| Now that we understand some of the basic functionality of a processor as well as some of the techniques available to designers to try to improve the overall throughput of a processor, let's look at some of the common processor families available in today's computers and which tricks they employ to maximize performance. A.2.1 CISC: Complex Instruction Set Computing Before we explore some of the features of a CISC architecture, let's discuss something called the semantic gap . The semantic gap is the difference between what we want to do with a machine and what the machine will actually do . As we discussed earlier, instructions do things like ADD , SUB , and LOAD . We then ask ourselves , " How does that equate to displaying a graphic on our screen? " The semantic gap between what we want to do, i.e., display a graphic, and what the computer can actually do is rather wide. When programming a computer, it would be convenient if the assembly language instructions closely matched the functions we wanted to perform. This is the nature of high-level programming languages. The programming language closes the semantic gap by allowing us to program using more human-readable code that is subsequently translated into machine code by a compiler. Back in the early days of computing, i.e., the 1950s, compilers were either not very good or simply weren't available. It was common for programmers to hand-code in assembler in order to circumvent the failings of the compiler. Programming in assembler became commonplace. Back then, computers didn't have much memory, so the programs written for them had to be efficient in the use of memory. Being human, we prefer tools that are easy to use but at the same time powerful. When using assembler, if you have a single instruction that performs a rather complicated task, the motivation to use it is high: You can get the job done quicker because your programs are smaller, easier to write, and easier to maintain, e.g., a DRAWCIRCLE instruction is easy to understand and maintain. As programmers, we are not concerned with the resulting additional work undertaken by the processor to decode the DRAWCIRCLE instruction into a series of LOAD , ADD , and SUB instructions. With having fewer individual instructions, there are fewer fetches from memory to perform. If you are spending less time fetching, you can be spending more time executing. Back in the 1950s, accessing memory was very slow , so the motivation was high to perform fewer fetches. The concept of pipelining had not even been considered . Back in the 1950s, computers were all but a few sequential in operation. (IBM developed the IBM 7030 ”known as Stretch ”which incorporated pipelined instructions and instruction look-ahead as well as 64-bit word. The U.S. government bought a number of these machines for projects such as atomic energy research at huge losses to IBM.) The other benefit in those days was that smaller programs took up less memory, leaving more space for user data. Having a myriad of instructions was a major benefit because we could use the instructions we needed to perform the specific tasks required, while at the same time the diversity of instructions made the computer itself attractive to many types of problems. Having a general-purpose computer was a new concept in those days and was a dream-come-true for the marketing departments of the few computer companies that had spearheaded the technology. A crucial element in the design was the size and complexity of the instruction set. In those days, the ideas of superscalar and super-pipelining were the things of dreams and fantasies. If the designers in those days had the materials and technologies available to today's architects , maybe some of their designs would have been different. The design philosophy behind CISC is to close the semantic gap by supplying a large and varied instruction set that is easy to use by the programmers themselves ”supply a large and diverse instruction set and let the programmers decide which instructions to choose. We have to remember the historical context we are working in during this discussion. A processor is a relatively small device packed with transistors that have a finite density. Even in the 1970s and 1980s, the density of transistors was a fraction of what it is now. The fact that we are providing a myriad of instructions does not mean that all the instructions will be executed directly on the processor. In fact, few if any instructions will actually be executed directly on the processor. Standing in their way is a kind of instruction deconstructer . This black box will accept an instruction and decompose it into micro-instructions . These micro-instructions are the actual control logic to manipulate and instruct the various components of the processor to operate in the necessary sequence. This is commonly called micro-programming with the micro-instructions being known as microcod e. In this way, we are hiding the complexities of processor architecture from the programmers, making their job easier by supplying the easy-to-use instruction set to construct their programs. The instruction deconstructer or decoder becomes a processor within a processor. An immediate advantage here is that maintaining the instruction set becomes much easier. To add new instructions, all we need to do is update the microcode ; there's no need to add any new hardware. An added advantage of this architecture philosophy is that you if we migrate the microcode sequencer to a any new, bigger, faster processor, our programmers don't need to learn anything new; all of the existing instructions will work without modification. In effect, it is the microcode that is actually being executed; our assembler instructions are simply emulated . Looking back to our bag of tricks in Section A.1.3, let's look at which tricks a CISC architect could employ. Superscalar : Nothing prevents the control logic for the various components on a CISC processor from being activated simultaneously , so we could say that a CISC processor was superscalar. Pipelining : This is a bit trickier. As we saw with pipelining, the trick is we know that each stage of an instruction will complete within one clock cycle. First, CISC instructions may be of different sizes, so breaking them down to individual stages may be more difficult. Second, due to the complex nature, some stages of execution may take longer than others. Consequently, pipelining is more of a challenge for CISC processors. Instruction size : Due to the flexibility inherent in the design of a CISC instruction set, instruction size is variable, depending on the requirements of the instruction itself. Addressing modes : CISC architectures employ various addressing modes. Because any given instruction can address memory, it is up to an individual instruction on how to accomplish this. This also means that we can reduce the overall number of registers on the processor because anyone can reference memory and only when they need to. It would appear that a CISC architecture has lots of plus points. Once you have sorted out the microcoding, you become the programmer's best friend : You can give them hundreds of what appear to a programmer to be useful instructions. Each instruction is ostensibly free format, with an addressing mode to suit the needs of the programmer. Table A-2 demonstrates that CISC is by no means a dead architecture. Companies like Intel and AMD are investing huge sums of money in developing their processors and making handsome profits from it. The plus points achieved by CISC architectures come at a price. Traditionally, designers have had to run CISC processors at higher clock speeds than their RISC counterparts in order to achieve similar throughput. When some people look at a clock speed of 2.4 GHz, they say, " Wow, that's fast ." I hope that we are now in a position to comment on the necessity for a clock speed of 2.4GHz in a CISC architecture. Is it a good thing or simply a necessity due to the complexity of the underlying architecture? Table A-2. CISC Architectures | Instruction Set Architecture ( ISA ) | Processor | | Intel 80x86 | Intel Pentium AMD Athlon | | DEC VAX | VAX-11/780 (yep, the original 1 MIP machine) | | Characteristics of a CISC Architecture | | Large number of instructions | Complex instructions are decomposed by microprograms called micro-code before being executed on the processor | | Complex instructions taking multiple cycles to complete | Fewer numbers of register sets | | Any instruction can make reference to addresses in memory | Traditionally requires higher clock speeds to achieve acceptable overall throughput. | | Variable format instructions | Multiple addressing modes |
Few processors are entirely based on one architecture. Next , we look at RISC (Reduced Instruction Set Computing) in Table A-3. Some would say it's the natural and obvious competitor to CISC. Table A-3. RISC Architectures | Instruction Set Architecture ( ISA ) | Processor | | HP PA-RISC | PA8700+ | | Sun SPARC | Sun UltraSparc III | | IBM PowerPC | IBM PPC970 | | SGI MIPS | SGI MIPS R16000 | | Characteristics of a RISC Architecture | | Fewer instructions | Simple instructions "hard wired" into the processor, negating the need for microcode. | | Simple instructions executing in one clock cycle | Larger numbers of registers | | Only LOAD and STORE instructions can reference memory. | Traditionally can be run at slower clock speeds to achieve acceptable throughput. | | Fixed length instructions | | | Fewer addressing modes | |
A.2.2 RISC: Reduced Instruction Set Computing The RISC architecture has come to the fore since the mid-1980s. Most people seem to think that RISC was invented at that time. In fact, Seymour Cray created the CDC 6600 back in 1964. Ever- diminishing costs of components and cost of manufacture have driven the recent advances in the use of RISC architectures. As the cost of memory fell, the necessity to have small, compact programs diminished. Programmers could now afford to use more and more instructions, because they no longer had to fit a program into a memory footprint whose size could be counted in the tens of kilobytes. We could now have programs with more instructions. At the same time, compiler technology was advanced at a rapid pace. Numerous studies were undertaken in an attempt to uncover what compilers were actually doing, in other words, which instructions the compilers were actually selecting to perform the majority of tasks. These studies revealed that instead of using the myriad of instructions available to it, compilers preferred to utilize a smaller subset of available instructions. The obvious question to processor designers was, " Why have such a large, complex instruction set? " The result was the Reduced Instruction Set Computing architecture (RISC). It is common for a RISC instruction set to have fewer instructions than a comparable CISC architecture. It was not a precursor for a RISC architecture; it's just that RISC designers found that they could utilize their current instructions in clever sequences in order to perform more complex tasks. Hence, the instruction set can stay relatively small. With this in mind, it could be said that it is the complexity of the instructions that was Reducing ; as a side effect and natural consequence, the number of those instructions gets reduced at the same time. What we are looking to achieve can be summarized as follows : -
Build an instruction set with only the absolute minimum number of instructions necessary. -
Endeavor to simplify each instruction to such as extent that the processor can execute any instruction within one clock cycle. -
Each instruction should adhere to some agreed format, i.e., they are all the same size and use a minimal number of addressing modes. This all sounds like good design criteria when viewed purely from the perspective of pure performance. Let's not forget the programmer who has now to deal with this new instruction set. He may not have at his disposal the easy-to-use, human understandable instructions he had with the CISC architecture. What does he do now? The semantic gap between man and machine has suddenly widened. The secret here is to look back to the compiler studies undertaken with CISC architectures. Compilers like simple instructions. Compilers can reorder simple instructions because they are easier to understand and it is easier to predicate their behavior. This is the essence of closing the semantic gap . The gap is closed by the compiler. Some would say that processor architects are simply passing the semantic buck onto compiler writers. However, it is much more cost-effective to write a compiler, test it, tune it, and then rewrite better than to redesign an entire processor architecture. In essence, with RISC we are focusing more on working smarter . With simplified instructions, we are trying to minimize the number of CPU cycles per instruction. CISC on the other hand was trying to minimize the overall number of instructions needed to write a program ”and as a result reduce the size of the program in memory. We can immediately identify a fundamental difference in the philosophies of both architectures. total_ execution_ time = number_ of_ instructions* cycles_ per_ instruction* cycle_ time If we measure the cycle_time in fractions of a second, cycle_time being directly proportional to the processor speed in megahertz , we can understand why CISC architectures commonly utilize higher clock speeds, while RISC architectures can utilize slower clock speeds but still maintain overall throughput. Another aspect of RISC architectures that helps to reduce complexity is the addressing modes used by instructions. First, there are usually only two types of instructions that are allowed to access memory: LOAD and STORE . All other instructions assume that any necessary data has already been transferred into an appropriate register. Immediately, this simplifies the process of accessing memory. Second, with fewer instructions needing to access memory, the methods used by LOAD and STORE instructions to address memory can be simplified. Again, this is not a precursor, but simply a natural consequence of having a simplified architecture. The tradeoff in this design is that we need to supply a higher number of registers on the processor itself. This is not so much of a tradeoff because registers are the devices in the memory hierarchy that have the quickest response time. Having more of them is not such a bad thing; it's just that the do so takes up space on the processor that could have been used for something else . The fact is, the something else was probably the old microcode sequencer used to decode complex instructions, so we haven't actually added any additional circuitry overall to the processor itself. Let's again look back to our bag of tricks in Section A.1.3 and discuss which features RISC architectures employ: Superscalar : This has become a need in most processors these days. The challenge has become how superscalar can you get. As we mentioned previously, some architectures are achieving four-way superscalar capabilities, i.e., being able to sequence four instructions simultaneously. With more individual components on a processor, the possibilities for further parallelism increase. Pipelining : This is something that RISC architectures find relatively simple to accomplish. The main reason for this is that all instructions are of the same size and, hence, are predictable in the overall execution time. This lends itself to decomposing instructions into simplified, well-defined stages ”a key undertaking if pipelining is going to be at it most effective. Instruction size : All instructions should be of the same size as we have seen from the desire to implement pipelining in the architecture; a 32-bit instruction size is not uncommon. Addressing modes : Due to the simplified LOAD / STORE access to memory, it is not uncommon for RISC architectures to support fewer addressing modes. Although few architectures are solely RISC in nature, RISC as a design philosophy has become widespread. Advances with today's RISC processors have been in topics such as out-of-order execution and branch prediction . Some would say that RISC architectures still leave a wide semantic gap that needs to be bridged by advanced, complex compilers. Many programmers have found that the simple approach adopted by RISC can more often than not be easier to program than the more natural CISC architectures. The list of Top 500 supercomputers in the world (http://www.top500.org) is littered with RISC processors, a testament to its success as a design philosophy. We now look at HP's current implementation of RISC: the PA-RISC 2.0 instruction set architecture. A.2.2.1 HEWLETT-PACKARD'S PA-RISC 2.0 Since its introduction in the early 1980s, the PA-RISC (Precision Architecture Reduced Instruction Set Computing) architecture has remained quite stable. Only minor changes were made over the next decade to facilitate higher performance in floating-point and system processing. In 1989, driven by performance needs of the HP-UX workstation, PA-RISC 1.1 was introduced. This version added more floating-point registers, doubled the amount of register space for single-precision floating-point numbers, and introduced combined operation floating-point instructions. In the system area, PA-RISC 1.1 architectural extensions were made to speed up the processing of performance-sensitive abnormal events, such as TLB misses. Also added was big-endian support (see Figure A-3). Figure A-3. Big-endian versus little-endian byte ordering. 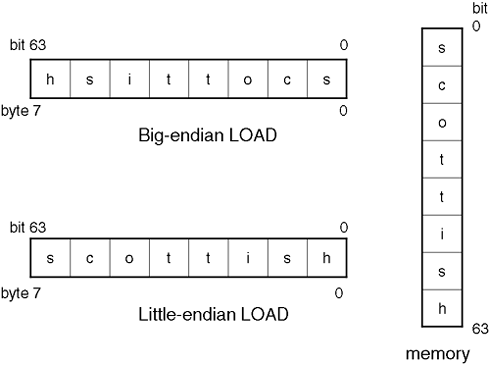
HISTORICAL NOTE : Endian relates to the way in which a computer architecture implements the ordering of bytes. In PA-RISC, we have the Processor Status Word ( PSW ), which has an optional E-bit that controls whether LOADS and STORES use big-endian or little-endian byte ordering. Big-endian describes a computer architecture in which, within a given multi-byte numeric representation, the most significant byte has the lowest address (the word is stored big-end-first ). With little-endian, on the other hand, bytes at lower addresses have lower significance (the word is stored little end first ). Figure A-3 shows the difference between big-endian and little-endian byte ordering. The terms big-endian and little-endian come via Jonathan Swift's 1726 book, Gulliver's Travels . Gulliver is shipwrecked and swims to the island of Lilliput (where everything is 1/12 of its normal size). There, he finds that Lilliput and its neighbor Belfescu have been at war for some time over the controversial material of how to eat hard-boiled eggs: big end first or little end first. It was in a paper entitled "On Holy Wars and a Plea for Peace" in 1980 that Danny Cohen used the terms big-endian and little-endian as a means by which to store data. A.2.2.2 64-BIT EXTENSIONS PA-RISC 1.x supported a style of 64-bit addressing known as segmented addressing. In this style, many of the benefits of 64-bit addressing were obtained without requiring the integer base to be larger than 32 bits. However, this did not easily provide the simplest programming model for single data objects (mapped files or arrays) larger than 4GB. Support for such objects calls for larger than 32-bit flat addressing , that is, pointers longer than 32 bits that can be the subject of larger than 32-bit indexing operations. PA-RISC 2.0 provides full 64-bit support with 64-bit registers and data paths. Most operations use 64-bit data operands and the architecture provides a flat 64-bit virtual address space. A.2.2.3 SUPPORT FOR LARGE HIGH-END APPLICATIONS One key feature of PA-RISC 2.0 is the extension the PA-RISC architecture to a word size of 64 bits for integers, physical addresses, and flat virtual addresses. This feature is necessary because 32-bit general registers and addresses with a maximum of 2 32 byte objects become limiters as physical memories larger than 4GB become practical. Some high-end applications already exceed the 4GB working set size. Table A-4 summarizes some of the PA-RISC 2.0 features that provide 64-bit support. Table A-4. PA-RISC Features | New PA- RISC 2.0 Feature | Reason for Feature | | Processor Status Word 1 [*] W-bit [  ] ] | Provides 32-bit versus 64-bit pointers | | Variable sized pages | More flexible intra-space management and fewer TLB entries | | Larger protection identifiers | More flexible protection regions | | More protection identifier registers | More efficient management of protection identifiers | | Load/store double (64 bits) | 64-bit memory access | | Branch long instruction | Increases branch range from plus or minus 256KBytes to plus or minus 8Mbytes |
[*] Processor state is encoded in a 64-bit register called the Processor Status Word (PSW). [ ] The W-bit is bit number 12 in the PSW. Setting the W-bit to 0 indicates to the processor that data objects are 32 bits in size. Setting the W-bit to 1 indicates to the processor that data objects are 64 bits in size. The task of setting the W-bit is the job of the compiler/programmer. A.2.2.4 BINARY COMPATIBILITY Another PA-RISC 2.0 requirement is to maintain complete binary compatibility with PA-RISC 1.1. In other words, the binary representation of existing PA-RISC 1.1 software programs must run correctly on PA-RISC 2.0 processors. The transition to 64-bit architectures is unlike the previous 32-bit microprocessor transition that was driven by an application pull. By the time that technology enabled cost-effective 32-bit processors, many applications had already outgrown 16-bit size constraints and were coping with the 16-bit environment by awkward and inefficient means. With the 64-bit transition, fewer applications need the extra capabilities, and many applications will choose to forgo the transition. In many cases, due to cache memory effects, if an application does not need the extra capacities of a 64-bit architecture, it can achieve greater performance by remaining a 32-bit application. Yet 64-bit architectures are a necessity since some crucial applications, databases, and large-scale engineering programs, and the operating system itself need this extra capacity. Therefore, 32-bit applications are very important and must not be penalized when running on the 64-bit architecture; 32-bit applications remain a significant portion of the execution profile and should also benefit from the increased capabilities of the 64-bit architecture without being ported to a new environment. Of course, it is also a requirement to provide full performance for 64-bit applications and the extended capabilities that are enabled by a wider machine. A.2.2.5 MIXED-MODE EXECUTION Another binary compatibility requirement in PA-RISC 2.0 is mixed-mode execution. This refers to the mixing of 32-bit and 64-bit applications or to the mixing of 32-bit and 64-bit data computations in a single application. In the transition from 32-bits to 64-bits, this ability is a key compatibility requirement and is fully supported by the new architecture. The W-bit in the Processor Status Word is changed from 0 (Narrow Mode) to 1 (Wide Mode) to enable the transition from 32-bit pointers to 64-bit pointers. A.2.2.6 PERFORMANCE ENHANCEMENTS Providing significant performance enhancements is another requirement. This is especially true for new computing environments that will become common during the lifetime of PA-RISC 2.0. For example, the shift in the workloads of both technical and business computations to include an increasing amount of multimedia processing led to the Multimedia Acceleration eXtensions (MAX) that are part of the PA-RISC 2.0 architecture. (Previously, a subset of these multimedia instructions was included in an implementation of PA-RISC 1.1 architecture as implementation-specific features.) Table A-5 summarizes some of the PA-RISC 2.0 performance features. Table A-5. The New PA-RISC Features | New PA- RISC 2.0 | Feature Reason for Feature | | Weakly ordered memory accesses | Enables higher performance memory systems | | Cache hint: Spatial locality | Prevents cache pollution when data has no reuse | | Cache line pre-fetch | Reduces cache miss penalty and pre-fetch penalty by disallowing TLB miss |
A.2.2.7 CACHE PRE-FETCHING Because processor clock rates are increasing faster than main memory speeds, modern pipelined processors become more and more dependent upon caches to reduce the average latency of memory accesses. However, caches are effective only to the extent that they are able to anticipate the data, and consequently processors stall while waiting for the required data or instruction to be obtained from the much slower main memory. The key to reducing such effects is to allow optimizing compilers to communicate what they know (or suspect) about a program's future behavior far enough in advance to eliminate or reduce the "surprise" penalties. PA-RISC 2.0 integrates a mechanism that supports encoding of cache prefetching opportunities in the instruction stream to permit significant reduction of these penalties. A.2.2.8 BRANCH PREDICTION A surprise also occurs when a conditional branch is mispredicted . In this case, even if the branch target is already in the cache, the falsely predicted instructions already in the pipeline must be discarded. In a typical high-speed superscalar processor, this might result in a lost opportunity to execute more than a dozen instructions. PA-RISC 2.0 contains several features that help compilers signal future data and likely instruction needs to the hardware. An implementation may use this information to anticipate data needs or to predict branches more successfully, thus, avoiding the performance penalties. A.2.2.9 MEMORY ORDERING When cache misses cannot be avoided, it is important to reduce the resultant latencies. The PA-RISC 1.x architecture specified that all loads and stores be performed in order , a characteristic known as strong ordering . Future processors are expected to support multiple outstanding cache misses while simultaneously performing LOAD and STORE to lines already in the cache. In most cases, this effective reordering of LOAD and STORE causes no inconsistency and permits faster execution. The later model is known as weak ordering and is intended to become the default model in future machines. Of course, strongly ordered variants of LOAD and STORE must be defined to handle contexts in which ordering must be preserved. This need for strong ordering is mainly related to synchronization among processors or with I/O activities. A.2.2.10 COHERENT I/O As the popularity and pervasiveness of multiprocessor systems increases, the traditional PA-RISC model of I/O transfers to and from memory without cache coherence checks has become less advantageous. Multiprocessor systems require that processors support cache coherence protocols . By adding similar support to the I/O subsystem, the need to flush caches before and/or after each I/O transfer can be eliminated. As disk and network bandwidths increase, there is increasing motivation to move to such a cache coherent I/O model . The incremental impact on the processor is small and is supported in PA-RISC 2.0. A.2.2.11 MULTIMEDIA EXTENSIONS PA-RISC 2.0 contains a number of features that extend the arithmetic and logical capabilities of PA-RISC to support parallel operations on multiple 16-bit subunits of a 64-bit word. These operations are especially useful for manipulating video data, color pixels, and audio samples, particularly for data compression and decompression . Let us move on to a reemerging design philosophy VLIW (Very Long Instruction Word). Intel and Hewlett-Packard have spearheaded its reemergence with their new IA-64 instruction set and Itanium and Itanium2 processors. A.2.3 VLIW: Very Long Instruction Word Table A-6 lists the features of Very Long Instruction Word (VLIW) architectures. Table A-6. VLIW Architecture | Instruction Set Architecture ( ISA ) | Processor | | Intel IA-64 | Intel Itanium | | Multiflow Cydrome | Multiflow Trace Cydrome Cydra | | Characteristics of an VLIW Architecture | | Fewer instructions | Large number of registers to maximize memory performance | | Very high level of instruction level parallelism | Multiple execution units to aid superscalar capabilities | | Uses software compilers to produce instruction streams suitable for superscalar operation | Less reliance on sophisticated branch management circuitry on-chip because the instruction stream by nature should be highly parallelized | | Fixed length instructions | |
The laws of quantum physics mean that the design philosophy of simply working harder by increasing clock speeds has a finite lifetime unless a completely new fabrication process and fabrication material is discovered . In the future, we are going to have to work smarter . A key to this is to try to achieve as much as possible in a single clock cycle. This is at the heart of any superscalar architecture. What we need for this to be accomplished is to have an instruction stream with a sufficient mix of instructions in order to activate the various functional units of the processor. Let's assume that our compiler is highly efficient at producing such an instruction stream. One way to further improve performance is to explicitly pass multiple instructions to the processor with every LOAD . We have to assume that any data required is already located in registers. What we now have with a single instruction is the explicit capability to activate multiple functional units simultaneously. One drawback with pure VLIW is that a program compiled on one architecture ”for example, with two functional units, e.g., an ALU taking one cycle to execute an instruction and a floating-point unit taking two cycles to execute an instruction ”will have an instruction stream taking into account these inherent limitations. If we were to move the program to a different architecture, e.g., with four functional units or possibly a faster floating-point unit, it would be necessary to recompile the entire program. The assumption I made earlier regarding data elements ”" Any data required is already located in registers " ”may also have an effect on the performance of the instruction stream. As processors evolve and increase in speed, memory latencies tend to increase as well; the disparity between processor and memory access times is one of the biggest problems for processor architects today. That assumption is based on the fact that pure VLIW provides no additional hardware to determine whether operands from previous computations are available; remember that it is the compiler's job to guarantee this by the proper scheduling of code. The result is that my assumption regarding data being already located in registers is no longer valid with pure VLIW. While VLIW offers great promise, some of its drawbacks need to be addressed. With clever design and the use of prediction, predicated instructions, and speculation , Itanium has endeavored to surmount all these drawbacks. They key benefits of Itanium can be summarized as follows: -
Massively parallel instructions -
Large register set -
Advanced branch architecture -
Register stack -
Prediction -
Speculative LOAD -
Advanced floating point functionality Intel and Hewlett-Packard jointly defined a new architecture technology called Explicitly Parallel Instruction Computing ( EPIC ), named for the ability of a compiler to extract maximum parallelism in source code and explicitly describe that parallelism to the hardware. The two companies also defined a new 64-bit instruction set architecture ( ISA ), based on EPIC technology; with the ISA, a compiler can expose, enhance, and exploit parallelism in a program and communicate it to the hardware. The ISA includes predication and speculation techniques, which address performance losses due to control flow and memory latency, as well as large register files , a register stack , and advanced branch architecture . The innovative approach of combining explicit parallelism with speculation and predication allows Itanium systems to progress well beyond the performance limitations of traditional architectures and to provide maximum headroom for the future. The Itanium architecture was designed with the understanding that compatibility with PA-RISC and IA-32 is a key requirement. Significant effort was applied in the architectural definition to maximize scalability, performance, and architectural longevity. Additionally, 64-bit addressability was added to meet the increasing large memory requirements of data warehousing, e-business, and other high performance server and workstation applications. At one point, the Itanium architecture was known as IA-64 , to promote the compatibility with and extension of the IA-32 architecture. However, the official name as defined by Hewlett-Packard and Intel is the Itanium Architecture. It is said that Itanium is an instance of EPIC architecture. In our discussion regarding VLIW, we noted that a key point of the architecture is the ability for the compiler to explicitly execute multiple instructions. To implement this idea, we no longer have individual instructions, but we have instruction syllables . In Itanium, we have three syllables that make up an instruction word or instruction bundle .  The instruction word is 128 bits in length. If life were simple, we would just glue together four 32-bit instructions and pass it to the processor. As we know, life isn't that simple. The 5-bit template determines which functional units are to be used by each syllable. Each syllable is 41 bits in length. One of the reasons to move away from a 32-bit instruction is the fact that almost every instruction in Itanium is executed by first checking the condition of a special register known as a predicate register . The first 6 bits of the instruction indicate which one of the 64 predicate registers is checked before execution is commenced. Architectural decisions such as predicate registers and branch registers allow compilers to do clever things when constructing an instruction stream, e.g., we can now compute the condition controlling a branch in advance of the branch itself. Itanium also incorporates branch prediction hardware, branch hints, and special branch hint instructions . This helps ensure that we minimize the rate of branch mis- predictions , which can waste not only clock cycles but also memory bandwidth. Altogether these features are designed to assist in constructing an instruction stream that is maximized for parallelism: work smarter . If we were to construct a block diagram of a VLIW instruction stream in a similar fashion to Figure A-2, it would look something like Figure A-4. Figure A-4. Stylized view of a VLIW instruction stream. 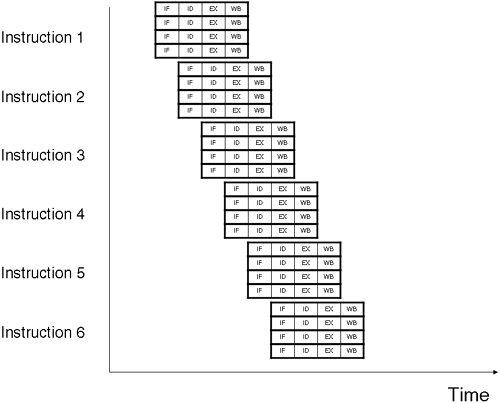
Some people would say that VLIW is using the best bits of both CISC and RISC. I can't disagree with such a statement, nor could I complain about it! A.2.4 Conclusions: Which architecture is best? The question of which architecture is best is difficult to answer. As of December 2003, the Top 500 Web site (http://www.top500.org) listed the NEC SX-5 vector processor running at the Earth Simulator Center, in Yokohama, Japan, as the fastest supercomputer. It is, in fact, 640 8-processor nodes connected together via a 16GB/s inter-node interconnect. Building a single machine with that processing power (35.86 Teraflops) is too cost prohibitive for most organizations. The architectural design of such a solution is commonly referred to as a computational cluster or Cluster Of Workstations (COWs). Just as an aside, we haven't mentioned vector processors simply because as a species , they are regarded as quite a specialized type of machine. A vector is a collection or list of data elements; think of a single-dimension array and you won't be too far off. A vector processor contains vector registers . When working on our vector of values, we have one vector in one vector register and another vector in another vector register . If our operation is an ADD the processor, it simply adds the contents of one vector to the other, storing the result in a third vector register . Such architectures can reap enormous performance improvements if a large proportion of your calculations involve vector manipulation . If not, the performance benefits may be negligible if any benefits are experienced at all. There is also an issue if your vector isn't the same size as the vector register . The processor has to go through a process of strip mining whereby it loops through a portion or part of your vector , performing the operation on each part until it is finished. Many people regard vector processors as too focused on a particular class of problem, making them not applicable in general problem solving scenarios. The truth is that many architectures these days are including vector registers as part of the architecture of their register sets in an attempt to try to appeal to a class of problems that can utilize vector processing . To answer the question at the top of this section ”" which architecture is best? " ”the answer as always is " it depends ." The architectures we have looked at here, including vector processors , span the majority of the history of computing. As ever-demanding customers, we expect our hardware vendors to be constantly looking to improve and innovate the way they tackle the problem of getting the most out of every processor cycle. My original intention was to look at some techniques that system architects use to focus on the third point of the work ethics in order to get the most out of time get someone else to help you . On reflection, I feel that we should take a look at "memory" in detail. Our discussions surrounding multi-processor machines will be affected by a discussion regarding memory, so let's start there. |