2.3 Name-to-address mapping
|
|
2.3 Name-to-address mapping
Most people have difficulty remembering numbers, so a user-friendly scheme is often required for real networks, where names are used to refer to computer systems, networking devices, and services. In essence there are two basic ways to use names on a network, as follows:
-
By static mapping tables associating addresses with names, such as the /etc/hosts file under UNIX.
-
By using a dynamic name resolution system, such as the Domain Name Service (DNS).
Another key advantage of mapping names to addresses is that there is another layer of abstraction between users and resources. This enables hosts and network devices to be swapped out or modified without affecting users or services. For example, a file server is installed called BigDisk, and is mapped to 192.162.35.5. Subsequently this host is reassigned to other duties (perhaps because a host supporting a disk array is subsequently installed). The new host could be located on a different subnet and simply mapped to the name BigDisk without the user ever knowing.
In this section we discuss naming techniques and services used to complement the network design. Note that advanced applications such as load balancing and performance optimization of these services are covered in reference [4].
2.3.1 Static name service: The hosts file
The simplest method of mapping names to addresses can be achieved using a simple text lookup file, held locally on each device. On many operating systems this file is referred to as the hosts file. Under UNIX, for example, this function is typically implemented as /etc/hosts. In /etc/hosts each line of the file has the IP address (in dotted-decimal notation) on the left and the associated text name, and possible aliases, on the right. Note that the semicolon (;) is used for comments. For example:
; hosts file ; IP address name alias ; 127.0.0.0 Lookback me myself 140.45.4.6 HomeServer mainman bigcheese 140.45.5.1 AccessRouter1 Wanman 192.168.76.1 MainRouter fatboy slim 193.145.8.2 Big.name.com fiction
Using this example, a user might, for example, Telnet to 140.45.4.6, HomeServer, mainman, or bigcheese with the same result. This approach is very simple, and can be relatively easy to deploy on small networks (e.g., a LAN with less than 100 hosts). In order to ensure a consistent naming system the hosts file simply needs to be copied to all other hosts on the network. In fact, this method was used on the original ARPANET; the Network Information Center (NIC) administered a single file (hosts.txt), which was retrieved using FTP by all attached hosts. The problem is that this method simply does not scale. Other problems include the following:
-
Hierarchy—The first problem with this scheme is the lack of hierarchy. As with any large problem, it is often necessary to break it down into manageable pieces, and here we have an essentially flat name space.
-
Uniqueness—While the network administrator can guarantee unique names in the hosts file, there is no way to stop local users adding host names themselves, resulting in the possibility of name collisions (multiple hosts with the same name). Duplicated names will result in connectivity problems and are also difficult to troubleshoot.
-
Maintenance—Moves and changes need to be reflected in all files. On a large network there is no easy way to synchronize host files across the network. The network administrator could keep a master file and ensure synchronization either through batch downloads or by insisting that users download this file regularly, but this is neither dynamic nor reliable and may not be secure or even practical in a large network. Maintenance can become a major headache.
-
Security—There is no inherent way to protect against either accidental misconfigurations or malicious misconfigurations. There is plenty of scope for denial-of-service attacks or host intrusion.
-
Load—As the network grows, the service demands placed on the central host system can become intolerable. The load placed on the network also becomes a major problem.
To overcome these problems a hierarchical distributed database is required, together with dynamic name synchronization and name query mechanisms. In November 1983 such a system was proposed in RFC 882 and RFC 883 (now both obsolete); this system is called the Domain Name Service (DNS).
2.3.2 Domain Name System (DNS)
The Domain Name System (DNS) comprises a client/server protocol together with a distributed database that holds name-to-IP-address mappings. The DNS is accessed by IP applications to dynamically discover address-name bindings and e-mail routing information. To promote scalability and better performance, the administration of parts of the database is devolved locally. Each site (e.g., campus, company, or department) typically maintains its own database for the local domain and runs a server program that other DNS servers can query over an IP network. The DNS is a large topic, and a complete discussion is outside the scope of this book. Here we will briefly review its operation and discuss the pertinent issues for network design and performance analysis. For more detailed information, the interested reader is referred to [28, 31–34]. DNS extensions to support IPv6 are specified in [35].
Before we discuss DNS operations we first need to understand the structure and implementation of domain names.
Domain names
The DNS structure contains a hierarchy of names, not unlike the UNIX file system in organization. The highest level, or root, of the DNS is unnamed (null). Each node in the tree represents a domain, which is a segment of the overall name database. Domains are broken up into subdomains (note that domains are an entirely separate concept from networks: domains are a higher administrative abstraction that can span many networks and subnetworks, transparent to the end user). Immediately below the root node are a number of Top-Level Domains (TLDs), as illustrated in Figure 2.11. TLDs are designed for the following applications:
-
COM—a worldwide generic domain used by commercial organizations. This domain has grown very large due to explosive demand from businesses for the .COM label.
-
EDU—a worldwide generic domain used by educational organizations. Many universities, colleges, schools, and educational service organizations have registered here, although outside the United States such organizations are often registered under the country code.
-
NET—a worldwide generic domain used by major network providers and network support centers.
-
INT—a worldwide generic domain used by international organizations.
-
GOV—a domain used by government organizations in the United States.
-
MIL—used by the U.S. military.
-
ORG—a worldwide generic domain used by nonprofit organizations that do not fit into any other category.
-
<CountryCode>—used for geographical-based domains (two-character domains based on country codes).
-
ARPA—a special domain, originally used for ARPANET migration but now used for name-to-address resolution via the subdomain in-addr.
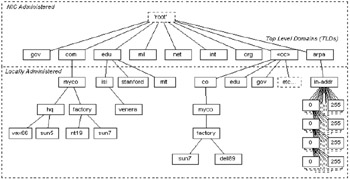
Figure 2.11: Domain hierarchy.
The <CountryCode> top-level node can be used to enforce a geographic naming model and is reserved for country codes (originally this was supposed to be the international telephone dial code, but this has been superseded by a two-letter abbreviation, as defined in ISO 3166). Most U.S. organizations have elected to use the flat organizational approach (illustrated in Figure 2.11 under myco.com), while many non-U.S. organizations use the geographic approach (attaching via the country code node). For example, a server in the United Kingdom with IP address 167.142.10.2 could be referenced by the domain name dell89.factory.myco.co.uk. Within a particular domain it is sufficient to use only enough detail to uniquely identify the device in that domain; the higher-level domain information is automatically appended by the software responsible for sending the DNS request. Note that in Figure 2.11 there are seven generic Top-Level domains (TLDs), together with the Country Code (CC) domain and a special ARPA TLD. In some countries, such as the United Kingdom, .COM is abbreviated to .CO, and .EDU is referenced as .AC.
Domain name format
Domain names comprise a series of dot-delimited labels, in reverse order. Every node within the tree must have a unique domain name, but the same label can be used at different points in the tree (e.g., twin.uni.edu and twin.mother.uni.edu are both unique). Although the root node is unnamed, Fully Qualified Domain Names (FQDNs) should end with a dot (.) to signify the root, (e.g., solaris.mydomain.com.). In practice this is rarely done, since it is universally assumed that DNS implementations automatically append the dot. Note that within the tree hierarchy domain names cannot be distinguished from object names (i.e., there is no obvious way to tell if obviouslyahost.cs.noname.edu. is really a host or a subdomain).
To simplify implementations, the total length of a domain name (including label bytes and label length bytes) is restricted to 255 bytes or less. Within DNS Resource Records (RR), each label is represented as a one-byte length field, followed by the specified number of bytes. Since the root node uses a null label, all domain names are terminated by a length byte of zero. The most significant two bits of every length field must be 00; hence, the remaining six bits limit the label length to 63 bytes or less. DNS supports a feature called message compression [34] to conserve space, based on the fact that there is often repetition in name lists. When the most significant two bits of the length byte are 2, the length is interpreted as a two-byte sequence, denoting an offset from the beginning of the message (i.e., the Type field).
Domain name registration
Domain names are administered by the IANA (see [6]). Most TLDs have been delegated to individual country managers, whose codes are assigned from ISO 3166-1. These are referred to as country-code Top-Level Domains (ccTLDs). In addition, there are a small number of generic Top-Level Domains (gTLDs), which do not have a geographic or country designation. Responsibility for procedures and policies for the assignment of Second-Level Domain Names (SLDs) and lower-level hierarchies of names has been delegated to TLD managers. Country-code domains are each organized by a manager for that country. Reference [36] provides information about the structure of the names in the DNS and on the administration of domains. A list of current TLD assignments and names of the delegated managers can be found in [37].
DNS components
DNS runs over UDP or TCP, using port 53 in both cases (UDP is the norm; TCP is used for database transfers). DNS is a client/server application and comprises the following components:
-
The Domain Name Space (described earlier)
-
The distributed database, stored as Resource Records (RR)
-
Name servers
-
Name resolvers
Instead of using static mapping files, DNS relies upon the dynamic interaction of two software components: a name resolver and a name server. DNS also implements a distributed database comprising a set of Resource Records (RR) held on each node in a hierarchical tree structure. Note that on many host systems the utility nslookup is available for debugging and checking the status of DNS.
The Domain Name Space (DNS) and Resource Records (RR)
Conceptually, each node and leaf of the domain name space tree names a set of information, and a DNS query attempts to extract specific information from a particular set. A query describes the domain name of interest and specifies the type of resource information required. To implement the DNS distributed database, data structures called Resource Records (RR) are defined for each node in the tree. RRs are divided into classes—for example, IN = Internet, CH = Chaos—with the Internet class being by far the most popular. Many RR types are experimental, and the complete list is defined in [34]. Important examples include the following:
| Mnemonic | Description |
|---|---|
| A | Address |
| PTR | Pointer |
| MX | Mail Exchanger |
| NS | Name Server |
| SOA | Start of Authority |
| HINFO | Host Information |
| CNAME | Canonical Name |
| TXT | Text |
| WKS | Well-Known Services |
Several Internet class RRs are shown in the following example:
ISI.EDU. IN MX 10 VENERA.ISI.EDU. IN MX 10 VAXA.ISI.EDU. VENERA.ISI.EDU. IN A 128.9.0.32 IN A 10.1.0.52 VAXA.ISI.EDU. IN A 10.2.0.27 IN A 128.9.0.33 USC-ISIC.ARPA IN CNAME C.ISI.EDU C.ISI.EDU IN A 10.0.0.52 52.0.0.10.IN-ADDR.ARPA IN PTR c.ISI.EDU
For further information, refer to [33]. Note that a new resource record type called AAAA has been defined for IPv6 addresses [35].
Name servers
Name servers are server programs that hold information about the domain tree's structure and set information. A name server may cache structure or set information about any part of the domain tree, but in general a particular name server has complete information about a subset of the domain space and has pointers to other name servers for additional information from any part of the domain tree. There are two modes of operation for name servers: primary and secondary. The primary domain name server is required to hold a master database of all names and IP addresses for all hosts in that domain. The secondary domain name server has a copy of this database and maintains synchronization with the primary server by copying this database at regular intervals. The secondary server will also respond to DNS requests from hosts, just as the primary server does. The use of multiple servers provides redundancy, and name resolvers should be configured with both the primary and backup addresses. There are two other variations of name servers in common use: A caching server is used to cache frequently used resolutions but does not hold the full database (it is aware of the location of the primary and secondary servers and uses them to resolve queries). A slave server operates similarly to a caching server but can only operate with recursion, using the list of servers specified in its database.
When a request to translate a name to its associated IP address is received by the name server, it performs a database lookup. If the address is not found, it must contact another name server (referred to as an authoritative server). Since each name server cannot possibly know how to contact every other server, each name server must at least know how to contact the root name servers. The root servers know the name and address of each authoritative name server for all the second-level domains.
Within the domain tree hierarchy, name servers control the parts of the tree for which they have complete (referred to as authoritative) information. Authoritative information is organized into units called zones. A zone is a subtree of the DNS comprising a group of connected domain names that are administered separately (as illustrated in Figure 2.12). A name server is said to have authority for one zone or multiple zones. Zones can be automatically distributed to the name servers that provide redundant service for the information in a zone. Each zone typically maintains a separate DNS database. Whenever a new system is installed in a zone, the DNS administrator for that zone must allocate a name and an IP address for the new system and add these details into the name server's database. The DNS requires that each zone be supported by at least two servers (the primary and secondary servers). The primary loads all the information for the zone from persistent storage (e.g., hard disk). When a new host is added to a zone, the administrator adds the appropriate name and addressing information to a file located on the primary name server. The primary name server is then notified to reread its configuration files. Secondary servers query the primary on a regular basis (typically every three hours). If updates to the database are detected, secondary servers retrieve data using what is called a zone transfer.
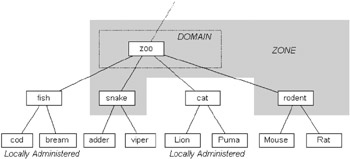
Figure 2.12: Zone relationship with a domain. The zone extends down to all subdomains that are not self-administered.
Name Resolvers
Name resolvers are software programs that query name servers for information in response to client requests. A resolver will typically be a system routine that is directly accessible to user programs; hence, no protocol is necessary between the resolver and the user program. Resolvers must be able to access at least one name server and use that name server's information to answer a query directly or pursue the query using referrals to other name servers. A name resolver is typically installed on an end-user device. End systems that do not implement a name resolver but simply issue DNS queries are called stub resolvers. Here the name resolver is integrated with the name server platform; the stub needs only to maintain a list of name server addresses that will perform the recursive requests on its behalf. In all cases the name server performs the translation by accessing a dynamic database of names and IP addresses.
Operations
In any system that has a distributed database, where many systems have only partial information, a name server may frequently be presented with a query that can be answered only through cooperation with some other server. The two general approaches to dealing with this problem are as follows:
-
Iterative—in which the initial name server refers the client to another server if the information requested is not known. The client is responsible for pursuing the query and may iterate many times until successful.
-
Recursive—in which the initial name server pursues the query on behalf of the client with other servers until the result is passed back to the client. DNS queries contain a bit called Recursion Desired (RD). Name servers should perform recursion only if this bit is set in the request.
Both approaches have advantages and disadvantages. The DNS requires implementation of the simplest approach (iterative) by default but allows the recursive approach as an option. In fact, recursion is the most common mode, since it results in lower load on the client system (since it does not require a resolver and operates as a stub).
Query operation
In Figure 2.13, network devices either implement a resolver (R) or a name server plus a resolver (N+R). Each name server has its own portion of the database to administer and typically implements local cache to improve performance. Most DNS queries are serviced by the local DNS name server within the subdomain. Unresolved queries are redirected to the root name server. In this example a request for a .COM company is unknown locally and so is redirected to the root server, which in turn queries the .COM TLD server. Since the .COM server has the information cached locally, the response is sent back to the root server and forwarded to the originator.
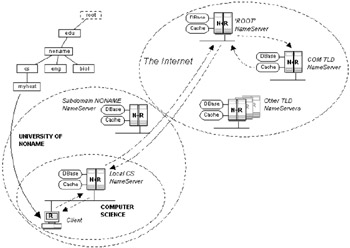
Figure 2.13: DNS operation in a fictitious university campus.
DNS basically operates as follows:
-
Clients query their local name server for address resolution.
-
Name servers respond directly if they are authoritative for the domain in question. If not, then they may examine the local cache. The cache is updated dynamically and queried before firing out requests to other name servers. The cache returns references if found.
-
Name resolution beyond the local name server is top down. If the local server cannot resolve the name, it starts with the root name server, which then recursively queries DNS servers, starting with the TLDs, until it finds a server that can resolve the name.
-
Once the local server has the resolved IP address, it responds to the client and caches these data so that future requests are dealt with locally. In practice the local name server will deal with the majority of queries if caching is available.
Secondary servers check the primary for changes in the zone serial number (updates are controlled by the refresh rate in SOA record for zone). Both Notify and Incremental Zone Transfers are used to reduce propagation delay and bandwidth utilization (see [33]).
Mapping names to addresses
As well as resolving names to addresses, we need a way of resolving addresses to names. For example, this might be required to postfilter an event log file so that IP addresses within the file are automatically mapped onto their domain names for easier interpretation. Given the naming structure we have defined so far this would appear to be a difficult task, requiring a brute-force search of the entire domain space, since there is no correlation between the naming hierarchy and the IP addresses. However, the mechanism used to resolve this problem with IPv4 is quite simple: Below the arpa TLD is a special subdomain called in-addr. Nodes within the in-addr.arpa domain are named according to dotted-decimal notation rather than labels—the first level under in-addr comprising nodes 0–255, each with 0–255 subdomains and so forth. In this way all available IP addresses can be represented, and data associated with each node are the domain label itself. Note that in this format the IP address, when represented in domain name format, will appear backwards, since the name is read leaf to root. Reference [38] describes some of the shortcomings of DNS, in particular the in-addr implementation, and proposes that addresses should be queried directly for corresponding domain names using two new ICMP types: Domain Name Request and Domain Name Reply. This work remains experimental, and the interested reader should refer to [38].
With IPv6 a special domain is defined to provide address-to-name mapping, rooted at ip6.int. An IPv6 address is represented as a name in the ip6.int domain by a sequence of nibbles (half-bytes) separated by dots with the suffix .ip6.int. The sequence is encoded in reverse order—that is, the low-order nibble is encoded first, followed by the next low-order nibble and so on. Each nibble is represented by a hexadecimal digit. For example, the inverse lookup domain name corresponding to the address
4321:0:1:2:3:4:567:89ab
would be:
b.a.9.8.7.6.5.0.4.0.0.0.3.0.0.0.2.0.0.0.1.0.0.0.0.0.0.0. 1.2.3.4.IP6.INT.
Not a pretty sight! For further details refer to [34].
Inverse query operation
The in-addr.arpa domain is restricted to recovering information associated with addresses. Inverse DNS queries are used to dynamically map a domain name to some arbitrary data, via a kind of exhaustive search, restricted in scope to the name server that received the query. Inverse queries are not guaranteed to be successful, since the local server will drop the query if it cannot service the request using its own local database or cache (this limitation avoids the potential for DNS meltdown).
Caching
Name servers usually employ a local cache for storing recently used names as well as a record of where the mapping information for that name was obtained. Caching is fundamental to the efficient operation of the DNS in two ways: by reducing latency in turning around mapping information and by reducing traffic on the network. The process is quite simple: When a resolver asks the name server to resolve a name, the server first checks to see if it has authority for the name. If so, then the server already controls the associated binding in its database and can respond directly. If not, then the server checks its cache (if implemented) to see whether the name has already been resolved and cached. If so, then the server responds using the cached information for this and all subsequent queries, and this does not result in additional queries to other servers. Some DNS implementations (e.g., BIND version 4.9.3) go one step further, by supporting a feature called negative caching. This is the ability to cache responses from a name server that indicate that the information requested does not exist in a particular domain (hence, subsequent queries in that domain would be fruitless). The interested reader is referred to [39].
Since binding information may change over time, it is important that the name server flushes these cached data regularly to maintain network synchronization, so a Time to Live (TTL) value is associated with cached entries. Whenever an authority responds to a request, it includes a TTL value in the response that specifies how long it guarantees the binding to remain valid.
Implementing DNS
If you have a small LAN with no Internet access, then you can get away with using static mapping files or perhaps an alternative naming system such as Sun's Network Information Service (NIS). If you are connecting to the Internet, then you must use the DNS. There are two basic ways to configure DNS. You could either use your ISP's DNS server (most ISPs support this capability; alternatively, you could set up a DNS server on your own network). The choice between the two approaches is influenced by the need for local control and your ability to configure and maintain these services on site, as follows:
-
ISP Maintained Primary and Secondary DNS Service—For a small network it is advisable to let your ISP maintain DNS services. In this case the ISP will supply you with the IP addresses of the primary and secondary DNS servers, which you must then configure on all end system TCP/IP stacks (either manually or via a DHCP server). You must inform your ISP as to which names you wish to advertise to enable outside users to connect to services on your network. In addition, if you want to receive e-mail from the Internet, you must have a Mail Exchange (MX) record for your domain in your ISP's DNS database. This record identifies a machine that accepts e-mail for your domain and has three parts: your domain name, the name of the machine that will accept mail for the domain, and a preference value. You can have multiple MX records for your domain; the preference value lets you build some fault tolerance into your mail setup. If you plan to use your ISP's DNS server, you'll also need to have the ISP set up some A records, which associate IP addresses with computer names. Each of the computers mentioned in your MX records needs an (A) record to associate them with an IP address. You may also want to set up A records for each of your workstations if your users need to use FTP to download software from the Internet. This is because some FTP sites perform a lookup to get the DNS name of the machine from which they receive download requests. If the machine has no name, the sites deny the request. You'll also need A records for any public servers you maintain. For example, if you have a World Wide Web server, you'll need to have the ISP set up an A record linking the name www.mycompany.com to the IP address of your Web server.
-
Locally Maintained Primary and Secondary DNS Service—If your ISP does not support name services or if you need to have a DNS server running on your local site (for security, control, or performance reasons), then you must have at least two name servers: a primary and a secondary. You will not be granted an official domain name unless there are at least two DNS servers on the Internet with information about your domain. The second server also provides fault tolerance in the event of a primary server failure. If you choose to administer the primary name server yourself, bear in mind that you'll have to maintain the DNS records.
-
ISP Maintained Primary and Locally Maintained Secondary DNS Service—For many networks it may be appropriate to maintain the secondary DNS server on the local site and have this peer with the primary server maintained by the ISP. In this mode the ISP will still do all of the maintenance work, and your name server will periodically download the data about your domain from the primary server automatically. This configuration provides additional resilience in the event the ISP connection fails (e.g., if you had a backup Internet connection via another ISP, then your end systems would automatically fail over to the secondary server and service would be resumed).
If you plan to run your own name services, then perhaps the most popular software to implement is the BIND application, which often comes as a standard part of the UNIX operating system. The BIND source code is also freely available and so can be recompiled or ported to other platforms. The interested reader is directed to [31, 40].
Split DNS
Split DNS is essentially a security feature for implementing DNS where you have a public and private interface to your network (typically interfacing with a firewall). Essentially you configure two primary DNS servers for the domain. The external server hides the structure of the internal network and publishes a subset of the resources available (typically Web, mail, FTP, and other externally available servers). The internal clients point to the internal primary DNS server, which publishes all useful resources, including potentially sensitive servers behind the firewall. See Chapter 5 for more details.
Dynamic DNS
With DHCP a host may request not only an IP address but also a dynamic name. Clearly, dynamic names are inappropriate for some network devices (e.g., Web or mail servers and FTP servers), since these must by definition use well-known statically assigned names. However, given that the physical devices used to provide these services might change dynamically, it would be extremely useful to have static names associated with dynamic IP addresses. Several vendors have developed solutions for Dynamic DNS (DDNS), although the IETF is currently working on a standard for this feature.
Resilience
There is redundancy built into DNS in that secondary servers automatically back up primary servers. If the primary fails, then client software (the resolver) is responsible for switching over to a secondary server. Furthermore, Root and TLD servers are normally duplicated for resilience. At the time of writing there were nine root servers distributed internationally.
DNS performance
The organization of the domain system is based on several assumptions about the needs and use patterns of its user community. The DNS is designed to avoid many of the complicated problems found in general-purpose database systems. The assumptions are as follows:
-
The size of the total database will initially be proportional to the number of hosts using the system, but it will eventually grow to be proportional to the number of users on those hosts, as mailboxes and other information are added to the domain system.
-
Most of the data in the system will change very slowly (e.g., mailbox bindings, host addresses), but the system should be able to deal with subsets that change more rapidly (on the order of seconds or minutes).
-
Access to information is more critical than instantaneous updates or guarantees of consistency. Hence, the update process allows updates to percolate out through the users of the domain system rather than guaranteeing that all copies are simultaneously updated.
In the interests of performance, implementations often integrate several functions. For example, a resolver on the same machine as a name server might share a database comprising the zones managed by the name server and the cache managed by the resolver.
Issues
There are many subtle issues with DNS performance; therefore, it is difficult to predict performance, since there are many scenarios and design options to consider, including the following:
-
Since domain names are often repeated many times within DNS messages, DNS uses an optional form of message compression through special encoding (described earlier). So message size is not absolute but varies depending upon the amount of repetition.
-
Primary DNS servers in very large domains should be implemented on dedicated machines to cope with the number of requests. Typically, DNS services are implemented under UNIX, via the standard name daemon (Berkeley Internet Name Domain, BIND, or, alternatively, named). DNS servers typically require high-performance disk I/O (preferably a RAID system) to keep up with dynamic DNS updates.
-
Caching can improve performance and reduce network traffic substantially, and you should deploy large caches in strategic locations to get the best hit ratio. For example, if your network has many small branch offices connected to a central headquarter site, each branch location could have a separate domain. The primary DNS server for each remote site zone would typically be held at the central site, and, if possible, a secondary DNS server would be configured at each remote site. For Small-Office-Home-Office (SOHO) configurations all DNS requests would typically be handled via the central site. Caching timers should be configured so that cached data do not become hopelessly out-of-date, resulting in performance or connectivity problems. The time limit for cached data is usually set in seconds (say 86,400 seconds for a day, or 604,800 seconds for a week). A larger interval reduces network traffic, but remember that these data could be cached on thousands of name servers. Reference [39] states that a large proportion of DNS traffic on the Internet could be eliminated if all resolvers implemented negative caching.
-
Even with extensive caching deployed, root name servers are particularly hard hit, and for resilience purposes there are several root servers deployed around the world (although less than a dozen at the time of writing). Clearly, these devices need to scale as the requirement for DNS access grows.
-
The .COM domain has grown very large and there is concern about the administrative load and system performance if the current growth pattern is continued. Consideration is being taken to subdivide the .COM domain and to allow future commercial registrations only in the subdomains [41].
Relatively new DNS standards enhancements include Dynamic DNS updates [42], Incremental Zone Transfers [43], and Notify [44]. These features dramatically reduce propagation delays and WAN bandwidth utilization. They also integrate DHCP with DNS so that newly configured devices (via DHCP) trigger incremental DNS updates via the primary domain name server.
2.3.3 Windows Internet Names Service (WINS)
Windows Internet Names Service (WINS) is found on Microsoft operating systems. It assumes a flat name space and provides basic functions including the NetBIOS Names Service (NBNS) and Windows NT file and print services. WINS can coexist with DNS. WINS, unfortunately, has real scalability problems when used in large networks and is likely to disappear with Windows 2000, which uses a feature called Active Directory, which is dependent on DNS.
2.3.4 Network Information Service (NIS)
Network Information Service (NIS) is an implementation of name service functionality available from Sun, running on Sun platforms. NIS is generally deployed in small enterprises; it is recommended for access to the Internet DNS (via BIND), since DNS is the native name service for the Internet.
|
|