ( 5.5.2 ), at the XSLT side of things, nothing really changes as compared to generating HTML. Visualizing XML. Still another way to present a document to the user is by transforming it from the semantic source XML into another, more low-level XML vocabulary reflecting the visual structure of the web page. This low-level XML can then be viewed by an XML-capable browser using an external CSS style sheet (Figure 1.2). The advantage of this method is that the presentation-oriented XML may be more elegant and more useful than the equivalent HTML; the big disadvantage is, of course, the need for the software at the user end to support the XML+CSS combination ( 1.4.3 ). Another problem is the limited capabilities of CSS ( 6.1.5 , page 312) that make this scheme suitable only for simple documents. Figure 1.2. A variation of Figure 1.1: Instead of HTML, a combination of presentation-oriented XML and a CSS style sheet renders the page in a browser. 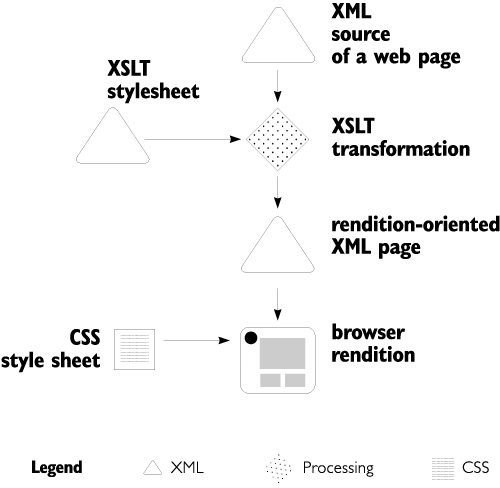
1.1.5 The Semantic Web The level of abstraction attainable with web pages or any other Internet resources cannot be higher than that of the document format they use, which is most often HTML. This makes today's Web predominantly visual ; you can easily (and even automatically) obtain a visible image of any web page, but you cannot extract and codify what it means to say unless you, or someone you hire, reads and analyzes it. In a Semantic Web , [6] by contrast, all resources have an easily accessible and consistently expressed semantic aspect. Today, you can read a web page and extract its meaning, but your computer cannot; in a Semantic Web, computers will be able to effectively "understand" resources and do various meaningful things with them (such as intelligent search, comparison, aggregation, compiling digests, etc.). [6] The term was coined by Tim Berners-Lee, the inventor of the World Wide Web. The vision of the Semantic Web was a driving force behind the initiative to simplify and promote the use of SGML on the Web, which in 1996 resulted in launching of the XML project by the W3C. Today, the Semantic Web is one of the activities [7] of the W3C centered around the language called RDF (Resource Description Framework). [8] [7] www.w3.org/2001/sw [8] www.w3.org/RDF The Extensible Meaning Language. XML is a metalanguage that allows you to describe the structure of documents but is agnostic about their meaning . This is understandable, since it is hard to imagine a formalism that would be able to express any possible kind of meaning in a form accessible to modern computers. [9] Some aspects of meaning, however, can be formalized which is where RDF comes into play. [9] Without AI, that is.
An RDF statement ( triple ) connects some resource ( subject ), one of its properties ( predicate ), and the value of that property ( object ). Each of these three components can be identified by a URI. A triple is thus equivalent to a natural language sentence (such as Bob loves Mary , where Bob is the subject, loves is the predicate, and Mary is the object) and can therefore express meaningsprovided the "words" it uses have some meanings to begin with. Just as XML is the base of a great many languages that use it to describe various data structures, there exist languages that use the RDF formalism to define various semantic areas ( ontologies ). For example, the FOAF (Friend Of A Friend) standard [10] defines terms, properties, and relationships that can be used to build an RDF description covering all aspects of a person (such as the person's name , nickname, email address, depiction, and even a DNA checksum). [10] www.xmlns.com/foaf/0.1  |