Move Creation Knowledge to Factory Data and code used to instantiate a class is sprawled across numerous classes.
Move the creation knowledge into a single Factory class.
Motivation When the knowledge for creating an object is spread out across numerous classes, you have creation sprawl: the placement of creational responsibilities in classes that ought not to be playing any role in an object's creation. Creation sprawl, which is a case of the Solution Sprawl smell (43), tends to result from an earlier design problem. For example, a client needed to configure an object based on some preferences yet lacked access to the object's creation code. If the client can't easily access the object's creation code, say, because it exists in a system layer far removed from the client, how can the client configure the object? A typical answer is by using brute force. The client passes its configuration preferences to one object, which hands them off to another object, which holds onto them until the creation code, by means of still more objects, obtains the information for use in configuring the object. While this works, it spreads creation code and data far and wide. The Factory pattern is helpful in this context. It uses one class to encapsulate both creation logic and a client's instantiation/configuration preferences. A client can tell a Factory instance how to instantiate/configure an object, and then the same Factory instance may be used at runtime to perform the instantiation/configuration. For example, a NodeFactory creates StringNode instances and may be configured by clients to embellish those instances with a DecodingStringNode Decorator:  A Factory need not be implemented exclusively by a concrete class. You can use an interface to define a Factory and make an existing class implement that interface. This approach is useful when you want other areas of a system to communicate with an instance of the existing class exclusively through its Factory interface. If the creation logic inside a Factory becomes too complex, perhaps due to supporting too many creation options, it may make sense to evolve it into an Abstract Factory [DP]. Once that's done, clients can configure a system to use a particular ConcreteFactory (i.e., a concrete implementation of an Abstract Factory) or let the system use a default ConcreteFactory. While the above NodeFactory is certainly not complicated enough to merit such an evolution, the diagram on the next page shows what it would look like as an Abstract Factory. 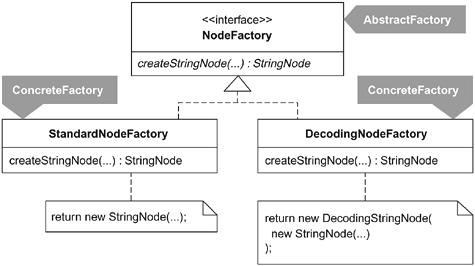 What Is a Factory? "Factory" is one of the most overused and imprecise words in our industry. Some use the term "Factory pattern" to refer to a Factory Method [DP], some use the term to refer to an Abstract Factory [DP], some use the term to refer to both patterns, and some use the term to refer to any code that creates objects. Our lack of a commonly understood definition of "Factory" limits our ability to know when a design could benefit from a Factory. So I'll offer my definition, which is both broad and bounded: A class that implements one or more Creation Methods is a Factory. This is true if the Creation Methods are static or nonstatic; if the return type of the Creation Methods is an interface, abstract class, or concrete class; or if the class that implements the Creation Methods also implements noncreational responsibilities. A Factory Method [DP] is a nonstatic method that returns a base class or interface type and that is implemented in a hierarchy to enable polymorphic creation (see Introduce Polymorphic Creation with Factory Method, 88). A Factory Method must be defined/implemented by a class and one or more subclasses of the class. The class and subclasses each act as Factories. However, we don't say that a Factory Method is a Factory. An Abstract Factory is "an interface for creating families of related or dependent objects without specifying their concrete classes" [DP, 87]. Abstract Factories are designed to be substitutable at runtime, so a system may be configured to use a specific, concrete implementor of an Abstract Factory. Every Abstract Factory is a Factory, though not every Factory is an Abstract Factory. Classes that are Factories, not Abstract Factories, sometimes evolve into Abstract Factories when a need arises to support the creation of several families of related or dependent objects. The next diagram, which uses bold lines to designate methods that create objects, illustrates common differences between sample Factory Method, Factory, and Abstract Factory structures. 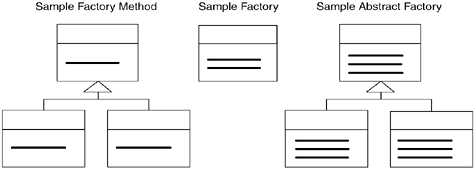 |
I've seen numerous systems in which the Factory pattern was overused. For example, if every object in a system is created by using a Factory, instead of direct instantiation (e.g., new StringNode(…)),the system probably has an overabundance of Factories. Overusing this pattern often occurs when people always decouple client code from code that chooses between which classes to instantiate or how to instantiate them. For example, the following createQuery() method makes a choice about which of two query classes to instantiate: public class Query... public void createQuery() throws QueryException... if (usingSDVersion52()) { query = new QuerySD52(); ... } else { query = new QuerySD51(); ... }
To eliminate the conditional logic in the above code, some would refactor it to use a QueryFactory: public class Query... public void createQuery() throws QueryException... query = queryFactory.createQuery(); ...
QueryFactory now encapsulates the choice of what concrete query class to instantiate. Yet does QueryFactory improve the design of this code? It certainly doesn't consolidate creation sprawl, and if it only decouples the Query class from the code that instantiates one of the two concrete queries, it most definitely does not add enough value to merit its existence. This illustrates the point that it's best not to implement a Factory unless it really improves the design of your code or enables you to create/configure objects in a way that wasn't possible with direct instantiation. Benefits and Liabilities | + | Consolidates creation logic and instantiation/configuration preferences. | | + | Decouples a client from creation logic. | | – | Complicates a design when direct instantiation would do. |
|
Mechanics These mechanics assume your Factory will be implemented as a class, rather than as an interface implemented by a class. If you need a Factory interface that is implemented by a class, you must make minor modifications to these mechanics. - 1. An instantiator is a class that collaborates with other classes to instantiate a product (i.e., an instance of some class). If the instantiator doesn't instantiate the product using a Creation Method, modify it and, if necessary, also modify the product's class, so the instantiation occurs through a Creation Method.
- 2. Create a new class that will become your factory. Name your factory based on what it creates (e.g., NodeFactory, LoanFactory).
- 3. Apply Move Method [F] to move the Creation Method to the factory. If the Creation Method is static, you can make it nonstatic after moving it to the factory.
- 4. Update the instantiator to instantiate the factory and call the factory to obtain an instance of the class.
Repeat this step for any instantiators that could no longer compile because of changes made during step 3.
- 5. Data and methods from the other classes are still being used in the instantiation. Move whatever makes sense into the factory, so it handles as much of the creation work as possible. This may involve moving where the factory gets instantiated and who instantiates it.
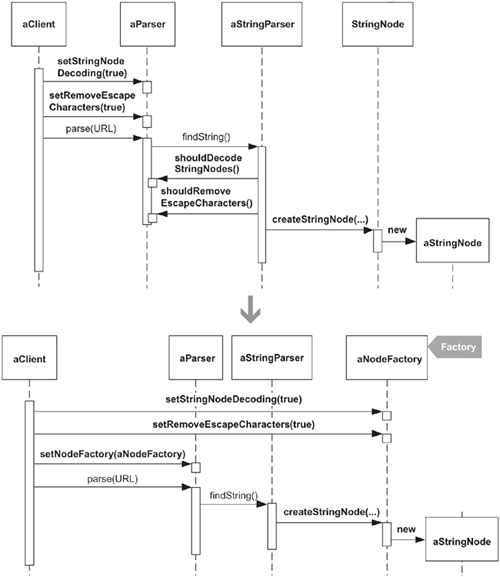
Example This example comes from the HTML Parser project. As described in Move Embellishment to Decorator (144), a user of the parser can instruct it to handle string parsing in different ways. If a user doesn't want parsed strings to contain encoded characters, like & (which represents an ampersand, &) or < (which represents an opening angle bracket, <), the user can call the parser's setStringNodeDecoding(shouldDecode: boolean) method, which turns the string decoding option on or off. As the sketch at the beginning of this Move Creation Knowledge to Factory refactoring illustrates, the parser's StringParser actually creates StringNode objects, and when it does so, it configures them to decode or not decode, based on the value of the decoding field in Parser. While this code worked, StringNode creation knowledge was now spread across the Parser, StringParser, and StringNode classes. This problem worsened as new string parsing options were added to the Parser. Each new option required the creation of a new Parser field with corresponding getters and setters, as well as new code in the StringParser and StringNode to handle the new option. The boldface code in the diagram on the following page illustrates some of the changes made to classes that resulted from adding an escape character (e.g., \n or \r) removal option. 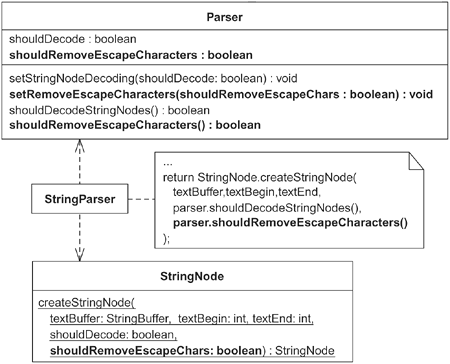 The fields, getters, and setters that were added to Parser to support different parsing options for StringNodes didn't belong on the Parser class. Why? Because Parser has the responsibility of kicking off a parsing session, not controlling how StringNodes (which represent just one of numerous Node and Tag types) ought to be parsed. In addition, the StringNode class also had no good reason to know anything about decoding or escape character removal options, which have already been modeled using the Decorator pattern (see the example for Move Embellishment to Decorator, 144). Based on my earlier definition, we can say that StringNode is already a Factory because it implements a Creation Method. The trouble is, StringNode isn't helping consolidate all knowledge used in instantiating/configuring a StringNode, nor do we actually want it to because it is better to keep StringNode small and simple. A new Factory class will be better able to consolidate the instantiation/configuration, so I will refactor to one. For simplicity, the following code includes only one parsing option—the one for decoding nodes—and doesn't include the option for escape character removal. - 1. StringParser instantiates StringNode objects. The first step in this Move Creation Knowledge to Factory refactoring is to make StringParser perform its instantiation of StringNode objects by using a Creation Method. It already does this, as the following code shows.
public class StringParser... public Node find(...) { ... return StringNode.createStringNode( textBuffer, textBegin, textEnd, parser.shouldDecodeNodes() ); } public class StringNode... public static Node createStringNode( StringBuffer textBuffer, int textBegin, int textEnd, boolean shouldDecode) { if (shouldDecode) return new DecodingStringNode( new StringNode(textBuffer, textBegin, textEnd) ); return new StringNode(textBuffer, textBegin, textEnd); }
- 2. Now I create a new class that will become a factory for StringNode objects. Because a StringNode is a type of Node, I name the class NodeFactory:
public class NodeFactory { }
- 3. Next, I apply Move Method [F] to move StringNode's Creation Method to NodeFactory. I decide to make the moved method nonstatic because I don't want client code statically bound to one Factory implementation. I also decide to delete the Creation Method in StringNode:
public class NodeFactory { public static Node createStringNode( StringBuffer textBuffer, int textBegin, int textEnd, boolean shouldDecode) { if (shouldDecode) return new DecodingStringNode( new StringNode(textBuffer, textBegin, textEnd)); return new StringNode(textBuffer, textBegin, textEnd); } } public class StringNode... public static Node createStringNode(... }
After this step, StringParser and other clients that used to call the StringNode's Creation Method no longer compile. I'll fix that next.
- 4. Now I modify the StringParser to instantiate a NodeFactory and call it to create a StringNode:
public class StringParser... public Node find(...) { ... NodeFactory nodeFactory = new NodeFactory(); return nodeFactory.createStringNode( textBuffer, textBegin, textEnd, parser.shouldDecodeNodes() ); }
I perform a similar step for any other clients that no longer compile because of work done in step 3.
- 5. Now comes the fun part: eliminating or reducing creation sprawl by moving the appropriate creation code from other classes into the NodeFactory. In this case the other class is the Parser, which the StringParser calls to pass an argument to the NodeFactory during StringNode creation:
public class StringParser... public Node find(...) { ... NodeFactory nodeFactory = new NodeFactory(); return nodeFactory.createStringNode( textBuffer, textBegin, textEnd, parser.shouldDecodeNodes() ); }
I'd like to move the following Parser code to the NodeFactory:
public class Parser... private boolean shouldDecodeNodes = false; public void setNodeDecoding(boolean shouldDecodeNodes) { this.shouldDecodeNodes = shouldDecodeNodes; } public boolean shouldDecodeNodes() { return shouldDecodeNodes; }
However, I can't simply move this code into the NodeFactory because clients of this code are clients of the parser, which call Parser methods like setNodeDecoding(…) to configure the parser for a given parse. Meanwhile, NodeFactory is not even visible to parser clients: it is instantiated by StringParser, which itself is not visible to parser clients. This leads me to conclude that the NodeFactory instance must be accessible to both Parser clients and the StringParser. To make that happen, I take the following steps.
- a. I first apply Extract Class [F] on the Parser code I want to eventually merge with the NodeFactory. This leads to the creation of the String-NodeParsingOption class:
public class StringNodeParsingOption { private boolean decodeStringNodes; public boolean shouldDecodeStringNodes() { return decodeStringNodes; } public void setDecodeStringNodes(boolean decodeStringNodes) { this.decodeStringNodes = decodeStringNodes; } }
This new class replaces the shouldDecodeNodes field, getter, and setter with a StringNodeParsingOption field and its getter and setter:
public class Parser.... private StringNodeParsingOption stringNodeParsingOption = new StringNodeParsingOption(); private boolean shouldDecodeNodes = false; public void setNodeDecoding(boolean shouldDecodeNodes) { this.shouldDecodeNodes = shouldDecodeNodes; } public boolean shouldDecodeNodes() { return shouldDecodeNodes; } public StringNodeParsingOption getStringNodeParsingOption() { return stringNodeParsingOption; } public void setStringNodeParsingOption(StringNodeParsingOption option) { stringNodeParsingOption = option; }
Parser clients now turn StringNode decoding on by instantiating and configuring a StringNodeParsingOption instance and passing it to the parser:
class DecodingNodeTest... public void testDecodeAmpersand() { ... StringNodeParsingOption decodeNodes = new StringNodeParsingOption(); decodeNodes.setDecodeStringNodes(true); parser. setStringNodeParsingOption(decodeNodes); parser.setNodeDecoding(true); ... }
The StringParser now obtains the state of the StringNode decoding option by means of the new class:
public class StringParser... ... public Node find(...) { NodeFactory nodeFactory = new NodeFactory(); return nodeFactory.createStringNode( textBuffer, textBegin, textEnd, parser. getStringNodeParsingOption().shouldDecodeStringNodes() ); }
- b. Now I apply Inline Class [F] to merge NodeFactory with StringNodeParsing-Option. This leads to the following changes in StringParser:
public class StringParser... public Node find(...) { ... return parser. getStringNodeParsingOption().createStringNode( textBuffer, textBegin, textEnd , parser.getStringNodeParsingOption().shouldDecodeStringNodes() ); }
And the following changes in StringNodeParsingOption:
public class StringNodeParsingOption... private boolean decodeStringNodes; public Node createStringNode( StringBuffer textBuffer, int textBegin, int textEnd , boolean shouldDecode) { if (decodeStringNodes) return new DecodingStringNode( new StringNode(textBuffer, textBegin, textEnd)); return new StringNode(textBuffer, textBegin, textEnd); } }
- c. The final step is to rename the class StringNodeParsingOption to NodeFactory and then perform a similar renaming on the NodeFactory field, getter, and setter in Parser:
public class StringNodeParsingOption NodeFactory... public class Parser... private NodeFactory nodeFactory = new NodeFactory(); public NodeFactory getNodeFactory() { return nodeFactory; } public void setNodeFactory(NodeFactory nodeFactory) { this.nodeFactory = nodeFactory; }
And that does it. NodeFactory has helped tame creation sprawl by handling the work associated with instantiating and configuring StringNode objects. |