Framing the Problem
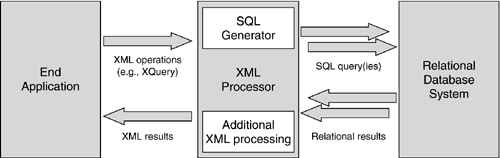
| In theory, we could discuss the mapping between XML and relational data without reference to the applications that will use such a mapping or how those applications might be implemented. However, these factors have implications for the type of mapping chosen ”one may want or be constrained to choose a different mapping technique based on the actual requirements of a particular application. In particular, we consider XQuery as one particular type of application, one that places certain requirements on how to map between XML and relational data. We also consider other types of applications that have fewer or additional requirements. Processing ModelsWe will begin by discussing at a high level the processing models that might be used to implement an XML application on top of a relational database. One straightforward processing model layers an XML application on top of an SQL database. In this case, the SQL database itself remains unchanged, and the XML application is implemented via some combination of SQL statements and additional XML-focused processing. Figure 6.1 shows this processing model schematically. Figure 6.1. Layered Processing Model for XML Applications There are several ways to divide the boxes in Figure 6.1:
The main alternative to a layered approach is one in which the relational database is extended to provide native XML functionality. In this case, the architecture may still somewhat resemble that shown in Figure 6.1 (except with the XML processor embedded in and accessed from within the overall relational architecture), or we may use an entirely different architecture, in which the XML and relational functionality are mingled together. These alternatives are discussed in Chapter 7. In this chapter, we generally assume the middle-tier version of the model shown in Figure 6.1. This model is sufficient to cover most issues relating to mapping between XML and relational data; we intend to highlight areas where the choice of a processing model affects the mapping. Issues that arise particularly in a native implementation are discussed in Chapter 7. Application TypesWe characterize types of applications by what basic sorts of operations they have to perform on XML data: extract, transform, and so forth. Significant variation may exist within each application type, based on the particular languages (XQuery, XPath, etc.) used and especially on the richness of the set of specific available operations. Emitting XML DocumentsThe most basic application type simply returns an XML document or documents. In this case the relational database is merely acting as a repository for some set of XML documents. The emitted XML document might be used directly by some application, or it might be further processed. For example, the document might be further processed with XSL to transform it for display in a web portal. Selecting and Emitting XML FragmentsThe application type that selects and returns XML fragments is characterized by the XPath language, which returns nodes from within an XML document that match specified conditions. The key requirements are the ability to "reach into" the document to access individual elements, attributes, and their values, both in order to evaluate predicate conditions and to extract the node contents. A trivial way to implement this application type would be to emit all XML documents (using the application type above), and then in a post-processing step, evaluate the conditions and output only the requested portion of the document or documents. However, this would generally be inefficient, since it could require emitting all the XML documents in order to ultimately retrieve only one or a few documents or document fragments. Thus our main goal for this type of application is to find a way to push the selection and extraction criteria into the database, using the database to perform these operations for us. This is a common theme throughout this chapter: Whenever possible we want to make the relational database engine perform the kind of work it is good at, rather than repeating this work externally. Querying or Transforming XML DocumentsQuerying and transforming are often considered to be different operations, but in terms of the requirements they place on mapping between XML and relational data, they are quite similar. XQuery is the most general example of this kind of application. As we have seen, XQuery has very powerful ways to navigate, select, combine, transform, sort , and aggregate XML data. The output of a query in XQuery may have no structural resemblance to the XML source: elements can be renamed and rearranged, and the data can be transformed by functions. An XQuery query may combine data from multiple XML input documents to create a single output. XQuery is the most obvious example of a query-and-transform language, but it is not the only one. XSL also performs querying and transformation. And some applications may use their own query or transform definitions; this may especially be appropriate if the needs of the application are much simpler than full XQuery and a general-purpose XQuery implementation is not available. In all cases, the defining characteristic of applications in this class is the ability to both select and combine individual pieces of the XML input in complex ways, creating new XML structures that may not have existed in the input. As for the "select and extract" application type, it is possible to implement XQuery by first emitting entire XML documents and then post-processing them with a generic XQuery processor. (And similarly for any other query or transform language.) But the more interesting approach is again to push as much of the XQuery processing into the database as possible, in essence translating from XQuery to SQL or an extended language such as SQL/XML. Updating XML DocumentsAll of the above application types are read-only: The application processes an XML document and transmits the result of that processing to some other client application. There are fundamental changes when the application must also update the XML document in place. The most significant new requirement that arises with update is the ability to correctly identify individual nodes within XML documents. For example, if the application needs to change the value of an attribute from owner='sam' to owner='bob' , it is not sufficient to find some attribute owner whose value is sam and change the value to bob ; it must be the specific attribute referenced by the client. In order to implement this requirement, the client application must have some way to name which node it wishes to modify. There are three general approaches:
The addressing approach tends to increase complexity in the client (which has to generate the addresses), but it still enables the communication channel between the client and the database to consist of serialized XML, which can be easier to implement than a rich API, particularly in a loosely coupled environment. When either the addressing or API approaches are used, update requires the ability to translate either an address or node handle into a location or locations in the database. Another issue that arises with update is the addition of transactions and locking to the picture, and the need to coordinate these with the underlying SQL engine. Some of the issues involved are addressed in Chapter 7. Unlike the previous application types, the actual update operations on XML documents must finally be implemented entirely within the database, either directly by the database vendor, or by translation of the update operations to SQL ”post-processing cannot help here. The middle tier is used differently in this case: It translates a set of updates against an XML document into a set of update operations on the relational database. The translation process can be quite complex: for example, computing the difference between an updated XML document and its previous version to generate a list of SQL updates, or batching a set of changes into a single update. Within the class of applications that update XML documents, there is one additional distinction that is very important: Does the application require the ability to change the XML schema of the document? Changing the schema of the document (or equivalent scenarios, such as changing the structure of a document that either has no schema or has a schema that uses the xs:any construct) can greatly increase the complexity of mapping techniques, and rules out some of them altogether. Sources of XML DataThe other major dimension we must consider is the source of XML data that our applications wish to process. Relational SourcesIn some cases, the original data is actually relational: data stored in tables and columns of the relational database, and generally created and maintained by some relational application. In this situation, we assume that our XML application needs to access this data as if it were XML. We call this general model a virtual XML view of relational data. XML SourcesXML documents may be the original input data. They might be manually created in an XML editor or created by an XML-based application; for example, they might be received from a B2B (Business-to-Business) application. The originating application might also operate directly on the XML stored within a relational database; for example, an XML editor might store the documents that it manages in a relational database. In this case, we have options to consider regarding how to store the XML within the relational database. The category of XML sources includes several important subcategories : XML may be structured, semi-structured, or marked -up text, and the XML may either have a given schema (or DTD), variable schemas, or no schema. Terms like structured and semi-structured have different definitions in the literature; in this chapter, semi-structured XML may have variant substructure (corresponding to the use of union types, xs:choice , or repeating groups), while structured XML does not. As a rule of thumb, it is possible to navigate a structured XML document without examining the document content (e.g., the first child element of the second child element of the root will always be an address element). Marked-up text uses mixed element content and has the additional challenge that logical units of text (such as sentences) may span multiple elements. Many applications manipulate documents with only a single given schema or DTD. Other applications require the ability to interchangeably manipulate documents with different schemas or change the schema of a given document from time to time as the document is updated. In general, structured or semi-structured XML with a given schema is the easiest to handle, and the other alternatives all significantly increase the complexity of mapping between XML and relational data. |
EAN: 2147483647
Pages: 102