| With Extended Clusters and Metrocluster, we are effectively limited to distances up to 100Km due to latencies involved with extended distances. The latencies involved with distances beyond 100Km impact the performance of online applications with IOs having to traverse long distances. The distance limitations are due to DWDM technical limitations as well; we need to have a link-level transport for our heartbeat networks that is "a single wire;" we need to be able to perform a linkloop between all our cluster nodes. A linkloop will not work over a routed network, i.e., over a WAN link. This is not to say that we only consider Continentalclusters when we are dealing with distances over 100Km. I know of some customers who have considered Continentalclusters when their sites have been only a few miles apart. The major difference is hinted at in the name: Continentalclusters. Look at the last character in the name ; yep, we are talking about more than one cluster. In effect, we have two independent clusters that happen to be monitoring each other. These independent clusters can be anything from a simple Serviceguard cluster to an Extended Serviceguard or even a Metrocluster. The key here is that they are independent clusters on two separate IP networks. With Continentalclusters, we have an additional package called ccmonpkg that monitors the health of the other cluster. In the event of a failure, the administrator of the affected site is sent a notification that a failure has occurred. IMPORTANT The switchover to the recover cluster is not entirely automatic; it requires administrator intervention to start the process of recovery. |
Once the administrator on the recovery cluster has established the enormity and severity of the failure, he can instigate the process of moving the packages to the recovery cluster, which in itself can involve considerable work. Thankfully, Continentalclusters provides a command cmrecovercl to transfer the affected application(s) to the recovery cluster, making sure that they do not run on both clusters simultaneously . Figure 28-1 shows an example Continentalclusters solution. Figure 28-1. Continentalclusters. 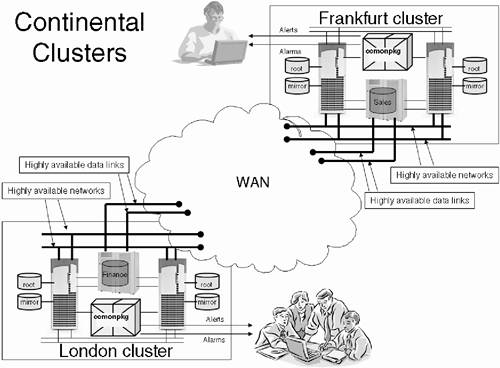
The connections between the sites can be a campus, metro, or WAN solution. We are not necessarily concerned with distances involved because the WAN solution will (has to) accommodate IP traffic, as well as any data replication solution we want to integrate into our Continentalclusters solution. In saying that, we need to consider carefully how we are going to replicate data between the two sites. Essentially, we have two options: logical replication and physical replication. -
Logical replication : This is where we duplicate application writes between the two sites. Applications such as Oracle 8i Standby Database offer such a solution. We could also have the filesystem duplicate itself over the WAN connection. We are not talking about a cluster filesystem here! We are talking about some automated process to copy a filesystem across the WAN connection. Such a solution will probably require additional scripting (commonly via a Serviceguard package) to ensure that regular and timely updates are sent between sites. Using logical replication via a Serviceguard package will require the configuration of what are called logical data sender packages as well as logical data receiver packages . Some solutions will use one (Oracle Standby database uses a logical data receiver package); some may require both. -
Physical replication : This is where we use some form of disk mirroring (MirrorDisk/UX) to replicate disks across sites. The distances involved commonly limit such a solution. The most common solution is physical replication between disc arrays such as HP Continuous Access XP or EMC Symmetrix SRDF. Again, due to the distances involved, asynchronous replication is the more common solution. Remember that if we want to offer mutual recovery, we need to accept that Continuous Access XP MCU ”RCU connections are unidirectional, hence, we need to provide and configure additional MCU ”RCU connections that refer back to the originating XP disc array(s). Whichever form of replication we choose, we need to ensure that the WAN solution has the bandwidth capacity to cope with the data transfers between sites. As always, the WAN solution needs adequate redundancy to not introduce an SPOF in the connections between sites: multiple Fibre and IP connections routed over separate physical paths. The latencies involved should not be an issue as far as online application performance because we will probably be relying on asynchronous data replication. Note : You should take great care in measuring the latencies involved in the WAN solution. You should endeavor to measure and quantify a typical workload for the data replication solution to handle. In this way, we can attempt to quantify how far behind the data replication solution will be in terms of data transfers between sites. This may have an impact on the configuration of your individual disc arrays as well as the method and frequency of stabilizing your application. We need to be sure that we incur as little cost in terms of data loss or corruption in the event of failure of one site. Extensive testing of the data replication solution should be undertaken before proceeding with the setup of Continentalclusters. 28.3.1 Setting up Continentalclusters The setup and testing of the hardware components in a Continentalclusters solution will take some considerable time. The setup of the software components is time-consuming , and extensive testing needs to be undertaken to ensure that all related processes work as expected. This is where we go back to one of our cornerstones of High Availability: IT Processes. Everyone involved in a Continentalclusters solution will need to be made aware, trained, and tested to ensure that they understand the implications of running packages within a Continentalclusters scenario. There are some changes to individual packages that are necessary in such a situation, as we see. Below is a procedure for setting up Continentalclusters. Each step has a number of individual stages, so be careful that you understand, plan, implement, and test each step of the procedure. This is non-trivial. -
Install Serviceguard and Continentalclusters software.
-
Configure data replication.
-
Configure the primary cluster.
-
Configure the recovery cluster.
-
Prepare the Continentalclusters security files.
-
Edit and apply the Continentalclusters monitor package.
-
Edit and apply the Continentalclusters configuration file.
-
Ensure that all primary packages are operating as normal. This includes any data sender/receiver packages as well.
-
Start the Continentalclusters monitor package.
-
Validate and test the Continentalclusters configuration.
The next few sections highlight some key tasks within each of these steps. 28.3.2 Install Serviceguard and Continentalclusters software It is worthwhile working out whether you have the appropriate software installed to perform data replication, e.g., the environment files for integrating Continuous Access XP or EMC Symmetric SRDF within a Metrocluster. The same files are used for integrating these data replication features into a Continentalclusters configuration. The files in question, /opt/cmcluster/toolkit/SGCA/xpca.env and /opt/cmcluster/toolkit/SGSRDF/srdf.env , were installed as part of installing my version of Continentalclusters:
root@hpeos001[] swlist B7659BA # Initializing... # Contacting target "hpeos001"... # # Target: hpeos001:/ # # B7659BA A.03.03 HP Continentalclusters B7659BA.ContClusters A.03.03 The Continentalclusters SD product for Disaster  Recovery B7659BA.MC-Common A.04.10 Metrocluster Common Product B7659BA.SG-SRDF-Tool A.04.10 SRDF Disaster Recovery Toolkit SG-SRDF-Tool Product B7659BA.SG-CA-Tool A.04.10 Metrocluster with Continuous Access XP Toolkit SD product root@hpeos001[] Recovery B7659BA.MC-Common A.04.10 Metrocluster Common Product B7659BA.SG-SRDF-Tool A.04.10 SRDF Disaster Recovery Toolkit SG-SRDF-Tool Product B7659BA.SG-CA-Tool A.04.10 Metrocluster with Continuous Access XP Toolkit SD product root@hpeos001[]
It is well worth checking this because in some cases, you may have to purchase and install Metrocluster as a separate product in order to obtain these configuration files. 28.3.3 Configure data replication In the vast majority of cases, we use physical data replication using built-in disk array functionality such as Continuous Access XP. Many of the tasks relating to setting up data replication for Metrocluster are similar to setting up data replication in Continentalclusters. Some obvious differences relate to the setup of Continuous Access XP itself. As we mentioned previously, it is common to use asynchronous data replication in Continentalclusters. This needs to be understood and implemented carefully. This is not the place to discuss the internals of configuring Continuous Access XP Extended (I could if you want me to, but this book would need an accompanying self-inflating wheelbarrow for you to carry such a huge book around with you) so I assume that you have spent some considerable time setting up and testing that part of your configuration; refer to the section on Metrocluster for some hints on using the template files xpca.env . A couple of important configuration changes include the following: -
Set the HORCMTIMEOUT value as appropriate. The default is 360 seconds (60 seconds greater than the default sidefile timeout value). If using CA-Extended (Asynchronous), set this value to be greater than the sidefile timeout value but less than the RUN_SCRIPT_TIMEOUT in the package control file. HORCMTIMEOUT=360 -
Set the FENCE level to either DATA , NEVER , or ASYNC , as appropriate (probably ASYNC in this instance). FENCE=ASYNC -
Set the CLUSTER_TYPE variable to continental CLUSTER_TYPE="continental" This is by no means the only task involved in setting up data replication. One important hardware requirement I will remind you of is to ensure that you have enough physical links between your XP arrays to allow for mutual recovery . This will require two links from your main XP to the remote XP and two links back again; remember that a single XP Continuous Access link is unidirectional. I will draw your attention to some sample files installed with Continentalclusters that can help you in this task:
root@hpeos001[Samples-CC] pwd /opt/cmcluster/toolkit/SGCA/Samples-CC root@hpeos001[Samples-CC] ll total 70 -r--r--r-- 1 bin bin 2560 Feb 11 2002 Readme-CC-Samples -rwxr--r-- 1 bin bin 6080 Feb 11 2002 horcm0.conf.ftsys1 -rwxr--r-- 1 bin bin 6080 Feb 11 2002 horcm0.conf.ftsys1a -rwxr--r-- 1 bin bin 6070 Feb 11 2002 horcm0.conf.ftsys2 -rwxr--r-- 1 bin bin 6081 Feb 11 2002 horcm0.conf.ftsys2a -rwxr--r-- 1 bin bin 2557 Feb 11 2002 mk1VGs -rwxr--r-- 1 bin bin 1748 Feb 11 2002 mk2imports -rwxr--r-- 1 bin bin 412 Feb 11 2002 scanconcl.sh -rwxr--r-- 1 bin bin 516 Feb 11 2002 services.example -rwxr--r-- 1 bin bin 203 Feb 11 2002 viewconcl.sh root@hpeos001[Samples-CC]
If you are using logical data replication, especially if you are using Oracle 8i Standby Database, I will draw your attention to some template files that may assist you in setting up logical data replication sender/receiver packages :
root@hpeos001[SGOSB] # pwd /opt/cmcluster/toolkit/SGOSB root@hpeos001[SGOSB] # ll total 410 -rwxr-xr-x 1 bin bin 16634 Dec 14 2000 ORACLE_primary.sh -rwxr-xr-x 1 bin bin 17937 Dec 14 2000 ORACLE_rcvr.sh -rwxr-xr-x 1 bin bin 17305 Dec 14 2000 ORACLE_recover.sh -rw-r--r-- 1 bin bin 61282 Dec 14 2000 README-CC -rw-r--r-- 1 bin bin 26300 Dec 14 2000 README-CC-FAILBACK dr-xr-xr-x 5 bin bin 1024 Aug 3 2002 Samples -rwxr-xr-x 1 bin bin 22372 Dec 14 2000 ora_primary_pkg.cntl -rwxr-xr-x 1 bin bin 21851 Dec 14 2000 ora_rcvr_pkg.cntl -rwxr-xr-x 1 bin bin 22258 Dec 14 2000 ora_recover_pkg.cntl root@hpeos001[SGOSB] #
28.3.4 Configure the primary cluster If we have an existing cluster, there are few configuration changes that we need to implement in order to prepare this cluster to take part in a Continentalclusters. Here is a breakdown of the tasks involved: -
Set up all WAN and data replication links as appropriate. Ensure that you do not introduce an SPOF in the WAN topology; all links should have redundancy and separate links should follow separate physical paths.
-
Ensure that you can contact ( ping at least) all nodes on the remote cluster from all nodes on the primary cluster. This may require setting up appropriate routing table entries on all nodes in both clusters.
-
Configure all high availability links to all storage devices (you probably already took care of this in the previous step, configuring data replication .
-
Consider the hardware configuration of the servers in the primary cluster; have they adequate capacity to run additional applications should the need arise? Do you need to consider employing performance management tools such as PRM and/or WLM?
-
Consider setting up NTP between the sites to ensure proper time -stamping of logfiles and, more importantly, time-stamping of application records.
-
Configure all shared volume/disk groups on all nodes in both clusters.
-
Ensure that the existing cluster is operating properly as a normal Serviceguard cluster. If setting up a new cluster, then set up a cluster as described in Chapter 21, "Setting Up a Serviceguard Cluster."
-
Ensure that packages that will participate in the Continentalclusters do not start automatically. There is the possibility that when each independent cluster starts up, it will automatically start each package. This is not a good idea in Continentalclusters. We could have a situation where a package is running on both clusters simultaneously. That is not good at all. The option in the package configuration file is AUTO_RUN ; set this to NO .
-
Ensure that all staff involved know which packages are Continental packages and therefore do not get started automatically. This is extremely important.
-
Configure the logical data replication sender package, if appropriate.
-
Ensure that all packages perform as expected. To test the logical data replication sender package, you may need to configure a logical data replication receiver package.
-
Once all testing is complete, halt all Continental packages including the logical data replication sender package.
root@hpeos001[] # cmviewcl -v CLUSTER STATUS London up NODE STATUS STATE hpeos001 up running Network_Parameters: INTERFACE STATUS PATH NAME PRIMARY up 8/16/6 lan0 STANDBY up 8/20/5/2 lan1 NODE STATUS STATE hpeos002 up running Network_Parameters: INTERFACE STATUS PATH NAME PRIMARY up 2/0/2 lan0 STANDBY up 4/0/1 lan1 UNOWNED_PACKAGES PACKAGE STATUS STATE AUTO_RUN NODE clockwatch down halted disabled unowned Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover configured_node Failback manual Script_Parameters: ITEM STATUS NODE_NAME NAME Subnet up hpeos001 192.168.0.0 Subnet up hpeos002 192.168.0.0 Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos001 Alternate up enabled hpeos002 root@hpeos001[] # root@hpeos001[] # ping hpeos003 PING hpeos003: 64 byte packets 64 bytes from 200.1.100.103: icmp_seq=0. time=1. ms 64 bytes from 200.1.100.103: icmp_seq=1. time=0. ms ----hpeos003 PING Statistics---- 2 packets transmitted, 2 packets received, 0% packet loss round-trip (ms) min/avg/max = 0/0/1 root@hpeos001[] # ping hpeos004 PING hpeos004: 64 byte packets 64 bytes from 200.1.100.104: icmp_seq=0. time=2. ms 64 bytes from 200.1.100.104: icmp_seq=1. time=0. ms ----hpeos004 PING Statistics---- 2 packets transmitted, 2 packets received, 0% packet loss round-trip (ms) min/avg/max = 0/1/2 root@hpeos001[] #
28.3.5 Configure the recovery cluster On the surface, it would appear that configuring the recovery cluster would in some way mirror setting up the primary cluster. I point out some tasks that may apply to both clusters. Remember, we may want to allow for mutual recovery ; packages may have to fail over in both directions. Here are some tasks you may want to consider: -
Set up all WAN and data replication links as appropriate. Ensure that you do not introduce an SPOF in the WAN topology; all links should have redundancy and separate links should follow separate physical paths.
-
Ensure that you can contact ( ping at least) all nodes on the remote cluster from all nodes on the primary cluster. This may require setting up appropriate routing table entries on all nodes in both clusters.
-
Consider the hardware configuration of the servers in the recovery cluster. Do they have adequate capacity to run additional applications? Do you need to consider employing performance management tools such as PRM and/or WLM?
-
Consider setting up NTP between the sites to ensure proper time-stamping of logfiles and, more importantly, time-stamping of application records.
-
Ensure that all nodes are running the same version of Serviceguard and all are patched similarly.
-
Configure the shared volume/disk groups. It makes good sense to keep the names of the volume/disk groups the same.
-
Set up the cluster as you would for any normal Serviceguard cluster. One cluster parameter you may need to consider is MAX_CONFIGURED_PACKAGES . Ensure that this is large enough to run all current packages in your local cluster as well as all packages from the primary cluster.
-
Configure all Continental packages on the recovery cluster: - a. Copy the package configuration files from the primary cluster. Some people rename the confirmation files to indicate that they are running in backup mode , e.g., clockwatch_bak.conf .
- b. Configure the list of adoptive nodes to reflect the nodes in the recovery cluster.
- c. Consider using the failover policy of MIN_PACKAGE_NODE to spread the load of running packages across all nodes in the recovery cluster. You need to think carefully about which nodes to run Continental packages on.
- d. AUTO_RUN should be set to NO , but it's worth checking.
- e. Change the SUBNET address to reflect the subnet address of the recovery cluster.
- f. Modify the application IP address to an appropriate address within the recovery cluster. You must ensure that the subnet address is also configured properly in the package control script.
- g. Rename any volume/disc groups and mount points as appropriate, although it is a good idea if the configuration can mirror the configuration on the primary cluster.
- h. Ensure that the package control script and any application monitoring scripts are distributed to all relevant nodes in the recovery cluster.
-
Some people I know will test that the package actually runs on the recovery cluster. I agree with this scenario. If you are going to test the Continental package on the recovery cluster, remember these things: -
- Ensure that the package is not running on the primary cluster because physical data replication may mean that you will not be able to access the data on the recovery cluster's XP array; external IO to an SVOL is not allowed while in a pair state. -
- If you do perform any changes to data on the recovery cluster, ensure that data replication resynchronizes the recovery data from the primary data. -
- Do not leave the package running on the recovery cluster when testing is finished.
root@hpeos003[] cmviewcl -v CLUSTER STATUS Frankfurt up NODE STATUS STATE hpeos003 up running Network_Parameters: INTERFACE STATUS PATH NAME PRIMARY up 0/0/0/0 lan0 STANDBY up 0/2/0/0/4/0 lan1 PACKAGE STATUS STATE AUTO_RUN NODE oracle1 up running enabled hpeos003 Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover min_package_node Failback automatic Script_Parameters: ITEM STATUS MAX_RESTARTS RESTARTS NAME Service up 0 0 oracle1_mon Subnet up 200.1.100.0 Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos003 (current) Alternate up enabled hpeos004 NODE STATUS STATE hpeos004 up running Network_Parameters: PACKAGE STATUS STATE AUTO_RUN NODE oracle1 up running enabled hpeos003 Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover min_package_node Failback automatic Script_Parameters: ITEM STATUS MAX_RESTARTS RESTARTS NAME Service up 0 0 oracle1_mon Subnet up 200.1.100.0 Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos003 (current) Alternate up enabled hpeos004 NODE STATUS STATE hpeos004 up running Network_Parameters: INTERFACE STATUS PATH NAME PRIMARY up 0/0/0/0 lan0 STANDBY up 0/2/0/0/4/0 lan1 UNOWNED_PACKAGES PACKAGE STATUS STATE AUTO_RUN NODE clockwatch down halted disabled unowned Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover min_package_node Failback manual Script_Parameters: ITEM STATUS NODE_NAME NAME Subnet up hpeos003 200.1.100.0 Subnet up hpeos004 200.1.100.0 Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos003 Alternate up enabled hpeos004 root@hpeos003[]
28.3.6 Prepare the Continentalclusters security files There are two additional security files that we need to support Continentalclusters. The first is ~root/.rhosts . Before you start worrying about the security problems of ~root/.rhosts , I know this is less than ideal but we only need this file while we use a command cmapplyconcl . Once complete, we can remove ~root/.rhosts . The other security file is /etc/opt/cmom/cmomhosts . This file allows nodes that are running monitor packages to obtain information from other nodes about the health of each cluster. The file must contain entries that allow access to all nodes in the Continentalclusters by the nodes where monitor packages are running. The format of the cmomhosts file is not the same as .rhosts . The basic format is:
allow/deny <nodename>
Whether we use allow or deny is based on the order directive at the beginning of the file. Here is a typical example (the one I am using):
order allow,deny allow from hpeos001 allow from hpeos002 allow from hpeos003 allow from hpeos004
Ensure that both files exist on all nodes in both clusters. 28.3.7 Edit and apply the Continentalclusters monitor package The monitor package will start the necessary daemons on all nodes in all the participating clusters. The main Continentalclusters daemon is cmomd . This process communicates with the Serviceguard daemon cmcld to establish status of the primary and recovery clusters. On the recovery cluster, we will also see the processes cmclsentryd and cmclrmond that monitor the state of the clusters participating in the Continentalclusters configuration and communicate their state through the EMS interface. The default behavior is to start the package as soon as the recovery cluster is activated, i.e., AUTO_RUN is set to YES . This is different from all other Continental packages, but it should be apparent that it is good that we automatically start monitoring the state of the Continentalclusters as soon as the recovery cluster is up and running. Here are the steps involved in setting up the monitor package: -
The Continentalclusters monitor package will detect a failure of the primary cluster. In order to poll the status of the primary cluster, we set up a monitoring package on the recovery cluster. The files needed to set up this package are installed with the Continentalclusters software. They reside under the directory /opt/cmconcl/scripts : root@hpeos003[scripts] # pwd /opt/cmconcl/scripts root@hpeos003[scripts] # ll total 62 -r-xr-xr-x 1 bin bin 20543 Feb 11 2002 ccmonpkg.cntl -r--r--r-- 1 bin bin 9930 Feb 11 2002 ccmonpkg.config root@hpeos003[scripts] # They should be copied to the directory /etc/cmcluster/ccmonpkg , which is created by installing the Continentalclusters software, but the directory is empty: root@hpeos003[scripts] # ll /etc/cmcluster/ccmonpkg total 0 root@hpeos003[scripts] # cp -p * /etc/cmcluster/ccmonpkg root@hpeos003[scripts] # ll /etc/cmcluster/ccmonpkg total 62 -r-xr-xr-x 1 bin bin 20543 Feb 11 2002 ccmonpkg.cntl -r--r--r-- 1 bin bin 9930 Feb 11 2002 ccmonpkg.config root@hpeos003[scripts] # -
Edit the ccmonpkg.config file. This file needs little modification; usually, it is just the list of the nodes in the recovery cluster that need to be updated. The default package name is ccmonpkg . I can't think of a good reason to change it: root@hpeos003[ccmonpkg] # pwd /etc/cmcluster/ccmonpkg root@hpeos003[ccmonpkg] # grep '^[^#]' ccmonpkg.config PACKAGE_NAME ccmonpkg FAILOVER_POLICY CONFIGURED_NODE FAILBACK_POLICY MANUAL NODE_NAME hpeos003 NODE_NAME hpeos004 RUN_SCRIPT /etc/cmcluster/ccmonpkg/ccmonpkg.cntl RUN_SCRIPT_TIMEOUT NO_TIMEOUT HALT_SCRIPT /etc/cmcluster/ccmonpkg/ccmonpkg.cntl HALT_SCRIPT_TIMEOUT NO_TIMEOUT SERVICE_NAME ccmonpkg.srv SERVICE_FAIL_FAST_ENABLED NO SERVICE_HALT_TIMEOUT 300 PKG_SWITCHING_ENABLED YES NET_SWITCHING_ENABLED YES NODE_FAIL_FAST_ENABLED NO root@hpeos003[ccmonpkg] # As you can see, the SERVICE_NAME has been set up for us and the package control script is already established. The service process is a daemon /usr/lbin/cmclsentryd that is part of the Continentalclusters software: root@hpeos003[ccmonpkg] # grep '^SERVICE' ccmonpkg.cntl SERVICE_NAME[0]="ccmonpkg.srv" SERVICE_CMD[0]="/usr/lbin/cmclsentryd" SERVICE_RESTART[0]="-r 20" root@hpeos003[ccmonpkg] # -
If you are aiming to provide mutual recovery, you need to build the monitoring package on the primary clusters as well.
-
Distribute the package control script to the other nodes in the recovery cluster: root@hpeos003[ccmonpkg] rcp ccmonpkg.cntl hpeos004:$PWD root@hpeos003[ccmonpkg] -
Check and apply the monitoring package: root@hpeos003[ccmonpkg] cmcheckconf -v -k -P ccmonpkg.config Checking existing configuration ... Done Gathering configuration information ... Done Parsing package file: ccmonpkg.config. Attempting to add package ccmonpkg. Maximum configured packages parameter is 10. Configuring 3 package(s). 7 package(s) can be added to this cluster. Adding the package configuration for package ccmonpkg. Verification completed with no errors found. Use the cmapplyconf command to apply the configuration. root@hpeos003[ccmonpkg] cmapplyconf -v -k -P ccmonpkg.config Checking existing configuration ... Done Gathering configuration information ... Done Parsing package file: ccmonpkg.config. Attempting to add package ccmonpkg. Maximum configured packages parameter is 10. Configuring 3 package(s). 7 package(s) can be added to this cluster. Modify the package configuration ([y]/n)? y Adding the package configuration for package ccmonpkg. Completed the cluster update. root@hpeos003[ccmonpkg] cmviewcl -v -p ccmonpkg UNOWNED_PACKAGES PACKAGE STATUS STATE AUTO_RUN NODE ccmonpkg down halted disabled unowned Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover configured_node Failback manual Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos003 Alternate up enabled hpeos004 root@hpeos003[ccmonpkg] -
Do not start the package until we have set up the Continentalclusters configuration files.
28.3.8 Edit and apply the Continentalclusters configuration file We have several commands that look similar to commands we used to create a normal Serviceguard cluster. Obviously in this instance, we have a bit more information to include when setting up Continentalclusters but the ideas are somewhat similar. We can use any node in either cluster to set up the initial ASCII templates: -
Create an ASCII template file: root@hpeos001[cmcluster] # pwd /etc/cmcluster root@hpeos001[cmcluster] # cmqueryconcl -C cmconcl.config root@hpeos001[cmcluster] # -
Update the ASCII template with three main categories of information: I list and explain the changes I made to the default ASCII template: -
Cluster information: CONTINENTAL_CLUSTER_NAME WorldWide CLUSTER_NAME London #CLUSTER_DOMAIN NODE_NAME hpeos001 NODE_NAME hpeos002 #MONITOR_PACKAGE_NAME ccmonpkg #MONITOR_INTERVAL 60 SECONDS CLUSTER_NAME Frankfurt #CLUSTER_DOMAIN NODE_NAME hpeos003 NODE_NAME hpeos004 MONITOR_PACKAGE_NAME ccmonpkg MONITOR_INTERVAL 60 SECONDS As you can see, we have given the Continentalclusters a name that is meaningful to us; maybe you'll use your company name, or you can just keep the default of ccluster1 if you wish. You will notice above that I have defined the MONITOR_PACKAGE_NAME only in the Frankfurt cluster. The Frankfurt cluster is my recovery cluster. The MONITOR_INTERVAL is important because this is how often the monitor will attempt to obtain information relating to the status of the cluster. -
Recovery groups: A Recovery Group is a set of Serviceguard packages that are ready to recover applications in case of a cluster failure. Recovery Groups allow one cluster in the Continentalclusters configuration to back up another member cluster's packages. We would need to create a separate Recovery Group for each Serviceguard package that will be started on the recovery cluster when the cmrecovercl command is issued. If we are using logical data sender/receiver packages, we will list them as part of the definition for a Recovery Group. Members of a Recovery Group are defined by the cluster name, a slash ("/"), and the package name. Here is the entry for my package: RECOVERY_GROUP_NAME clockwatch PRIMARY_PACKAGE London/clockwatch # DATA_SENDER_PACKAGE RECOVERY_PACKAGE Frankfurt/clockwatch # DATA_RECEIVER_PACKAGE -
Monitoring definitions : This is where you may need to spend a bit more time with this configuration file. Each monitoring definition specifies a cluster event and an associated message that should be sent to IT staff. Well-planned monitoring definitions will help in making the decision on whether to use the cmrecovercl command. A monitoring definition is made up of a number of components: Cluster Conditions are the states of a cluster that is being monitored . A change from one state to another can result in an alert , an alarm , or a notification being sent to IT staff. These conditions are monitored: UNREACHABLE : The cluster is unreachable. This occurs when the communication link to the cluster goes down, as in a WAN failure, or when the all nodes in the cluster have failed. This is a serious problem. DOWN : T he cluster is down, but nodes are responding. This will occur when the cluster is halted, but some or all of the member nodes are booted and communicating with the monitoring cluster. This needs further investigation. UP : T he cluster is up. This is good. ERROR : There is a mismatch of cluster versions or a security error. This is odd. Cluster Events are defined similar to Recovery Groups, e.g., London/UNREACHABLE . The Monitoring Cluster is simply the cluster performing the monitoring. When we define a Cluster Event, we need to think about the time since the Cluster Event was first observed . For instance, if we define a Cluster Event of London/UNREACHABLE , we may decide to send out an alert after 3 minutes. If the Event is still active, i.e., the state has not changed, we may define another alert after 5 minutes. After 10 minutes, we may be getting a little worried and hence define an alarm for the 10-minute threshold. Defining a threshold of 0 (zero) minutes means that a notification will be sent as soon as the change in state occurs. We conclude by defining whether to send an alert , or an alarm. Alerts are not intended to be serious; they are informational. For an alert, a notification is sent to IT Staff. Alarms are serious ! Alarms can only be defined for an UNREACHABLE or DOWN condition. A notification is sent to IT staff and the cmrecovercl command is enabled for execution; it is ready to go. A notification defines a message that is appended to the logfile /var/adm/cmconcl/eventlog and sent to other specified destinations, including email addresses, SNMP traps, an OpenView IT/Operatoins node, the system console, or the syslog.log file. The message string in a notification can be no more than 170 characters . In the ASCII template there are a number of blank definitions at the bottom of the file that you can customize to your own needs. Here are the Monitoring Definitions I specified: CLUSTER_EVENT London/UNREACHABLE MONITORING_CLUSTER Frankfurt CLUSTER_ALERT 0 MINUTES NOTIFICATION CONSOLE "Alert : London cluster is suddenly UNREACHABLE" NOTIFICATION SYSLOG "Alert : London cluster is suddenly UNREACHABLE" NOTIFICATION EMAIL charles.keenan@hp.com "Alert : London cluster is suddenly UNREACHABLE" CLUSTER_ALERT 1 MINUTE NOTIFICATION CONSOLE "1 minute Alert : London cluster UNREACHABLE" NOTIFICATION SYSLOG "1 minute Alert : London cluster UNREACHABLE" CLUSTER_ALERT 2 MINUTES NOTIFICATION CONSOLE "2 minute Alert : London cluster STILL UNREACHABLE" NOTIFICATION SYSLOG "2 minute Alert : London cluster STILL UNREACHABLE" NOTIFICATION EMAIL charles.keenan@hp.com "2 minute Alert : London cluster STILL UNREACHABLE" CLUSTER_ALARM 3 MINUTES NOTIFICATION CONSOLE "ALARM : 3 minute Alarm : London cluster UNREACHABLE : Recovery enabled!" NOTIFICATION SYSLOG "ALARM : 3 minute Alarm : London cluster UNREACHABLE : Recovery enabled!" NOTIFICATION EMAIL charles.keenan@hp.com "ALARM : 3 minute Alarm : London cluster UNREACHABLE : Recovery enabled!" CLUSTER_EVENT London/DOWN MONITORING_CLUSTER Frankfurt CLUSTER_ALERT 3 MINUTES NOTIFICATION CONSOLE "3 minute Alert : London cluster DOWN" NOTIFICATION SYSLOG "3 minute Alert : London cluster UNREACHABLE" CLUSTER_ALERT 5 MINUTES NOTIFICATION CONSOLE "5 minute Alert : London cluster STILL DOWN" NOTIFICATION SYSLOG "5 minute Alert : London cluster STILL DOWN" CLUSTER_ALARM 10 MINUTES NOTIFICATION CONSOLE "ALARM : 10 minute Alarm : London cluster DOWN : Recovery enabled!" NOTIFICATION SYSLOG "ALARM : 10 minute Alarm : London cluster DOWN : Recovery enabled!" NOTIFICATION EMAIL charles.keenan@hp.com "ALARM : 10 minute Alarm : London cluster DOWN : Recovery enabled!" CLUSTER_EVENT London/UP MONITORING_CLUSTER Frankfurt CLUSTER_ALERT 5 MINUTES NOTIFICATION SYSLOG "5 minute Alert : London is UP and running" CLUSTER_EVENT London/ERROR MONITORING_CLUSTER Frankfurt CLUSTER_ALERT 5 MINUTES NOTIFICATION SYSLOG "5 minute Alert : London cluster has an ERROR" CLUSTER_EVENT Frankfurt/ERROR MONITORING_CLUSTER Frankfurt CLUSTER_ALERT 5 MINUTES NOTIFICATION SYSLOG "5 minute Alert : Frankfurt cluster has an ERROR" As you can see, I am most concerned with UNREACHABLE and DOWN events; I send a notification to the system console, syslog.log , and an email to the responsible parties to inform them of this situation. Note : Ensure that your CLUSTER_ALERT/ALARM is a multiple of the MONITOR_INTERVAL that you specified in the Cluster definitions; otherwise , there is a possibility that your alerts may not be picked up. -
Check the updated ASCII template for any errors: root@hpeos001[cmcluster] # cmcheckconcl -v -C cmconcl.config Parsing the configuration file...Done Analyzing the configuration....Done Verification completed with no errors found. root@hpeos001[cmcluster] # -
Apply the configuration defined in the ASCII template file: root@hpeos001[cmcluster] # cmapplyconcl -v -C cmconcl.config Parsing the configuration file...Done Analyzing the configuration....Done Modifying the configuration..............Done Completed the continental cluster creation. root@hpeos001[cmcluster] # This will distribute a number of managed objects that are stored in the directory /etc/cmconcl/instances on all machines in both clusters: root@hpeos003[] ll /etc/cmconcl/instances/ total 112 -rw-rw-rw- 1 root root 1384 Aug 12 13:00 DRClusterCommunicationPathConnection -rw-rw-rw- 1 root root 638 Aug 12 13:01 DRClusterRecoveryConnection -rw-rw-rw- 1 root root 905 Aug 12 13:01 DRClusterStatusWatchRequest -rw-rw-rw- 1 root root 18097 Aug 12 13:01 DRConditionNotificationConnection -rw-rw-rw- 1 root root 217 Aug 12 13:00 DRContinentalCluster -rw-rw-rw- 1 root root 1334 Aug 12 13:00 DRContinentalClusterClusterContainment -rw-rw-rw- 1 root root 624 Aug 12 13:00 DRContinentalClusterPackageRecoveryGroupContainment -rw-rw-rw- 1 root root 1059 Aug 12 13:01 DRContinentalClusterWatchRequestContainment -rw-rw-rw- 1 root root 9109 Aug 12 13:01 DRNotificationMessage -rw-rw-rw- 1 root root 258 Aug 12 13:00 DRPackageRecoveryGroup -rw-rw-rw- 1 root root 1161 Aug 12 13:01 DRPackageRecoveryGroupPackageConnection -rw-rw-rw- 1 root root 315 Aug 12 12:18 DRSentryDaemon -rw-rw-rw- 1 root root 366 Aug 12 13:00 DRSentryPackageConnection -rw-rw-rw- 1 root root 6510 Aug 12 13:01 DRStatusTimeoutCondition -rw-rw-rw- 1 root root 6021 Aug 12 13:01 DRWatchConditionContainment -rw-rw-rw- 1 root root 90 Aug 12 12:18 sequence root@hpeos003[] It may be a good idea to keep a copy of the ASCII template on other machines in the Continentalclusters. Note : Now that cmapplyconcl has been run, we can now get rid of the ~root/.rhosts file, if appropriate. If we are to modify the configuration, we will need to ensure that ~root/.rhosts is put back in place; otherwise, cmapplyconcl will fail. 28.3.9 Ensure all primary packages are operating as normal We need to make sure that all packages are up and running as normal before activating Continentalclusters functionality; otherwise, we may start to receive unnecessary notifications. Be sure to check that any logical data sender/receiver packages are also running to ensure that data replication is in place. 28.3.10 Start the Continentalclusters monitor package We are now in a position to start the Continentalclusters monitoring package. In doing so, we enable all Continentalclusters functionality.
root@hpeos003[ccmonpkg] cmmodpkg -e ccmonpkg cmmodpkg : Completed successfully on all packages specified. root@hpeos003[ccmonpkg] root@hpeos003[ccmonpkg] cmviewcl -v -p ccmonpkg PACKAGE STATUS STATE AUTO_RUN NODE ccmonpkg up running enabled hpeos003 Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover configured_node Failback manual Script_Parameters: ITEM STATUS MAX_RESTARTS RESTARTS NAME Service up 20 0 ccmonpkg.srv Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos003 (current) Alternate up enabled hpeos004 root@hpeos003[ccmonpkg]
28.3.11 Validate and test the Continentalclusters configuration The first thing to do is check that our configuration is in place and all monitors are configured as we expect:
root@hpeos003[cmcluster] cmviewconcl -v CONTINENTAL CLUSTER WorldWide RECOVERY CLUSTER Frankfurt PRIMARY CLUSTER STATUS EVENT LEVEL POLLING INTERVAL London up normal 1 min CONFIGURED EVENT STATUS DURATION LAST NOTIFICATION SENT alert unreachable 0 sec -- alert unreachable 1 min -- alert unreachable 2 min -- alarm unreachable 3 min -- alert down 3 min -- alert down 5 min -- alarm down 10 min -- alert error 5 min -- alert up 5 min Tue Aug 12 15:47:54 BST 2003 PACKAGE RECOVERY GROUP clockwatch PACKAGE ROLE STATUS London/clockwatch primary up Frankfurt/clockwatch recovery down root@hpeos003[cmcluster]
As we can see, all looks well. Here are some other tests we may undertake: -
Ensure that all relevant processes are running: root@hpeos003[cmcluster] ps -ef grep -e cmom -e sentry root 5614 938 0 15:42:53 ? 0:00 /opt/cmom/lbin/cmomd -f /var/opt/cmom/cmomd.log root 5599 5578 0 15:42:49 ? 0:00 /usr/lbin/cmclsentryd root 5611 938 0 15:42:50 ? 0:00 /opt/cmom/lbin/cmomd -f /var/opt/cmom/cmomd.log root@hpeos003[cmcluster] Remember, the cmclsentryd only runs on the recovery cluster. -
Check that the cmclsentryd process is working properly. We can use the command cmreadlog to achieve this. root@hpeos003[cmcluster] /opt/cmom/tools/bin/cmreadlog -f /var/adm/cmconcl/sentryd.log Aug 12 13:59:56:[[Thread-0,5,main]]:INFO:dr.sentryd:Starting to monitor cluster London Aug 12 13:59:56:[[Thread-1,5,main]]:INFO:dr.sentryd:Starting to monitor cluster Frankfurt Aug 12 13:59:56:[[Thread-6,5,main]]:INFO:dr.sentryd:Status of Cluster Frankfurt is now up Aug 12 13:59:58:[[Thread-7,5,main]]:INFO:dr.sentryd:Status of Cluster London is now up Aug 12 14:04:56:[[Thread-16,5,main]]:INFO:dr.sentryd:Alert issued for Cluster London after 300 seconds of up status. Aug 12 14:16:16:[[Thread-0,5,main]]:INFO:dr.sentryd:Starting to monitor cluster London Aug 12 14:16:16:[[Thread-1,5,main]]:INFO:dr.sentryd:Starting to monitor cluster Frankfurt Aug 12 14:16:16:[[Thread-7,5,main]]:INFO:dr.sentryd:Status of Cluster Frankfurt is now up Aug 12 14:16:19:[[Thread-9,5,main]]:INFO:dr.sentryd:Status of Cluster London is now up Aug 12 14:21:16:[[Thread-18,5,main]]:INFO:dr.sentryd:Alert issued for Cluster London after 300 seconds of up status. Aug 12 14:43:55:[[Thread-0,5,main]]:INFO:dr.sentryd:Starting to monitor cluster London Aug 12 14:43:55:[[Thread-1,5,main]]:INFO:dr.sentryd:Starting to monitor cluster Frankfurt Aug 12 14:43:56:[[Thread-6,5,main]]:INFO:dr.sentryd:Status of Cluster Frankfurt is now up Aug 12 14:43:57:[[Thread-7,5,main]]:INFO:dr.sentryd:Status of Cluster London is now up Aug 12 14:45:43:[[Thread-0,5,main]]:INFO:dr.sentryd:Starting to monitor cluster London Aug 12 14:45:43:[[Thread-1,5,main]]:INFO:dr.sentryd:Starting to monitor cluster Frankfurt Aug 12 14:45:44:[[Thread-6,5,main]]:INFO:dr.sentryd:Status of Cluster Frankfurt is now up Aug 12 14:45:45:[[Thread-8,5,main]]:INFO:dr.sentryd:Status of Cluster London is now up Aug 12 15:42:53:[[Thread-0,5,main]]:INFO:dr.sentryd:Starting to monitor cluster London Aug 12 15:42:53:[[Thread-1,5,main]]:INFO:dr.sentryd:Starting to monitor cluster Frankfurt Aug 12 15:42:54:[[Thread-6,5,main]]:INFO:dr.sentryd:Status of Cluster Frankfurt is now up Aug 12 15:42:56:[[Thread-7,5,main]]:INFO:dr.sentryd:Status of Cluster London is now up Aug 12 15:47:54:[[Thread-16,5,main]]:INFO:dr.sentryd:Alert issued for Cluster London after 300 seconds of up status. root@hpeos003[cmcluster] -
Ensure that the monitor package will move to other nodes in the recovery cluster. The default behavior of the monitor package is to restart the package 20 times on the original node. I know of some administrators who have tested this by simply killing the cmclsentryd process. This will be detected by Serviceguard as a failure of a SERVICE_PROCESS . In trying to respawn another cmclsentryd process, this will try to spawn additional cmomd processes. In this situation, they will already be running and cmclsentryd will fail to start up. This situation will loop until we run out of restarts, and the package will move to the next node. Be very careful if you are going to kill the cmclsentryd process. These are typical errors that you will see in the sentryd.log file when processes have been inadvertently killed : Aug 12 16:37:54:[4125]:ERROR:provider.drprovider:Attempt to run multiple cmclsentryd processes Aug 12 16:37:54:[4125]:ERROR:provider.drprovider:Only one is permitted Aug 12 16:37:54:[4125]:ERROR:provider.drprovider:Permission denied Aug 12 16:37:54:[4125]:INFO:provider.drprovider:Failed to initialize sentryd, clearing table Aug 12 16:37:54:[[main,5,main]]:FATAL:dr.sentryd:Failed to initialize sentry daemon Aug 12 16:37:54:[[main,5,main]]:FATAL:dr.sentryd:SQL to localhostfailed Aug 12 16:37:54:[[main,5,main]]:FATAL:dr.sentryd:Server provider error The solution is to ensure that the ccmonpkg is halted and all cmomd processes are no longer running. Some administrators I know are reluctant to perform this test. I can understand and appreciate their fears. My view is that it would be good to perform these tests to ensure that Serviceguard is working properly and the monitor package will behave as expected. I cannot stress enough to be careful if you are going to perform this test. If you cannot get the monitor package stable, the entire Continentalclusters configuration is compromised. Here, I am testing the ccmonpkg package by killing the cmclsentryd process and associated cmomd processes: root@hpeos003[ccmonpkg] ps -ef grep -e cmom -e sentry root 7104 938 0 16:41:55 ? 0:00 /opt/cmom/lbin/cmomd -f /var/opt/cmom/cmomd.log root 7107 938 0 16:41:58 ? 0:00 /opt/cmom/lbin/cmomd -f /var/opt/cmom/cmomd.log root 7092 6764 0 16:41:51 ? 0:00 /usr/lbin/cmclsentryd root@hpeos003[ccmonpkg] kill 7104 7107 7092 root@hpeos003[ccmonpkg] root@hpeos003[ccmonpkg] cmviewcl -v -p ccmonpkg PACKAGE STATUS STATE AUTO_RUN NODE ccmonpkg up running enabled hpeos003 Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover configured_node Failback manual Script_Parameters: ITEM STATUS MAX_RESTARTS RESTARTS NAME Service up 20 1 ccmonpkg.srv Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos003 (current) Alternate up enabled hpeos004 root@hpeos003[ccmonpkg] ps -ef grep -e cmom -e sentry root 7136 938 0 16:43:47 ? 0:00 /opt/cmom/lbin/cmomd -f /var/opt/cmom/cmomd.log root 7129 938 0 16:43:43 ? 0:00 /opt/cmom/lbin/cmomd -f /var/opt/cmom/cmomd.log root 7117 6764 0 16:43:39 ? 0:00 /usr/lbin/cmclsentryd root@hpeos003[ccmonpkg] On reaching the maximum number of restarts, the package will move to the adoptive node. -
Ensure that notifications are working properly. The best way to do this is to construct a series of tests that will force a change of state in a cluster or node, e.g., shut down the WAN connection making the primary cluster UNREACHABLE or shut down the primary cluster. Be sure to plan these tests carefully. Be sure that you coordinate the tests with your colleagues in both the primary and recovery clusters. If all goes well, we should start to receive notifications once cluster events start to happen. In my configuration, I have static routes in my routing table. I will flush the routing table on the nodes in my primary cluster. I expect the monitor to lose contact with the primary cluster and to send an UNREACHABLE notification to the system console and to syslog.log immediately. root@hpeos001[] # route -f root@hpeos001[] # root@hpeos002[] # route -f root@hpeos002[] # We need to be checking the status of the Continentalclusters from both sides of the connection. From the view of the primary cluster, this is typical output from cmviewconcl : root@hpeos001[cmcluster] # cmviewconcl -v Failed to new Socket(hpeos004:5303): errno: 229, error: Network is unreachable for fd: 5 Failed to new Socket(hpeos003:5303): errno: 229, error: Network is unreachable for fd: 5 Problem communicating with hpeos003: errno: 229, error: Network is unreachable for fd: 5 Problem communicating with hpeos004: errno: 229, error: Network is unreachable for fd: 5 ERROR: Could not determine status of package clockwatch CONTINENTAL CLUSTER WorldWide RECOVERY CLUSTER Frankfurt PRIMARY CLUSTER STATUS EVENT LEVEL POLLING INTERVAL London Unmonitored unmonitored 1 min CONFIGURED EVENT STATUS DURATION LAST NOTIFICATION SENT alert unreachable 0 sec -- alert unreachable 1 min -- alert unreachable 2 min -- alarm unreachable 3 min -- alert down 3 min -- alert down 5 min -- alarm down 10 min -- alert error 5 min -- alert up 5 min -- PACKAGE RECOVERY GROUP clockwatch PACKAGE ROLE STATUS London/clockwatch primary up Frankfurt/clockwatch recovery unknown root@hpeos001[cmcluster] # You should appreciate that, from the viewpoint of the primary cluster, we are not seeing any alerts because we have lost contact with the monitor ( ccmonpkg package) running on the recovery cluster. We need to be monitoring cmviewconcl from the recovery cluster. Here is the output we see from the recovery cluster. root@hpeos003[] cmviewconcl -v WARNING: Primary cluster London is in an alert state Failed to new Socket(hpeos001:5303): Connection timed out Failed to new Socket(hpeos002:5303): Connection timed out Problem communicating with hpeos001: Connection timed out Problem communicating with hpeos002: Connection timed out ERROR: Could not determine status of package clockwatch CONTINENTAL CLUSTER WorldWide RECOVERY CLUSTER Frankfurt PRIMARY CLUSTER STATUS EVENT LEVEL POLLING INTERVAL London unreachable ALERT 1 min CONFIGURED EVENT STATUS DURATION LAST NOTIFICATION SENT alert unreachable 0 sec Tue Aug 12 17:17:24 BST 2003 alert unreachable 1 min Tue Aug 12 17:18:24 BST 2003 alert unreachable 2 min Tue Aug 12 17:19:24 BST 2003 alarm unreachable 3 min -- alert down 3 min -- alert down 5 min -- alarm down 10 min -- alert error 5 min -- alert up 5 min -- PACKAGE RECOVERY GROUP clockwatch PACKAGE ROLE STATUS London/clockwatch primary unknown Frankfurt/clockwatch recovery down root@hpeos003[] We can also check the system console, syslog.log , and any other destinations configured for notification. Here is an extract from the syslog.log file on node hpeos003 : Aug 12 17:09:24 hpeos003 EMS [7249]: ------ EMS Event Notification ------ Value: " 0" for Resource: "/cluster/concl/WorldWide/clusters/London/status/unreachable" (Threshold : = " 0") Execute the following command to obtain event de tails: /opt/resmon/bin/resdata -R 475070467 -r cluster/concl/WorldWide/clusters/London /status/unreachable a Executing the resdata command listed in the EMS notification produced the following output: root@hpeos003[] /opt/resmon/bin/resdata -R 475070467 -r /cluster/concl/WorldWide/clusters /London/status/unreachable a USER DATA: Cluster "London" has status "unreachable" for 0 sec Alert : London cluster is suddenly UNREACHABLE resdata: There is no monitor data associated with this event root@hpeos003[] Reestablishing the WAN connection should reestablish communication between the primary and recovery clusters. We should see this in the output from cmviewconcl : root@hpeos003[] cmviewconcl -v CONTINENTAL CLUSTER WorldWide RECOVERY CLUSTER Frankfurt PRIMARY CLUSTER STATUS EVENT LEVEL POLLING INTERVAL London up normal 1 min CONFIGURED EVENT STATUS DURATION LAST NOTIFICATION SENT alert unreachable 0 sec -- alert unreachable 1 min -- alert unreachable 2 min -- alarm unreachable 3 min -- alert down 3 min -- alert down 5 min -- alarm down 10 min -- alert error 5 min -- alert up 5 min Tue Aug 12 17:32:32 BST 2003 PACKAGE RECOVERY GROUP clockwatch PACKAGE ROLE STATUS London/clockwatch primary up Frankfurt/clockwatch recovery down root@hpeos003[] Again, we should get notification that the primary cluster is up. Here is the EMS notification that I received in my syslog.log file: Aug 12 17:32:32 hpeos003 EMS [7249]: ------ EMS Event Notification ------ Value: " 300" for Resource: "/cluster/concl/WorldWide/clusters/London/status/up" (Threshold: = " 300") Execute the following command to obtain event details: /opt/resmon/bin/resdata -R 475070501 -r /cluster/concl/WorldWide/clusters/London/status/up a root@hpeos003[] /opt/resmon/bin/resdata -R 475070501 -r /cluster/concl/WorldWide/clusters /London/status/up a USER DATA: Cluster "London" has status "up" for 300 sec 5 minute Alert : London is UP and running resdata: There is no monitor data associated with this event root@hpeos003[] The alarms and alerts are also recorded in the file /var/adm/cmconcl/cmconcl/eventlog . We can monitor this file during these tests as well. root@hpeos003[] tail -15 /var/adm/cmconcl/eventlog >------------ Event Monitoring Service Event Notification ------------< Notification Time: Tue Aug 12 17:32:32 2003 hpeos003 sent Event Monitor notification information: /cluster/concl/WorldWide/clusters/London/status/up is = 300. User Comments: Cluster "London" has status "up" for 300 sec 5 minute Alert : London is UP and running >---------- End Event Monitoring Service Event Notification ----------< root@hpeos003[] -
Ensure that you perform extensive testing of the individual Continental packages within their own cluster. As part of setting up the recovery cluster, we considered running the Continental packages on the recovery cluster. Once you are happy that packages are running as expected in a stable configuration, you should consider performing a full-blown test whereby we move the Continental package(s) to the recovery cluster. We are going to use the command cmrecovercl . This command will work only when the primary cluster is DOWN or UNREACHABLE . To facilitate, I will halt the primary cluster. This is important to ensure that the Continental package(s) are not running on the primary cluster . root@hpeos001[] # cmhaltpkg clockwatch cmhaltpkg : Completed successfully on all packages specified. root@hpeos001[] # cmhaltcl -v Disabling package switching to all nodes being halted. Disabling all packages from running on hpeos001. Disabling all packages from running on hpeos002. Warning: Do not modify or enable packages until the halt operation is completed. This operation may take some time. Halting cluster services on node hpeos002. Halting cluster services on node hpeos001. .. Successfully halted all nodes specified. Halt operation complete. root@hpeos001[] # We should wait until the monitor enables the cmrecovercl command; this is the time we configured for the CLUSTER_EVENT . In my case, that would be 10 minutes before the DOWN event triggers an ALARM . After 3 and 5 minutes, I should receive an ALERT : root@hpeos003[] tail -15 /var/adm/cmconcl/eventlog >------------ Event Monitoring Service Event Notification ------------< Notification Time: Tue Aug 12 17:59:32 2003 hpeos003 sent Event Monitor notification information: /cluster/concl/WorldWide/clusters/London/status/down is = 300. User Comments: Cluster "London" has status "down" for 300 sec 5 minute Alert : London cluster STILL DOWN >---------- End Event Monitoring Service Event Notification ----------< Once we reach the 10-minute threshold, we can issue the cmrecovercl command. If you do not want to wait for the threshold to expire, you can use the “f to cmrecovercl command. We can see that my Continentalclusters are now in an alarm state: root@hpeos003[] cmviewconcl -v WARNING: Primary cluster London is in an alarm state (cmrecovercl is enabled on recovery cluster Frankfurt) CONTINENTAL CLUSTER WorldWide RECOVERY CLUSTER Frankfurt PRIMARY CLUSTER STATUS EVENT LEVEL POLLING INTERVAL London down ALARM 1 min CONFIGURED EVENT STATUS DURATION LAST NOTIFICATION SENT alert unreachable 0 sec -- alert unreachable 1 min -- alert unreachable 2 min -- alarm unreachable 3 min -- alert down 3 min Tue Aug 12 17:57:32 BST 2003 alert down 5 min Tue Aug 12 17:59:32 BST 2003 alarm down 10 min Tue Aug 12 18:04:32 BST 2003 alert error 5 min -- alert up 5 min -- PACKAGE RECOVERY GROUP clockwatch PACKAGE ROLE STATUS London/clockwatch primary down Frankfurt/clockwatch recovery down root@hpeos003[] root@hpeos003[] tail -15 /var/adm/cmconcl/eventlog >------------ Event Monitoring Service Event Notification ------------< Notification Time: Tue Aug 12 18:04:32 2003 hpeos003 sent Event Monitor notification information: /cluster/concl/WorldWide/clusters/London/status/down is = 600. User Comments: Cluster "London" has status "down" for 600 sec ALARM : 10 minute Alarm : London cluster DOWN : Recovery enabled! >---------- End Event Monitoring Service Event Notification ----------< root@hpeos003[] I am now going to attempt to move the clockwatch package to the recovery cluster. This will test the Continentalclusters configuration as well as the data replication setup. I will run cmrecovercl on any node in the recovery cluster. How the package is configured in the Frankfurt cluster determines which node the clockwatch package runs on. root@hpeos003[] cmrecovercl WARNING: This command will take over for the primary cluster London by starting the recovery package on the recovery cluster Frankfurt. You must follow your site disaster recovery procedure to ensure that the primary packages on London are not running and that recovery on Frankfurt is necessary. Continuing with this command while the applications are running on the primary cluster may result in data corruption. Are you sure that the primary packages are not running and will not come back, and are you certain that you want to start the recovery packages [y/n]? y cmrecovercl: Attempting to recover cluster Frankfurt Processing the recovery group clockwatch on recovery cluster Frankfurt Enabling recovery package clockwatch on recovery cluster Frankfurt Enabling switching for package clockwatch. Successfully enabled package clockwatch. cmrecovercl: Completed recovery process for each recovery group. Use cmviewcl to verify that the recovery packages are successfully starting. root@hpeos003[] We will confirm that the clockwatch package is running by simply using cmviewcl : root@hpeos003[] cmviewcl -v -p clockwatch PACKAGE STATUS STATE AUTO_RUN NODE clockwatch up running enabled hpeos004 Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover min_package_node Failback manual Script_Parameters: ITEM STATUS MAX_RESTARTS RESTARTS NAME Service up 0 0 clock_mon Subnet up 200.1.100.0 Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos003 Alternate up enabled hpeos004 (current) root@hpeos003[] We can see that clockwatch is up and running on node hpeos004 . This is because we configured clockwatch to use the FAILOVER policy of MIN_PACKAGE_NODE and node hpeos003 is currently running the oracle1 package. -
We could continue running the packages on the recovery cluster indefinitely. If we recover the original cluster, we can reintroduce it into the Continentalclusters configuration. If the failure was a catastrophic failure of the entire data center, it may take some time to recover the original nodes to their original state; we will need to reinstall Serviceguard, Continentalclusters, all relevant patches, and application software. Once ready, we can reintroduce the nodes into the Continentalclusters configuration by following this process: -
Halt the monitor package: # cmhaltpkg ccmonpkg -
Edit the ASCII Continentalclusters configuration file to ensure that the cluster, recovery group, and notification definitions are correct. -
Check and apply the configuration: # cmcheckconcl -v -C cmconcl.config # cmapplyconcl -v -C cmconcl.config -
Restart the monitor package: # cmmodpkg e ccmonpkg -
Check that the configuration is up and running: # cmviewconcl -
Ensure that we can move the Continental package back to the original node by: -
Halting the package on the recovery cluster. root@hpeos003[clockwatch] cmhaltpkg clockwatch cmhaltpkg : Completed successfully on all packages specified. -
Ensuring that the package is disabled from running on the recovery cluster. root@hpeos003[clockwatch] cmviewcl -v -p clockwatch UNOWNED_PACKAGES PACKAGE STATUS STATE AUTO_RUN NODE clockwatch down halted disabled unowned Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover min_package_node Failback manual Script_Parameters: ITEM STATUS NODE_NAME NAME Subnet up hpeos003 200.1.100.0 Subnet up hpeos004 200.1.100.0 Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos003 Alternate up enabled hpeos004 root@hpeos003[clockwatch] -
Ensuring that data replication is reversed to the original cluster. This may take some time, and you need to ensure that the data is consistent and current. You may need to attempt to run the application out of the Serviceguard configuration to ensure that there is no corruption in the data. -
Start the package back on the original cluster. root@hpeos001[] # cmmodpkg -e clockwatch cmmodpkg : Completed successfully on all packages specified. root@hpeos001[] # cmviewcl -v -p clockwatch PACKAGE STATUS STATE AUTO_RUN NODE clockwatch up running enabled hpeos001 Policy_Parameters: POLICY_NAME CONFIGURED_VALUE Failover configured_node Failback manual Script_Parameters: ITEM STATUS MAX_RESTARTS RESTARTS NAME Service up 0 0 clock_mon Subnet up 192.168.0.0 Node_Switching_Parameters: NODE_TYPE STATUS SWITCHING NAME Primary up enabled hpeos001 (current) Alternate up enabled hpeos002 root@hpeos001[] # 28.3.12 Other Continentalclusters tasks There are various other tasks that we could perform within this configuration; we could add and delete nodes and packages. The concepts are similar for adding nodes and packages within a simple Serviceguard cluster. I will not go through these tasks here. Here's the basic sequence of events: -
Halt the monitor package.
-
Edit the ASCII Continentalclusters configuration.
-
Check and apply the configuration.
-
Restart the monitor package.
-
Check that the configuration is up and running.
There are other commands like cmdeletconcl , cmforceconcl , to name but a few. The tasks we have performed are the tasks we will get involved in on a day-to-day basis. I will ask you to explore these other commands at your own leisure. |