6.8 IO STREAMS FOR C
|
6.8 I/O STREAMS FOR C++
It is frequently the case in programming of any sort that you'd want to write data to a file, a socket, or memory. It is also frequently the case that you'd want to read data from such resources. In C++ and Java, data I/O is carried out with streams. You open a stream to the destination to which you want to write the data. You open a stream to the source from where you want to bring in the information. In this section, we will discuss how one sets up streams when the data consists of the primitive types and of type string, as is true in a vast majority of cases.
6.8.1 The C++ Stream Hierarchy
Shown in Figure 6.2 is the hierarchy of stream classes in C++, where the dashed arrows indicate that ios serves as a virtual base[13] for the derived classes istream and ostream. The solid arrows indicate regular class derivations.[14]
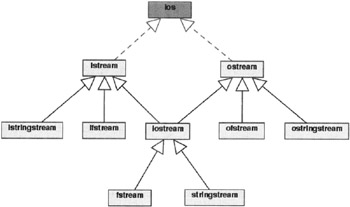
Figure 6.2
Of the classes shown, input operations are supported by classes of type istream and output operations by classes of type ostream. The subclass iostream, which inherits from both istream and ostream, provides operations for both input and output.
6.8.2 Input-Output Operations for Character Streams
Let's say you want to open a file named invoice. dat for writing text into, you would create a stream object of type ofstream by
ofstream out("invoice.dat"); if (!out ) print_error( "cannot open output file" ); where the identifier out is the name chosen for the output stream object and where print_error is your own print function for displaying error messages.
Using the system-provided overload definitions for the insertion operator‘<<', our program could now contain statements like
int x = 1234; out << x << " " << 56.78 << " " << "apples" << '\n';
which would cause the character string
1234 56.78 apples
to be written out into the file invoice.dat. You must, of course, include the header fstream for this to work since the class ofstream is declared in that header file. When you construct an ofstream object in the manner shown, the file named as the argument will be created by default if it does not exist already. If the file existed previously, its contents would be overwritten starting at the beginning. If you wish to append to a file already in existence, you'd need to make the following invocation of the ofstream constructor:
ofstream out("invoice.dat", ios::app); Now suppose you want to read the contents of the file invoice.dat back into a program. You'd need to create an input stream object, as in line (A) below, and to then use the extraction operator ‘>>' to read off the various items in the file into appropriate variables, as in lines (B), (C), and (D);
int x; double y; string z; ifstream in( "invoice.dat" ); //(A) if ( !in ) error( "cannot open input file" ); in >> x; //(B) in >> y; //(C) in >> z; //(D) cout << x << " " << y << " " << z << '\n'; //(E)
The input file stream object in will fetch information from the designated file and the extraction operator '>>' will do formatted extractions of the expected data types from this information. The system-supplied overload definition for the extraction operator will cause the statement in line (B) to extract an int from the input stream object and make that integer the value of the variable x. Since the first item in the file is the integer 1234 stored as a text string, this integer becomes the value of x in line (B). By the same token, the next item in the file, the floating-point number 56.78, will be "read into" the double variable y in line (C). And exactly the same mechanism will cause the third item in the file, the string "apples," to be read into the string variable z. The extraction operator will, by default, skip over the white spaces (blanks, tabs, newlines, and so on) between the different entries in the file. The header fstream would again have to be included in your program since that's where the class ifstream is declared.
As was mentioned earlier in Chapter 2, cout used in the above code fragment in line (E) is also a stream object, of type ostream, that represents the standard output. The output from cout would ordinarily be directed to a user's terminal. In the same vein, we have cin, a stream object of type istream, that represents the standard input; cin would ordinarily be directed to fetch information from a user's terminal. And we have cerr, a stream object of type ostream, for outputing a program's error messages. The object cerr represents the standard error; its output would also ordinarily be directed to a user's terminal. All three standard streams can be independently redirected by the operating system.
If you want a stream that can be used for both reading and writing, you need to construct an fstream object, again supplied by the header file fstream:[15]
fstream inout( "invoice.dat", ios::in | ios::out ); if ( !inout ) print_error( "file could not be opened" );
where we chose inout for the name of the stream object. It is the specification in the second argument, consisting of a disjunction, that indicates to the system that the designated file must be simultaneously opened in two modes, read and write. When using such streams, you have to pay careful attention to what is known as a file position or file pointer. Each open file has two positions associated with it:
-
The current file position for reading a byte. This is the index of the byte that will be read by the next call to a method such as get. When a byte is read, this file position, also referred to as the get position, moves past that byte.
-
The current file position for writing a byte. This is the index of the location where the next byte will be placed by a function such as put. When a byte is written into a file, this position, also referred to as put position, moves past that byte.
The get and the put positions should be independently variable. That is, either one should be able to point anywhere in a file. But a particular compiler implementation may or may not permit that. In general, the file positions can be controlled by invoking the seekp function for the put position and the seekg function for the get position. We get the current positions by invoking tellg() for the get position and tellp() for the put position.
Shown below is a demonstration program that shows the workings of the file-position-related functions mentioned above. Line (A) opens the designated file in read/write mode. Line (B) deposits a 20-character long string into the file. Subsequently, when we check the get and the put positions in lines (C) and (D), we get 21 for both with the compiler that was used (g++ version 2.96). We then reset the get position to the beginning of the file in line (E). Later, when we check the two positions in lines (F) and (G), we get the same answer-0. Further proof of the fact that the get position is now at the beginning of the file is obtained by reading the contents of the file into the three variables x, y and z in lines (H) and (I). As verified by the output produced by line (J), we are indeed able to read all three values correctly.
//TestFilePosition.cc #include <fstream> #include <string> using namespace std; int main() { fstream inout( "invoice.dat", ios::in | ios::out ); //(A) //write to the file: inout << 1234 << " " << 56.78 << " " << "apples" <<'\n'; //(B) //current get position: cout << inout.tellg() << endl; // 21 //(C) //current put position: cout << inout.tellp() << endl; //21 //(D) //reset get position to the beginning of the file: inout.seekg( ios::beg ); //(E) //new get position: cout << inout.tellg() << endl; //0 //(F) //new put position: cout << inout.tellp() << endl; //0 //(G) int x; double y; string z; //read from file: inout>> x >> y; //(H) inout >> z; //(I) cout << x << " " << y << " " << z << endl; //(J) //1234 56.78 apples return 0; }
Other useful stream functions dealing with file positions include the two-arg versions of seekg and seekp that allow the position of a stream to be set relative to some other position. The use of the two-arg version of seek is illustrated by the following version of the above program. The code shown in lines (K) through (Q) of the new version replaces the declarations of the variables x, y, and z and the lines (H)-(J) of the previous program. The previous program straightforwardly read the three items stored in the file into the three variables in lines (H) and (I). In the version below, after reading the first datum, we use the 2-argument version of seekg in line (O) to make the get position hop over the middle item in the file. In the two-arg version of seek, the first argument is the offset to be used with respect to the position specified in the second argument. The second argument can be either ios: :beg, or ios: : cur, or ios:: end, for the beginning of the file, the current position in the file, and the end of the file, respectively. Whereas the cout statement in line (J) of TestFilePosition1. cc prints on the terminal
1234 56.78 apples
the same statement in line (Q) of the program below prints out
1234 O apples
because we read into the variable z after the stream is moved 8 positions to the right in line (O), which causes it to skip over the floating-point datum in the middle.
//TestFilePosition2.cc #include <fstream> #include <string> using namespace std; int main() { fstream inout( "invoice.dat", ios::in | ios::out ); //write to the file: inout << 1234 << " " << 56.78 << " " << "apples" << '\n'; //current get position: cout<< inout.tellg()<< endl; //21 //current put position: cout << inout.tellp() << endl; //21 //reset: inout.seekg( 0 ); //new get position: cout << inout.tellg() << endl; // 0 //new put position: cout << inout.tellp() << endl; // 0 int x = 0; //(K) double y = 0.0; //(L) string z = " "; //(M) //read first item from file: inout >> x; //(N) //move the stream 8 positions to the right of the //current get position: (this will cause the stream //to skip over the number 56.78) inout.seekg( 8, ios::cur ); //(O) //read next item from file: inout >> z; //(P) cout << x << " " << y << " " << z << endl; //(Q) // 1234 0 apples return 0; }
Note also that the program shown above used seekg(O) to reset the get position to the beginning of the file-it does the same thing as seekg( ios: :beg ) in the program TestFilePosition1. cc.
When provided with a negative offset, the seek function will move the file position towards the beginning of the file. An error condition is created by positioning before the beginning of the file or beyond the end of the file. When an error condition takes place, further processing of the stream is suspended. However, such error conditions can be cleared by invoking the clear () function.
The get () and put () functions for character I/O:
If it is desired to read from or write into an ASCII encoded text file one character at a time, it is convenient to use the istream member function get for reading and the ostream member function put for writing. The function get has been overloaded so that it can be invoked in the following three different ways, the last for retrieving multiple characters at a time:
-
The function is invoked through a call like
ifstream in( "dataFile" ); char ch; while ( in.get( ch ) ) {The function get in this invocation returns the istream object on which it is invoked, unless the stream has reached the end of the file, in which case the function evaluates to false. Since in the example code fragment, the function is invoked on the object in, the same object is returned as long as the stream has not reached the end of the file (or entered some error state). Therefore, the while loop shown for reading one byte at a time makes sense. The loop will terminate automatically when the stream reaches the end of the file or enters an error state. To make certain that the while loop was terminated by the stream reaching the end-of-file condition as opposed to getting into an error state, we can invoke the following test after the above while loop:
if ( !in.eof()) { //print error message and then exit( 1 ); }where eof () is one of the four condition functions defined for testing the error state of a stream, the other three being bad(), fail(), and good(). The function eof () returns true if the stream has reached the end of the file. The function bad()returns true if the stream was asked to carry out an illegal operation, such as invoking a seek function that would cause the file position to be placed either before the beginning of the file or after the end. The function fail() returns true when either bad() returns true or when eof () evaluates to false. Finally, the function good() returns true as long as the stream has not transitioned into an error state. The invocations ! fail()and good () are logically identical. As mentioned earlier, further operations are suspended on a stream when it enters an error state. The error state can be cleared up by invoking clear () on the stream object.
-
The function is invoked through a no-argument call, as in
fstream in( "dataFile" ); int ch; while ( ch = in.get() && ch != EOF ) { ...The function get () now actually returns the byte read from the input stream, as opposed to returning the istream object on which the function is invoked. Also note that the value returned by the function is placed in an int, as opposed to a char. This is to enable the detection of the end-of-file condition as represented by get () returning the EOF constant, which is often set to -1 in the iostream header file.
The reverse of the two get functions shown above is the put function defined for the ostream class. Its signature is
put( char )
It inserts a byte corresponding to its argument into the binary output stream on which the function is invoked and returns the output stream object. An example using a get-put pair to copy a binary file was presented in Chapter 2.
-
The third version of get has the following signature:
get( char* buffer, streamsize size, char deliminter='\n' )
Like the first form of get, the version shown here also returns the istream object on which the function is invoked. This get function reads the bytes up to the position where the delimiter character is found, but the number of bytes read will not exceed size−1. The bytes thus read are stored in a character array starting at the address buffer. As shown by the signature, the default delimiter is the newline character. If the delimiter character is encountered, it is not actually extracted from the stream. So, unless care is taken, it will be encountered by the next invocation of get. So as not to corrupt the next invocation of get, the delimiter character when encountered can be gotten rid of by invoking ignore().[16] After get has deposited all the bytes it can at the location buffer, it terminates the array with the null character. (That's the reason for why a maximum of only size−1 bytes can be extracted from the stream at one time-the last place must be saved for the terminating null character.) The following program is a quick illustration of the use of this version of get. The program reads an executable file a. out. Some of the bytes will be construed to be newline characters. Try it and see what happens.
//GetThirdType.cc #include <fstream> using namespace std; int main() { const int max_count = 256; // will read max of 255 bytes to // allow for null at the end char line[ max_count ]; ifstream in( "a.out" ); while ( in.get( line, max_count ) ) { //(A) int count = in.gcount(); //(B) cout << "num of bytes read:" << count << '\n'; if ( count < max_count-1 ) in.ignore(); //(C) } return 0; }
In order to figure out whether ignore () needs to be invoked to toss out the delimiter in the while loop in line (A), the program calls gcount()in line (B) to determine the number of bytes just read.[17] As mentioned already, if the number of bytes read is strictly less than max_count−1, that means the newline character was encountered while trying to extract max_count−1 bytes from the stream. When that happens, the program invokes ignore in line (C). Since it would be easy to introduce a bug into a program by forgetting to remove the delimiter character when encountered, the iostream library also makes available another function getline that behaves in exactly the same manner as the 3-argument get, except that it automatically gets rid of the delimiter character. The signature of getline is the same as that of the 3-argument get:
getline( char* buffer, streamsize size, char deliminter='\n' )
The additional functions introduced here, getline, gcount () and ignore (), all return the istream object on which they are invoked.
To end this subsection, we want to mention quickly the following additional functions that can be very useful for conditional retrieval of characters from an input stream. Before actually reading a character into our program, we may want to take a peek at the character that the next invocation of a function such as get would retrieve. The following functions are useful for that purpose:
putback(char c) for pushing the argument byte back into the stream.
unget() for reseting the file position to where it was at the time of the previous invocation of get.
peek() for its return value which is the next character that will be read by a call to get; this character will not be extracted from the stream.
6.8.3 Input-Output Operations for Byte Streams
The previous subsection showed how read/write operations can be implemented for character streams.[18] But what about byte streams (also called binary streams)? Suppose we wanted to read an image or a sound file, or copy the contents of an executable file, such as an a. out file output by a C++ compiler, into another file, how would one do that?
If it is desired to read and write an uninterrupted stream of bytes, the first thing to bear in mind is that the stream object created must be set to the binary mode. For example, to attach a binary write stream with a file, we say
ifstream in("dataFile", ios::binary); The second argument, ios::binary, supplied to the ifstream constructor causes the file to be opened in a binary mode. The reader might think that if you are reading only one byte at a time, it shouldn't matter whether you open the file in text mode or binary mode. But beware that if you use the text mode for reading a binary file, you may not see all the bytes if you are using one of the get functions to read the bytes. For example, on Windows platforms, when a binary file is opened in the text mode, the pair of characters corresponding to a newline, <cr><lf>, is read as a single character by the get () method. To illustrate, suppose your binary file contains the bytes for the following characters
hello <cr><lf>
Now suppose you open this file in the text mode and create its hex dump by retrieving the individual bytes from the file with the get () function discussed previously, what you get out of the file will look like
0x68 0x65 0x6c 0x6c 0x6f 0x20 0x0A
where 0x68, 0x65, 0x6c and 0x6f are the hex representations of the ASCII codes for the letters h, e, l, and o, and 0x20 is hex for the space that follows the word ‘hello'. The remaining byte, 0x0A, representing the ASCII for linefeed, is the sole character that get() retrieves for the two characters <cr> and <lf>. In general, performing character based I/O on a binary file opened in the text mode may cause your operating system to carry out system-specific character translations on some of the bytes. Imagine sending an image file to an output stream attached to a printer. In the text mode, some of the bytes could end up being interpreted as form feed, and so on.
After you have created a binary stream object, the next problem is to decide how to read and write an uninterrupted stream of bytes. You, of course, have the choice of reading one byte at a time using the basic get function introduced in the previous subsection, and writing out one byte at a time with the basic put function, also introduced in the previous subsection. But it is more efficient to do binary I/O with the read and write functions, as demonstrated by the following program that copies one binary file into another. In line (A), the program reads the input file in chunks of 1000 bytes and writes each chunk out into the output file in line (B). Towards the end of the file, the last chunk read would encounter the end-of-file condition, which would cause in.read (buffer, N) in line (A) to evaluate to false. These last few bytes are written out separately to the output in line (E) after first invoking gcount in line (D) to figure out the number of bytes involved. In line (F), we check the condition of the input stream to make sure that the failure of the test in line (A) was caused by the end-of-file condition and not by the stream entering some error state.
//BinaryFileIO.cc #include <fstream> #include <cstdlib> using namespace std; const int N = 1000; void print_error(const char* p1, const char* p2 = 0); int main(int argc, char* argv[]) { char buffer[N]; if (3 != argc) print_error("wrong number of arguments - " "usage: function input_file output_file"); ifstream in(argv[1], ios::binary); if (!in) print_error("cannot open input file", argv[1]); ofstream out(argv[2], ios::binary); if (!out) print_error("cannot open output file", argv[2]); while(in.read(buffer, N)) //(A) out.write(buffer, N); //(B) if(in.eof()) { //(C) int count = in.gcount(); //(D) out.write(buffer, count); //(E) } if (!in.eof()) print_error("something strange happened"); //(F) in.close(); out.close(); return 0; } void print_error(const char* p1, const char* p2) { if (p2) cerr << p1 << '-' << p2 << end1; else cerr << p1 << end1; exit(1); }
The above program carries out binary file I/O in blocks of N bytes, where N can be anything the programmer wants it to be. As we show in the next program, it is also possible to read all the bytes in one fell swoop by opening a file with the ios::ate option (line A of the program below) that puts the get-position pointer at the end of the file. Then by invoking the tellg() function (line B), we can figure out the size of the file in bytes. Once we have that information, we can allocate the memory needed in the program for the bytes to be read from the file (line C) and reset the get position to the beginning of the file (line D) so that the file can be read from the beginning. With the get position reset, we can invoke the read and the write functions as before, but this time read off all the bytes from the input file at one time and then write out all the bytes to the output file at one time, too, as we do on lines (F) and (G).
//BinaryFileI02.cc #include <fstream> #include <cstdlib> using namespace std; void print_error(const char* p1, const char* p2 = 0); int main(int argc, char* argv[]) { if (3 != argc) print_error("wrong number of arguments -" "usage: function input_file output_file"); //the ios::ate option below places the get-position pointer //at the end of the file, thus enabling tellg() to return //the size of the file: ifstream in(argv[1], ios::binary | ios::ate); //(A) if (!in) print_error("cannot open input file", argv[1]); //the size of the file in bytes: long N = in.tellg(); //(B) char buffer[N]; //(C) //reset get-position pointer: in.seekg(ios::beg); //(D) ofstream out(argv[2], ios::binary); //(E) if (!out) print_error("cannot open output file", argv[2]); //file copy in one fell swoop: in.read(buffer, N); //(F) out.write(buffer, N); //(G) if (!in.good()) { print_error("something strange happened"); exit(1); } in.close(); out.close(); return 0; } void print_error(const char* p1, const char* p2) { if (p2) cerr << p1 << ' ' << p2 << end1; else cerr << p1 << end1; exit(1); }
Our previous two examples dealt with reading information from a binary input file and copying the same into a destination file. Let's now consider the case when we just want to write some data internal to a program into a file, but we wish for the output to be the binary representation of the data. Consider the following simple example in which we first create an int array of three numbers in line (A), with the intention of writing them out to a file in a binary form. Since each int occupies 4 bytes, we would want to write out 12 bytes, as is reflected by the second argument to the write function in line (B).
//WriteBinaryIntsToFile.cc #include <fstream> using namespace std; int main() { ofstream out("out.data", ios::binary); if (!out) cerr << "cannot open output file" << endl; int data[3] = {1, 2, 3}; //(A) out.write(data, sizeof(data)); //(B) out.close(); return 0; }
If we execute this program on a Pentium machine and if we then examine the contents of the file out.data, in the hex representation they would be
01 00 00 00 02 00 00 00 03 00 00 00 <--- data[0] ---> <--- data[1] ---> <--- data[2] --->
where the first four bytes are the little-endian representation of the first integer in the array, the next four bytes of the next integer, and so on. However, if run the same program on a Sparc machine, we'll get
01 00 00 01 00 00 00 02 00 00 00 03 <--- data[0] ---> <--- data[1] ---> <--- data[2] --->
which is the big-endian representation of the three numbers.[19]
The following extension of the above program shows how you can read data from a binary file into a program. The first part of the program is the same as the program shown above. In lines (A) through (D), it opens an output file in the binary mode, writes out to the file in binary form the three integers of an int array, and then closes the output stream. The rest of the program then opens an input stream to the same file in line (E) in binary and ate modes. Assuming we only know that the file contains just int data and that we do not know how many integers are stored in the file, in line (F) the program figures out the total size of the file in bytes. By dividing the file size by 4, as in line (H), the program can then figure out the number of integers stored in the file. The program resets the get position in line (G) and reads off the data in the file into an array of int's in line (I). Finally, through line (J) we can see that the data from the binary file was correctly read.
//BinaryFileI03.cc #include <fstream> using namespace std; int main(){ ofstream out("out.data", ios::binary); //(A) if (!out) cerr << "cannot open output file" << end1; int data[3] = {1, 2, 3}; //(B) out.write(data, sizeof(data)); //(C) out.close(); //(D) //the ios::ate option places the get-position //pointer at the end of the file, thus enabling //tellg() to return the size of the file: ifstream in("out.data", ios::binary | ios::ate); //(E) if (!in) cerr << "cannot open input file" << end1; //get size of the file in bytes: long size = in.tellg(); //(F) //reset get-position pointer: in.seekg(ios::beg); //(G) int buffer[size/4]; //(H) in.read(buffer, size); //(I) cout << buffer[0] << " " << buffer[1] << " " << buffer[2] << endl; //output: 1 2 3 //(J) in.close(); return 0; }
6.8.4 Controlling the Format
One often wants to output textual information according to a prescribed format. For example, you may want certain items of data to line up in the different rows of a tabular presentation and to be justified left or right; or you may want to display floating point numbers with a certain precision; or you may want to display integers using hexadecimal or octal bases; etc. All such, and many more, formatting decisions can be controlled by stream functions and stream manipulators in C++.
To explain the difference between a formatting stream function and a stream manipulator, let's say that we wish for our floating point values to be printed out using the fixed decimal notation with a precision of 10 (the default is 6). C++ gives us two choices for doing this: Either we can invoke the stream function precision:
cout.precision(10); cout << sqrt(2);
or we can use the stream manipulator setprecision, as in
cout << setprecision(10) << sqrt(2);
In the first case, we invoke the function precision on the stream object, and, in the second, we insert the manipulator setprecision into the output stream. In both cases, the square root of 2 will be printed out with a precision of 10, meaning that 10 digits will be used to display the result (which is 1.414213562).[20]
Most of the stream member functions for formatting and the stream manipulators alter the format state of a stream. What that means in the context of the above example is that once the precision of an output stream is set to, say, 10 digits by either of the above methods, it will stay at 10 for all future insertions of floating point numbers into the stream. So if at a later point in the program, we said merely cout << sqrt (3), it will be printed out with a precision of 10.
With regard to the output of integer values, the stream manipulators hex and oct can be used to display an integer in hexadecimal and octal notation, respectively. The default is the decimal notation, represented by the manipulator dec.
cout << 127 << oct << setw(7) << 127 << hex << setw(5) << 127 << '\n';
will display on a terminal screen the following string
127 177 7f
where the decimal number 127 becomes 177 in the octal notation and 7f in the hexadecimal notion. If the cout statement shown above was followed by another statement like cout << 127, the displayed output would still be 7f because, with regard to the display of integer values, the most recent manipulator inserted into the stream was hex. The manipulator oct also alters the format state of a stream.
The above example also used the manipulator setw, which controls the width of the field used for the next output. So when the decimal number 127 is displayed in octal, a field of width 7 is used for display in which the result (consisting in this case of 3 digits) is shown right justified. By the same token, the hex value of 7f is shown, again right justified, inside a field of width 5. If a display field is wider than the number of digits needed for the value, the rest of the places are filled with a filler character, which by default is a blank space, but can be set to any character by using the manipulator setfill(char) or by invoking the ostream member function fill(char), as in the following example:
cout.fill('#'); cout << setw(7) << 127 << oct << setw(7) << 127 << hex << setw(7) << 127 << '\n'; This will produce the output
####127####177#####7f
If you wanted each integer value to appear left justified in its field, you'd need to insert the manipulator left into the output stream, or you could invoke the member function setf in the following fashion
cout.fill('#'); cout.setf(ios::left); cout << setw(7) << 127 << oct << setw(7) << 127 << hex << setw(7) << 127 << '\n'; This produces the output
127####177####7f#####
As the reader might have noticed already, unlike the other manipulators setw does not alter the format state of a stream. So, in the above examples, we had to set the width of the field separately for each output value even when the field widths were the same for successive outputs.
When integer values are shown in different bases in the same output, it is helpful to use the prefix ‘0x' or ‘0X' for hexes and a leading ‘0' for octals. This can be accomplished either by inserting the manipulator showbase into the stream or by invoking setf as below:
cout.fill('#'); cout.setf(ios::left); cout.setf(ios::showbase); cout << setw(7) << 127 << oct << setw(7) << 127 << hex << setw(7) << 127 << '\n'; This would produce the output
127####0177###0x7f###
The manipulator noshowbase cancels the effect of showbase. Alternatively, one can invoke the member function unsetf(ios::showbase).
By default, if a floating point number has a zero fractional part, the number is displayed without the decimal point. To force the display of the decimal point for such cases, use the manipulator showpoint or invoke the member function setf as in the following example. The code fragment shown
cout << 12.00 << '\n'; cout.precision(10); cout << 12.00 << '\n'; cout.setf(ios::showpoint); cout << 12.00 << '\n';
produces the following output:
12 12 12.00000000
The manipulator noshowpoint cancels the effect of showpoint. Alternatively, one can invoke the member function unsetf(ios::showpoint). By default, a floating point value is displayed using the fixed decimal notation. But that can be changed by using the manipulator scientific, or by invoking the member function setf, as in the following example. The code fragment
cout << sqrt(200) << '\n'; cout.precision(4); cout << sqrt(200) << '\n'; cout.setf(ios::scientific); cout << sqrt(200) << '\n'; cout.precision(8); cout << sqrt(200) << '\n'; cout.setf(ios::fixed); cout << sqrt(200) << '\n';
produces the output:
14.1421 14.14 1.4142e+01 1.41421356e+01 14.142136
First the value is displayed with the default precision, which is 6. We then change the precision to 4. The next entry in the output is the rounded value printed out with the new precision. We next change the mode to scientific, which causes the third entry to be displayed-again with a precision of 4. The next entry corresponds to a precision of 8, while the stream is still in the scientific mode. Finally, we change the stream back to fixed, which results in the last entry-with a precision of 8.
For some of the other manipulators, the manipulator flush flushes the output stream buffer. The manipulator endl inserts a newline into the output stream and then flushes the output stream buffer. The manipulator ends inserts the null character and then flushes the output stream buffer.
So far we have only talked about manipulators for output streams. You can also have manipulators for an input stream. To illustrate, the default behavior of the input operator ‘>>' is to skip over the white space characters. (This can be very convenient in many applications, because you don't have to do anything special to ignore the tabs, the newlines, and so on, that may appear between the more useful data items in a file.) But, if for some reason, you don't want the white space characters to be ignored, you can insert the manipulator noskipws into the input stream. The effect of noskipws is canceled by the manipulator skipws. Alternatively, you can invoke the member functions unsetf(ios::skipws) and setf(ios::skipws) for the same effects. To illustrate, in the following program, the file datafile consists of the following entries:
a bc\td\ne\n
where there is a tab between the letters c and d and newlines after d and e. If we displayed the contents of this file on a terminal, they'd look like
a bc d e
The following program reads this file in two different modes. First it disables the default mode of skipping over white space characters in line (A) and then it restores the default in line (E). In the read loop in line (B), the white space characters will not be ignored, implying that every character in the file will be read into the variable ch. On the other hand, in the read loop in line (F), the tab and the newline characters will be ignored.
//Skipws.cc #include <fstream> using namespace std; int main(){ ifstream in("datafile"); in.unsetf(ios::skipws); //(A) char ch; while (in >> ch) { //(B) cout << ch; //(C) } cout << '\n'; in.clear(); in.seekg(ios::beg); //(D) in.setf(ios::skipws); //(E) while (in >> ch) { //(F) cout << ch; //(G) } cout << '\n'; return 0; }
The output produced by the program is
a bc d e abcde
The first two lines of the output are from the statement in line (C) and the last line from the statement in line (G).
You need to include the header iomanip if your program uses manipulators that take arguments, such as setw, setprecision, setfill, and so on.
6.8.5 String Streams
The iostream library also gives us string streams that allow read and write operations to be carried out with respect to string objects in the memory. Just as an ofstream object permits the use of the insertion operator ‘<<' to write information into a file, an ostringstream object permits the use of the same operator to write characters into a string. In the same vein, just as an ifstream object allows the extraction operator ‘>>' to be used to read information from a file, an istringstream object allows us to use the same operator to read the characters from a string. You must use the header file sstream for the string stream related functions shown in this section.[21]
One advantage of an ostringstream object is that you can use the formatting capabilities of the output operator ‘<<' to convert the numeric data types into their string representation. The following code fragment illustrates this.
int x = 100; double y = sqrt(2); string z = "Hello"; ostringstream os; os << x << " " << y << " " << z;
To gain access to the string object to which the string stream ostringstream is attached, you invoke the str() function on the stream object. So, if the above code fragment was followed by
cout << os.str();
you'd see displayed on the terminal the following string:
100 1.41421 Hello
The following code fragment shows how we may construct a single string from the entire contents of a text file:
ostringstream os; ofstream from("textfile"); char ch; while (os && from.get(ch)) os.put(ch); Note that the ostringstream object automatically takes care of appropriating the memory needed to grow as additional characters are inserted into it.
An istringstream object can be used in a similar manner in conjunction with the ‘>>' operator (or the get function) to read values into variables.
The iostream library also provides a string stream class stringstream that combines the functionality of both an ostringstream and an istringstream.
Before ending this section, we want to mention that by default all C++ streams are buffered. The buffer associated with a stream is of type streambuf. Buffering implies that when we invoke a write operation to a file with a command such as put, the output byte will not in general be written immediately to the file. Instead, the byte will be transferred to a block of memory that serves as the buffer for the output stream. Every once in a while the buffer is flushed, which means that all of the data in the buffer is transferred to the file all at once. A buffer associated with an output stream is flushed (a) whenever it is full, (b) whenever the stream is closed, (c) explicitly by invoking flush or through the manipulator end1, or (d) whenever the stream member function sync() is invoked for immediate synchronization.
[13]The concept of a virtual base is explained in Chapter 16.
[14]The hierarchy shown here is meant merely to convey the idea of the relationships between the different stream classes we will use in this book. In a standard implementation of C++, the class names istream, ostream, and the names that appear below those in the hierarchy, would actually be preceded by the prefix basic_ and suffixed by the template parameter of the character type for the stream. Therefore, in a standard implementation of C++, the class istream would actually appear in the hierarchy as basic_istream<T> where the parameter T may be either char or wchar_t, the latter for holding character sets such as the 16-bit Unicode. In a standard C++ implementation, a stream class name such as ifstream would be a typedef:
typedef basic_ifstream<char> ifstream; typedef basic_ifstream<wchar_t> wifstream;
The reader is referred to Chapter 21 of [54] for further details.
[15]The second argument to the fstream constructor is of type openmode. The following "flags" or their disjunctions are of type openmode: ios:: in for opening a file for reading; ios:: out for opening a file for writing; ios: ate for opening a file with the file position at the end of the file; ios::app for opening a file in the append mode; ios:: trunc for erasing the old contents of a file if it already exists; and ios::binary for opening a file in the binary mode. If the second argument is not supplied, the default mode used for the invocation of the ifstream constructor is ios: :in; for the invocation of the ofstream constructor ios: :out | ios:: trunc; and for the invocation of the fstream constructor ios::in | ios::out.
[16]We know that the delimiter character has been encountered if the number of characters read by get is strictly less than size−1.
[17]When called with an integer argument, the function ignore ( int n ) will skip over n bytes in the input stream. If also supplied with an optional second argument specifying the delimiter character, the function will skip at most the number of bytes corresponding to the first argument, but will not skip past the delimiter character in the input stream. The newline character is the default delimiter.
[18]It is possible to use the insertion and the extraction operators for binary streams also. See, for example, Stroustrup[54].
[19]Just imagine what would happen if you wrote out your binary data file on a Sparc machine but read it into your program on a Pentium machine, or vice versa. If you write out the integer 1 on a Sparc machine, its hex would be 00 00 00 01. But if you read this byte stream into an int on a Pentium machine, it would be read as the integer 16777216.
[20]Invoking precision(), that is without an argument, on an output stream object returns the current value of the precision. Additionally, for any given precision, a floating point value is rounded and not truncated.
[21]It is possible that your C++ compiler still has the older version of the string streams that are defined in the header file strstream.h. If that's the case, you'd need to use ostrstream for the output string stream and istrstream for the input string stream. For one large difference between the older and the newer string streams, the constructor of the older ostrstream requires you to specify a block of memory of a fixed size into which it can then write characters. On the other hand, the newer ostringstream automatically appropriates the memory needed as characters are written into it.
|
EAN: 2147483647
Pages: 273
- Chapter III Two Models of Online Patronage: Why Do Consumers Shop on the Internet?
- Chapter IV How Consumers Think About Interactive Aspects of Web Advertising
- Chapter V Consumer Complaint Behavior in the Online Environment
- Chapter VII Objective and Perceived Complexity and Their Impacts on Internet Communication
- Chapter X Converting Browsers to Buyers: Key Considerations in Designing Business-to-Consumer Web Sites