5.4 THE LR PARSER
5.3 IMPLEMENTATION
A convenient way to implement a bottom-up parser is to use a shift-reduce technique: a parser goes on shifting the input symbols onto the stack until a handle comes on the top of the stack. When a handle appears on the top of the stack, it performs reduction. This implementation makes use of a stack to hold grammar symbols and an input buffer to hold the string w to be parsed, which is terminated by the right endmarker $, the same symbol used to mark the bottom of the stack. The configuration of the parser is given by a token pair-the first component of which is a stack content, and second component is an unexpended input.
Initially, the parser will be in the configuration given by the pair ($, w $); that is, the stack is initially empty, and the buffer contains the entire string w . The parser shifts zero or more symbols from the input on to the stack until handle ± appears on the top of the stack. The parser then reduces ± to the left side of the appropriate production. This cycle is repeated until the parser either detects an error or until the stack contains a start symbol and the input is empty, giving the configuration ($S, $). If the parser enters ($S, $), then it announces the successful completion of parsing. Thus, the primary operation of the parser is to shift and reduce.
For example consider the bottom-up parser for the grammar having the productions :
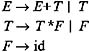
and the input string: id+id * id. The various steps in parsing this string are shown in Table 5.3 in terms of the contents of the stack and unspent input.
| Stack Contents | Input | Moves |
|---|---|---|
| $ | id + id*id$ | shift id |
| $id | + id*id$ | reduce by F ’ id |
| $ F | + id*id$ | reduce by T ’ F |
| $ T | + id*id$ | reduce by E ’ T |
| $ E | + id*id$ | shift + |
| $ E + | id*id$ | shift id |
| $ E + id | *id$ | reduce by F ’ id |
| $ E + F | *id$ | reduce by T ’ F |
| $ E + T | *id$ | shift * |
| $ E + T | * id$ | shift id |
| $ E + T *id | $ | reduce by F ’ id |
| $ E + T * F | $ | reduce by T ’ T * F |
| $ E + T | $ | reduce by E ’ E + T |
| $ E | $ | accept |
Shift-reduce implementation does not tell us anything about the technique used for detecting the handles; hence, it is possible to make use of any suitable technique to detect handles. Depending upon the technique that is used to detect handles, we get different shift-reduce parsers. For example, an operator-precedence parser is a shift-reduce parser that uses the precedence relationship between certain pairs of terminals to guide the selection of handles. Whereas LR parsers make use of a deterministic finite automata that recognizes the set of all viable prefixes; by reading the stack from bottom to top, it determines what handle, if any, is on the top of the stack.
EAN: 2147483647
Pages: 108