SOAP Data Encoding
| Another important area of SOAP has to do with the rules and mechanisms for encoding data in SOAP messages. So far, our Web service example, the inventory check, has dealt only with very simple datatypes: strings, integers, and booleans. All these types have direct representation in XML Schema so it was easy, through the use of the xsi:type attribute, to describe the type of data being passed in a message. What would happen if our Web services needed to exchange more complex types, such as arrays and arbitrary objects? What algorithm should be used to determine their representation in XML format? In addition, given SOAP's extensibility requirements, how can a SOAP message specify different encoding algorithms? This section addresses such questions. Specifying Different EncodingsSOAP provides an elegant mechanism for specifying the encoding rules that apply to the message as a whole or any portion of it. This is done via the encodingStyle attribute in the SOAP envelope namespace. The attribute is defined as global in the SOAP schema; it can appear with any element, allowing different encoding styles to be mixed and matched in a SOAP message. An encodingStyle attribute applies to the element it decorates and its content, excluding any children that might have their own encodingStyle attribute. Therefore, any element in a SOAP message can have either no encoding style specified or exactly one encoding style. The rules for determining the encoding style of an element are simple:
SOAP defines one particular set of data encoding rules. They are identified by SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding" in SOAP messages. You will often see this attribute applied directly to the Envelope element in a SOAP message. There is no notion of default encoding in a SOAP message. Encoding style must be explicitly specified. Despite the fact that the SOAP specification defines these encoding rules, it does not mandate them. SOAP implementations are free to choose their own encoding styles. There are costs and benefits to making this choice. A benefit could be that the implementations can choose a more optimized data encoding mechanism than the one defined by the SOAP specification. For example, some SOAP engines already on the market detect whether they are exchanging SOAP messages with the same type of engine and, if so, switch to a highly optimized binary data encoding format. Because this switch happens only when both ends of a communication channel agree to it, interoperability is not hindered. At the same time, however, supporting these different encodings does have an associated maintenance cost, and it is difficult for other vendors to take advantage of the benefits of an optimized data encoding. SOAP Data Encoding RulesThe SOAP data encoding rules exist to provide a well-defined mapping between abstract data models (ADMs) and XML syntax. ADMs can be mapped to directed labeled graphs (DLGs)collections of named nodes and named directed edges connecting two nodes. For Web services, ADMs typically represent programming language and database data structures. The SOAP encoding rules define algorithms for executing the following three tasks :
Although the purpose of the SOAP data encoding is so simple to describe, the actual rules can be somewhat complicated. This section is only meant to provide an overview of topic. Interested readers should pursue the data encoding section of the SOAP Specification. Basic Rules The SOAP encoding uses a type system based on XML Schema. Types are schema types. Simple types Values are instances of types, much in the same way that a string object in Java is an instance of the java.lang.String class. Values are represented as XML elements whose type is the value type. Simple values are encoded as the content of elements that have a simple type. In other words, the elements that represent simple values have no child elements. Compound values are encoded as the content of elements that have a compound type. The parts of the compound value are encoded as child elements whose names and/or positions are those of the part accessors. Note that values can never be encoded as attributes. The use of attributes is reserved for the SOAP encoding itself, as you will see a bit later. Values whose elements appear at the top level of the serialization are considered independent The following snippet shows an example XML schema fragment describing a person with a name and an address. It also shows the associated XML encoding of that schema according to the SOAP encoding rules: <!-- This is an example schema fragment --> <xsd:element name="Person" type="Person"/> <xsd:complexType name="Person"> <xsd:sequence> <xsd:element name="name" type="xsd:string"/> <xsd:element name="address" type="Address"/> </xsd:sequence> <!-- This is needed for SOAP encoding use; there may be a need to specify some encoding parameters, e.g., encodingStyle, through the use of attributes --> <xsd:anyAttribute namespace="##other" processContents="strict"/> </xsd:complexType> <xsd:element name="Address" type="Address"/> <xsd:complexType name="Address"> <xsd:sequence> <xsd:element name="street" type="xsd:string"/> <xsd:element name="city" type="xsd:string"/> <xsd:element name="state" type="USState"/> </xsd:sequence> <!-- Same as above in Person --> <xsd:anyAttribute namespace="##other" processContents="strict"/> </xsd:complexType> <xsd:simpleType name="USState"> <xsd:restriction base="xsd:string"> <xsd:enumeration value="AK"/> <xsd:enumeration value="AL"/> <xsd:enumeration value="AR"/> <!-- ... --> </xsd:restriction> </xsd:simpleType> <!-- This is an example encoding fragment using this schema --> <!-- This value is of compound type Person (a struct) --> <p:Person> <!-- Simple value with accessor "name" is of type xsd:string --> <name>Bob Smith</name> <!-- Nested compound value address --> <address> <street>1200 Rolling Lane</street> <city>Boston</city> <!-- Actual state type is a restriction of xsd:string --> <state>MA</state> </address> </p:Person> One thing should be apparent: The SOAP encoding rules are designed to fit well with traditional uses of XML for data-oriented applications. The example encoding has no mention of any SOAP-specific markup. This is a good thing. Identifying Value TypesWhen full schema information is available, it is easy to associate values with their types. In some cases, however, this is hard to do. Sometimes, a schema will not be available. In these cases, Web service interaction participants should do their best to make messages as self-describing as possible by using xsi:type attributes to tag the type of at least all simple values. Further, they can do some guessing by inspecting the markup to determine how to deserialize the XML. Of course, this is difficult. The only other alternative is to establish agreement in the Web services industry about the encoding of certain generic abstract data types. The SOAP encoding does this for arrays. Other times, schema information might be available, but the content model of the schema element will not allow you to sufficiently narrow the type of contained values. For example, if the schema content type is "any", it again makes sense to use xsi:type as much as possible to specify the exact type of value that is being transferred. The same considerations apply when you're dealing with type inheritance, which is allowed by both XML Schema and all object-oriented programming languages. The SOAP encoding allows a sub-type to appear in any place where a super-type can appear. Without the use of xsi:type , it will be impossible to perform good deserialization of the data in a SOAP message. Sometimes you won't know the names of the value accessors in advance. Remember how Axis auto-generates element names for the parameters of RPC calls? Another example would be the names of values in an arraythe names really don't matter; only their position does. For these cases, xsi:type could be used together with auto-generated element names. Alternatively, the SOAP encoding defines elements with names that match the basic XML Schema types, such as SOAP-ENC:int or SOAP-ENC:string . These elements could be used directly as a way to combine name and type information in one. Of course, this pattern cannot be used for compound types. SOAP ArraysArrays are one of the fundamental data structures in programming languages. (Can you think of a useful application that does not use arrays?) Therefore, it is no surprise that the SOAP data encoding has detailed rules for representing arrays. The key requirement is that array types must be represented by a SOAP-ENC:Array or a type derived from it. These types have the SOAP-ENC:arrayType attribute, which contains information about the type of the contained items as well as the size and number of dimensions of the array. This is one example where the SOAP encoding introduces an attribute and another reason why values in SOAP are encoded using only element content or child elements. Table 3.1 shows several examples of possible arrayType values. The format of the attribute is simple. The first portion specifies the contained element type. This is expressed as a fully qualified XML type name (QName). Compound types can be freely used as array elements. If the contained elements are themselves arrays, the QName is followed by an indication of the array dimensions, such as [] and [,] for one-and two-dimensional arrays, respectively. The second portion of arrayType specifies the size and dimensions of the array, such as [5] or [2,3]. There is no limit to the number of array dimensions and their size. All position indexes are zero-based , and multidimensional arrays are encoded such that the rightmost position index changes the quickest. Table 3.1. Example SOAP-ENC:arrayType Values
If schema information is present, arrays will typically be represented as XML elements whose type is or derives from SOAP-ENC:Array . Further, the array elements will have meaningful XML element names and associated schema types. Otherwise, the array representation would most likely use the pre-defined element names associated with schema types from the SOAP encoding namespace. Here is an example: <!-- Schema fragment for array of numbers --> <element name="arrayOfNumbers"> <complexType base="SOAP-ENC:Array"> <element name="number" type="xsd:int" maxOccurs="unbounded"/> </complexType> <xsd:anyAttribute namespace="##other" processContents="strict"/> </element> <!-- Encoding example using the array of numbers --> <arrayOfNumbers SOAP-ENC:arrayType="xsd:int[2]"> <number>11</number> <number>22</number> </arrayOfNumbers> <!-- Array encoding w/o schema information --> <SOAP-ENC:Array SOAP-ENC:arrayType="xsd:int[2]"> <SOAP-ENC:int>11</SOAP-ENC:int> <SOAP-ENC:int>22</SOAP-ENC:int> </SOAP-ENC:Array> Referencing Data Abstract data models allow a single value to be referred to from multiple locations. Given any particular data structure, a value that is referred to by only one accessor is considered single-reference
Here is an example that brings together simple and compound types, and single-and multi-reference values and arrays: <!-- Person type w/ multi-ref attributes added --> <xsd:complexType name="Person"> <xsd:sequence> <xsd:element name="name" type="xsd:string"/> <xsd:element name="address" type="Address"/> </xsd:sequence> <xsd:attribute name="href" type="uriReference"/> <xsd:attribute name="id" type="ID"/> <xsd:anyAttribute namespace="##other" processContents="strict"/> </xsd:complexType> <!-- Address type w/ multi-ref attributes added --> <xsd:complexType name="Address"> <xsd:sequence> <xsd:element name="street" type="xsd:string"/> <xsd:element name="city" type="xsd:string"/> <xsd:element name="state" type="USState"/> </xsd:sequence> <xsd:attribute name="href" type="uriReference"/> <xsd:attribute name="id" type="ID"/> <xsd:anyAttribute namespace="##other" processContents="strict"/> </xsd:complexType> <!-- Example array of two people sharing an address --> <SOAP-ENC:Array SOAP-ENC:arrayType="p:Person[2]"> <p:Person> <name>Bob Smith</name> <address href="#addr-1" /> </p:Person> <p:Person> <name>Joan Smith</name> <address href="#addr-1" /> </p:Person> </SOAP-ENC:Array> <p:address id="addr-1" > <street>1200 Rolling Lane</street> <city>Boston</city> <state>MA</state> </p:address> The schema fragments for the compound types had to be extended to support the id and href attributes required for multi-reference access. Odds and EndsThe SOAP encoding rules offer many more details that we have glossed over in the interest of keeping this chapter focused on the core uses of SOAP. Three data encoding mechanisms are worth a brief mention:
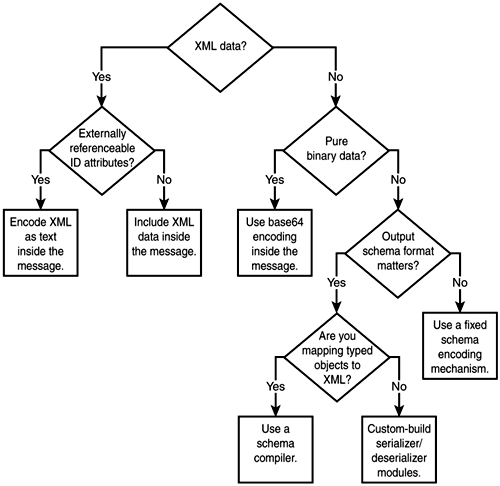
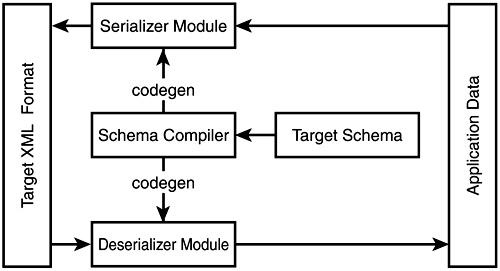
Having covered the SOAP data encoding rules, it is now time to look at the more general problem of encoding different types of data in SOAP messages. Choosing a Data EncodingBecause data encoding needs vary a lot, there are many different ways to approach the problem of representing data for Web services. To add some structure to the discussion, think of the decision space as a choice tree. A choice tree has yes/no questions at its nodes and outcomes at its leaves (see Figure 3.9). Figure 3.9. Possible choice tree for data encoding. XML DataProbably the most common choice has to do with whether the data already is in (or can easily be converted to) an XML format. If you can represent the data as XML, you only need to decide how to include it in the XML instance document that will represent a message in the protocol. Ideally, you could just mix it in amidst the protocol-specific XML but under a different namespace. This approach offers several benefits. The message is easy to construct and easy to process using standard XML tools. However, there is a catch. The problem has to do with a little-considered but very important aspect of XML: the uniqueness rule for ID attributes. The values of attributes of type ID must be unique in an XML instance so that the elements with these attributes can be conveniently referred to using attributes of type IDREF, as shown here: <Target id="mainTarget"/> <Reference href="#mainTarget"/> The problem with including a chunk of XML inline (textually) within an XML document is that the uniqueness of IDs can be violated. For example, in the following code both message elements have the same ID. This makes the document invalid XML: <message id=" msg-1 "> A message with an attached <a href="#msg-1">message</a>. <attachment id="attachment-1"> <!-- ID conflict right here --> <message id=" msg-1 "> This is a textually included message. </message> </attachment> </message> And no, namespaces do not address the issue. In fact, the problems are so serious that nothing short of a change in the core XML specification and in most XML processing tools can change the status quo. Don't wait for this to happen. You can work around the problem two ways. If no one will ever externally reference specific IDs within the protocol message data, then your XML protocol toolset can automatically re-write the IDs and references to them as you include the XML inside the message, as follows : <message id="msg-1"> A message with an attached <a href="#id-9137">message</a>. <attachment id="attachment-1"> <!-- ID has been changed --> <message id=" id-9137 "> This is a textually included message. </message> </attachment> </message> This approach will give you the benefits described earlier at the cost of some extra processing and a slight deterioration in readability due to the machine-generated IDs. If you cannot do this, however, you will have to include the XML as an opaque chunk of text inside your protocol message: <message id="msg-1"> A message with an attached message that we can no longer refer to directly. <attachment id="attachment-1"> <!-- Message included as text --> <message id= "id-9137" > This is a textually included message. </message> </attachment> </message> In this case, we have escaped all pointy brackets, but we also could have included the whole message in a CDATA section. The benefit of this approach is that it is easy and it works for any XML content. However, you don't get any of the benefits of XML. You cannot validate, query, or transform the data directly, and you cannot reference pieces of it from other parts of the message. Binary DataSo far, we have discussed encoding options for pre-existing XML data. However, what if you are not dealing with XML data? What if you want to transport binary data as part of your message, instead? The commonly used solution is good old base64 encoding: <SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/" SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"> <SOAP-ENV:Body> <x:StorePicture xmlns:x="Some URI"> <Picture xsi:type=" SOAP-ENC:base64 "> aG93IG5vDyBicm73biBjb3cNCg== </Picture> </x:StorePicture> </SOAP-ENV:Body> </SOAP-ENV:Envelope> On the positive side, base64 data is easy to encode and decode, and the character set of base64-encoded data is valid XML element content. On the negative side, base64 encoding takes up nearly 33% more memory than pure binary representation. If you need to move much binary data and space/time efficiency is a concern, you might have to look for alternatives. (More on this in a bit.) You mignt want to consider using base64 encoding even when you want to move some plain text as part of a message, because XML's document-centric SGML origin led to several awkward restrictions on the textual content of XML instances. For example, an XML document cannot include any control characters (ASCII codes 0 through 31) except tabs, carriage returns, and line feeds. This limitation includes both the straight occurrences of the characters and their encoded form as character references, such as  . Further, carriage returns are always converted to line feeds by XML processors. It is important to keep in mind that not all characters you can put in a string variable in a programming language can be represented in XML documents. If you are not careful, this situation can lead to unexpected runtime errors. Abstract Data ModelsIf you are not dealing with plain text, XML, or binary data, you probably have some form of structured data represented via an abstract data model. The key question when dealing with abstract data models and XML is whether the output XML format matters. For example, if you have to generate SkatesTown purchase orders, then the output format is clearly important. If, on the other hand, you just want to make an RPC call over SOAP to pass some data to a Web service, then the exact format of the XML representing your RPC parameters does not matter. All that matters is that the Web service engine can decode the XML and reconstruct a similar data structure with which to invoke the backend. In the latter case, it is safe to use pre-built automatic "data to XML and back" encoding systems (see Figure 3.10). For example, Web service engines have data serialization/deserialization modules that support the rules of SOAP encoding. These rules are flexible enough to represent most application-level data types. Suffice to say, in many cases you will never have to worry about the mechanics of the serialization/deserialization processes. Figure 3.10. Generic XML serialization/deserialization. The SOAP encoding is a flexible schema model for representing dataelement names in the instance document often depend on the type and format of data that is being encoded. This model allows for a link between the data and its type, which enables validation. It is one of the core reasons why XML protocols such as SOAP moved to this encoding model, as discussed earlier in the chapter when we considered the evolution of XML protocols. In the cases where the XML output format does not matter (typically RPC scenarios), you can rely on the default rules provided by various XML data encoding systems. In many cases, however, the XML format is fixed based on the specification of a service. A SkatesTown purchase order submission service is a perfect example. From a requestor 's perspective, the input format must be a PO document and the output format must be an invoice document. Requestors are responsible for mapping whatever data structures they might be using to represent POs in their order systems to the SkatesTown PO format. Also, SkatesTown is responsible for always outputting responses in its invoice XML format. There are two typical approaches to handling this scenario. The simplest one is to completely delegate XML processing to the application. In other words, the Web service engine is responsible only for delivering a chunk of XML to the Web service implementation. Another approach involves building and registering custom serializers/deserializers (datatype mappers) with the Web service engine. The serializers manipulate application data to produce XML. The deserializers manipulate the XML to generate application data. You can build these serializer/deserializer modules two ways: by hand, using the APIs of the Web service engine; or using a tool for mapping data to and from XML given a pre-existing schema. These tools are known as schema compilers Figure 3.11. Serialization/deserialization process with a schema compiler. Schema compilers are tools that analyze XML schema and code-generate serialization and deserialization modules specific to the schema. These modules will work with data structures tuned to the schema. Schema compilation is a difficult problem, and this is one reason there aren't many excellent tools in this space. The Java Architecture for XML Binding (JAXB) is one of the projects that is trying to address this problem in the context of the Java programming language (http://java.sun.com/xml/jaxb/). Unfortunately, at the time of this writing, JAXB only supports DTDs and does not support XML Schema. Chapter 8, "Interoperability, Tools, and Middleware Products," focuses on the current Web service tooling for the Java platform. It provides more details on these and other important implementation efforts in the space. Linking DataSo far, we have only considered scenarios where the encoded data is part of the XML document describing a protocol message. This can create some problems for including pre-existing XML content and can waste space in the case of base64-encoded binary objects. The alternative would be keeping the data outside of the message and somehow bringing it in at the right time. For example, an auto insurance claim might carry along several accident pictures that come into play only when the insurance claim needs to be displayed in a browser or printed. You can use two general mechanisms in such cases. The first comes straight out of XML 1.0. It involves external entity references, which allow content external to an XML document to be brought in during processing. Many people in the industry prefer pure markup and therefore favor a second approach that uses explicit link elements that comply with the XLink specification. Both methods could work. Both require extensions to the core Web services toolsets that are available now. In addition, purely application-based methods are available for linking; you could just pass a URI known to mean "get the actual content here." However, this approach does not scale to generic data encoding mechanisms because it requires application-level knowledge. External content can be kept on a separate server to be delivered on demand. It can also be packaged together with the protocol message in a MIME envelope. The SOAP Messages with Attachments Note to the W3C (http://www.w3.org/TR/2000/NOTE-SOAP-attachments-20001211) defines a mechanism for doing this. An example SOAP message with an attachment is shown later in the chapter in the section "SOAP Protocol Bindings." There are many, many ways to encode data in XML, and well-designed XML protocols will let you plug any encoding style you choose. How should you make this important decision? First, of course, keep it simple. If possible, choose standards-based and well-deployed technology. Then, consider your needs and match them against some of the important facets of XML data encoding described here. |

EAN: N/A
Pages: 130