Converting Between Byte Arrays and Strings
I/O is about bytes. Disks and networks understand bytes, not characters. Nonetheless, much actual programming is modeled in terms of characters and text. When reading in data, it's generally necessary to convert the bytes into characters. When writing out data, it's necessary to convert the characters into bytes. The Reader and Writer classes can perform the conversions implicitly, which is normally the simplest approach when you only need to work on text. However, when working with mixed formats such as FITS, GIF, or XOP that contain both text and binary data, it's normally necessary to explicitly convert the text to or from bytes in some encoding.
19.5.1. The String Class
The java.lang.String class has several constructors that form a string from a byte array and several methods that return a byte array corresponding to a given string. There's no unique way to do this. There are multiple encodings of characters into bytes. Anytime a string is converted to bytes or vice versa, that conversion happens according to a certain encoding. The same string can produce different byte arrays when converted into different encodings.
Six constructors form a new String object from a byte array:
public String(byte[] ascii, int highByte) public String(byte[] ascii, int highByte, int offset, int length) public String(byte[] data, String encoding) throws UnsupportedEncodingException public String(byte[] data, int offset, int length, String encoding) throws UnsupportedEncodingException public String(byte[] data) public String(byte[] data, int offset, int length)
The first two constructors, the ones with the highByte argument, are leftovers from Java 1.0 that are deprecated in Java 1.1 and later. These two constructors do not accurately translate non-Latin-1 character sets into Unicode. Instead, they read each byte in the ascii array as the low-order byte of a 2-byte character and fill in the high-order byte with the highByte argument. For example:
byte[] isoLatin1 = new byte[256]; for (int i = 0; i < 256; i++) isoLatin1[i] = (byte) i; String s = new String(isoLatin1, 0);
Frankly, this is a kludge. It's deprecated for good reason. This scheme works quite well for Latin-1 data with a high byte of 0. However, it's extremely difficult to use for character sets where different characters need to have different high bytes, and it's completely unworkable for character sets like MacRoman that also need to adjust bits in the low-order byte to conform to Unicode. The only approach that genuinely works for the broad range of character sets Java programs may be asked to handle is table lookup. Each supported character encoding requires a table mapping characters in the set to Unicode characters. These tables are hidden inside the sun.io package, but they are present, and they are how the next four constructors translate from various encodings to Unicode.
The third and fourth constructors allow the client programmer to specify not only the byte data but also the encoding table to be used when converting these bytes to Unicode chars. The third constructor converts the entire array from the specified encoding into Unicode. The fourth one converts only the specified subarray of data starting at offset and continuing for length bytes. Otherwise, they're identical. The first argument is the data to be converted. The final argument is the encoding scheme to be used to perform the conversion. For example:
byte[] isoLatin1 = new byte[256]; for (int i = 0; i < 256; i++) isoLatin1[i] = (byte) i; String s = new String(isoLatin1, "8859_1");
The fifth and sixth constructors are similar to the third and fourth. However, they always use the host platform's default encoding, as specified by the system property file.encoding. If this is ISO 8859-1, you may write:
byte[] isoLatin1 = new byte[256]; for (int i = 0; i < 256; i++) isoLatin1[i] = (byte) i; String s = new String(isoLatin1);
This code fragment produces different results on platforms with different default encodings.
The three getBytes( ) methods go the other direction, converting the Unicode string into an array of bytes in a particular encoding:
public void getBytes(int srcBegin, int srcEnd, byte[] dst, int dstBegin) public byte[] getBytes( ) public byte[] getBytes(String encoding) throws UnsupportedEncodingException
Once again, the first method is deprecated. The byte array it returns contains only the low-order bytes of the 2-byte characters in the string (starting at srcBegin and continuing through srcEnd). This works well enough for ASCII and Latin-1 but fails miserably for pretty much all other character sets. The no-arg getBytes( ) method properly converts the Unicode characters in the string into a byte array in the platform's default encodingassuming a full conversion is possible (and it isn't always; you cannot, for example, convert a string of Chinese ideographs into Latin-1). The byte array returned contains the converted characters. The third and final getBytes( ) method specifies the encoding to be used to make the conversion. For example, this statement converts the Greek word andr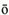 s (man) into its byte equivalent using the MacGreek encoding:
s (man) into its byte equivalent using the MacGreek encoding:
byte[] man = ">andr
s (man) into its byte equivalent using the MacGreek encoding:
byte[] man = ">s">This method throws an UnsupportedEncodingException if the Java virtual machine does not supply the requested encoding.s (man) into its byte equivalent using the MacGreek encoding:
byte[] man = ">s">
19.5.2. The Charset Class
Char-to-byte conversion through the String class is relatively indirect and not always as efficient as one would like. In Java 1.4, the java.nio.charsets package provides classes for efficient conversion of large chunks of text to and from any encoding Java supports. This is in fact a more direct interface to the character conversion code that's used by the String class and has been present in the JDK since Java 1.1.
Charset is an abstract class that represents a character set such as US-ASCII, ISO-8859-1, or SJIS. Each Charset object defines a mapping between the characters in that set and some subset of Unicode. The mapping is sometimes implemented algorithmically, sometimes as simple table lookup, and sometimes as a combination of both, but the details need not concern you. The Charset abstraction hides all this.
19.5.2.1. Retrieving Charset objects
The one constructor in the Charset class is protected:
protected Charset(String canonicalName,String[] aliases)
While you might invoke this if adding support for an encoding Java doesn't support out of the box, that usage is rare. Much more commonly, you'll call the Charset.forName( ) factory method to ask Java for one of the encodings it supports:
public static Charset forName(String charsetName) throws IllegalCharsetNameException, UnsupportedCharsetException
For example, this statement requests the Charset object for the Big5 encoding for Chinese:
Charset big5 = Charset.forName("Big5");
Character set names are case insensitive. Charset.forName("BIG5") returns the same Charset object as Charset.forName("Big5").
If the local JDK supports the requested encoding, Charset.forName( ) returns a Charset object. Otherwise, it throws an UnsupportedCharsetException. This is a runtime exception, so you don't need to explicitly handle it as long as you're confident the runtime contains the requested character set. Charset.forName( ) may also throw an IllegalCharsetNameException if the name contains spaces, non-ASCII characters, or punctuation marks other than the hyphen, period, colon, and underscore.
Java 5 adds one more way to get a Charset. The static Charset.defaultCharset( ) method returns the current system's default character set:
public static Charset defaultCharset( )
This code prints the name of the platform's default character set:
System.out.println(Charset.defaultCharset( ));
When I tested this, the default on Mac OS X was MacRoman, on Windows it was windows-1252, and on Linux it was UTF-8. These were all U.S.-localized systems. Systems localized for other countries, especially outside Western Europe and the Americas, would probably show something different.
19.5.2.2. Character set info
The static Charset.isSupported( ) method checks whether an encoding is available in the current VM:
public static boolean isSupported(String charsetName)
For example, if you wanted to use Big5 if possible but fall back to UTF-8 if it wasn't, you might write code like this:
Charset cs;
if (Charset.isSupported("Big5") cs = Charset.forName("Big5");
else cs = Charset.forName("UTF-8");
The static Charset.availableCharsets( ) method enables you to inquire which character sets are installed in the local VM:
public static SortedMap availableCharsets( )
The keys in the returned method are the character set names. The values are the Charset objects themselves. In Java 5, a genericized signature makes this more explicit:
public static SortedMap availableCharsets( )
Example 19-1 is a simple program to list all the available character sets:
Example 19-1. List available character sets
import java.nio.charset.*;
import java.util.*;
class CharsetLister {
public static void main(String[] args) {
Map charsets = Charset.availableCharsets( );
Iterator iterator = charsets.keySet().iterator( );
while (iterator.hasNext( )) {
System.out.println(iterator.next( ));
}
}
}
|
When run on the Apple Java VM 1.4, it found 64 character sets, including the following:
$ java CharsetLister Big5 Big5-HKSCS EUC-JP EUC-KR GB18030 GBK ISO-2022-JP ISO-2022-KR ISO-8859-1 ISO-8859-13 ISO-8859-15 ISO-8859-2 ... x-MS950-HKSCS x-mswin-936 x-windows-949 x-windows-950
The Java 5 VM has 85 more. Character set availability varies from one VM vendor and version to the next. In general, I recommend sticking to UTF-8 if at all possible for new data. UTF-8 should always be supported. Legacy protocols, formats, and data may require occasional use of US-ASCII, ISO-8859-1, or other encodings, but new text data should be encoded in UTF-8.
Many character sets are commonly known by more than one name. For instance, UTF-8 is also referred to as UTF8 and unicode-1-1-utf-8. The names shown in the program's output are the canonical names of the character sets. The name( ) instance method returns the canonical name of a given Charset object:
public String name( )
The aliases( ) method returns all the aliases for a given character set, not including its canonical name:
public final Set aliases( )
The values in the set are strings. In Java 5, a genericized signature makes this more explicit:
public final Set aliases( )
Character sets may also have display names that can be localized and may contain non-ASCII characters:
public String displayName( )
The display name is usually the same as the canonical name, but specific implementations may instead return a localized value that can contain spaces and non-ASCII characters. The display name is meant for showing to people, not for looking up character sets.
For interoperability, character set names and aliases should be registered with the Internet Assigned Number Authority (IANA) and listed in the registry at http://www.iana.org/assignments/character-sets. The isRegistered( ) method returns true if the character set has been so registered:
public final boolean isRegistered( )
Many of the character sets shipped with the JDK have not been registered. You may need to use these character sets to decode existing data, but you should not generate any new data in an unregistered character set.
Example 19-3 is a slightly more complex program that lists all the available character sets by their display names, canonical names, and aliases.
Example 19-2. List different names for character sets
import java.nio.charset.*;
import java.util.*;
class AliasLister {
public static void main(String[] args) {
Map charsets = Charset.availableCharsets( );
Iterator iterator = charsets.values().iterator( );
while (iterator.hasNext( )) {
Charset cs = (Charset) iterator.next( );
System.out.print(cs.displayName( ));
if (cs.isRegistered( )) {
System.out.print(" (registered): ");
}
else {
System.out.print(" (unregistered): ");
}
System.out.print(cs.name( ) );
Iterator names = cs.aliases().iterator( );
while (names.hasNext( )) {
System.out.print(", ");
System.out.print(names.next( ));
}
System.out.println( );
}
}
}
|
Here's a sample of the output from the Apple Java VM 1.4:
$ java AliasLister Big5 (registered): Big5, csBig5 Big5-HKSCS (registered): Big5-HKSCS, big5-hkscs, Big5_HKSCS, big5hkscs EUC-JP (registered): EUC-JP, eucjis, x-eucjp, csEUCPkdFmtjapanese, eucjp, Extended_UNIX_Code_Packed_Format_for_Japanese, x-euc-jp, euc_jp EUC-KR (registered): EUC-KR, ksc5601, 5601, ksc5601_1987, ksc_5601, ksc5601-1987, euc_kr, ks_c_5601-1987, euckr, csEUCKR GB18030 (registered): GB18030, gb18030-2000 ... x-MS950-HKSCS (unregistered): x-MS950-HKSCS, MS950_HKSCS x-mswin-936 (unregistered): x-mswin-936, ms936, ms_936 x-windows-949 (unregistered): x-windows-949, windows949, ms_949, ms949 x-windows-950 (unregistered): x-windows-950, windows-950, ms950
19.5.2.3. Encoding and decoding
Of course, the primary purpose of a Charset object is to encode and decode text. The encode( ) and decode( ) methods do this:
public final CharBuffer decode(ByteBuffer buffer) public final ByteBuffer encode(CharBuffer buffer) public final ByteBuffer encode(String s)
You can encode either a String or a CharBuffer. Decoding operates on a ByteBuffer and produces a CharBuffer. These methods do not throw exceptions. If they encounter a character they cannot convert, they replace it with the replacement character (normally a question mark).
All character sets support decoding, and most but not all support encoding. The canEncode( ) method returns true if the Charset supports encoding and false if it doesn't:
public boolean canEncode( )
A few special sets automatically detect the encoding of an incoming stream and set the decoder appropriately. In the VM I use, there are exactly two such nonencoding charsets: csISO2022CN and JISAutoDetect. If you try to encode text with a Charset that does not support encoding, the encode( ) method throws an UnsupportedOperationException.
Example 19-5 is a simple program that reads a stream in one encoding and writes it out in another encoding. A Charset object converts between the two encodings. The user interface implemented in the main( ) method simply reads the names of the encodings to convert to and from the command-line arguments. Input is read from System.in and written to System.out, mostly because I didn't want to spend a lot of lines parsing command-line arguments. However, the convert( ) method is more general and can operate on any streams you pass in.
Example 19-3. Converting encodings
import java.io.*;
import java.nio.charset.*;
import java.nio.*;
import java.nio.channels.*;
public class Recoder {
public static void main(String[] args) {
if (args.length != 2) {
System.err.println(
"Usage: java Recoder inputEncoding outputEncoding outFile");
return;
}
try {
Charset inputEncoding = Charset.forName(args[0]);
Charset outputEncoding = Charset.forName(args[1]);
convert(inputEncoding, outputEncoding, System.in, System.out);
}
catch (UnsupportedCharsetException ex) {
System.err.println(ex.getCharsetName( ) + " is not supported by this VM.");
}
catch (IllegalCharsetNameException ex) {
System.err.println(
"Usage: java Recoder inputEncoding outputEncoding outFile");
}
catch (IOException ex) {
System.err.println(ex.getMessage( ));
}
}
private static void convert(Charset inputEncoding, Charset outputEncoding,
InputStream inStream, OutputStream outStream) throws IOException {
ReadableByteChannel in = Channels.newChannel(inStream);
WritableByteChannel out = Channels.newChannel(outStream);
for (ByteBuffer inBuffer = ByteBuffer.allocate(4096);
in.read(inBuffer) != -1;
inBuffer.clear( )) {
inBuffer.flip( );
CharBuffer cBuffer = inputEncoding.decode(inBuffer);
ByteBuffer outBuffer = outputEncoding.encode(cBuffer);
while (outBuffer.hasRemaining( )) out.write(outBuffer);
}
}
}
|
The convert( ) method wraps a channel around the InputStream and another channel around the OutputStream. Data is read from the input channel into a ByteBuffer. Next, this buffer is flipped and decoded into a CharBuffer using the input Charset. That CharBuffer is then reencoded into a new ByteBuffer using the output encoding. Finally, this byte buffer is written onto the output channel.
Example 19-5 is simple, but it has one inobvious bug. What if the input data in the buffer does not contain a complete multibyte character? That is, what if it reads in only the first byte of a 2-byte or longer character? In this case, that character is replaced by the replacement character (usually a question mark). However, suppose you have a long stream that requires multiple reads from the channel into the bufferthat is, say the entire stream can't fit into the buffer at once. Or suppose the channel is nonblocking and the first couple of bytes of a 3- or 4-byte character have arrived, but the last bytes haven't. In other words, suppose the data in the buffer is malformed, even though the stream itself isn't. The encode( ) method does not leave anything in the buffer. It will drain the buffer completely and use replacement characters at the end if necessary. This has the potential to corrupt good data, and it can be a very hard bug to diagnose because 99% of the time you're not going to hit the fencepost condition that triggers the bug. (One way to make it a little more likely to show up is to reduce the size of the buffer to something quite small, even three or four bytes.)
You can avoid this problem by using a CharsetDecoder object directly to fill the buffer with data repeatedly, and decode it only once all the data has been placed in the buffer.
19.5.3. CharsetEncoder and CharsetDecoder
The decode( ) and encode( ) methods suffice for most simple use cases (as do the String constructors and the getBytes( ) method). However, for more sophisticated needs, you may wish to use an explicit CharsetEncoder or CharsetDecoder. These aren't as simple as the previous methods, but they allow greater customization. For example, you can configure them to throw an exception if they encounter an unencodable character rather than replacing it with a question mark. Let's address the encoder first. The decoder is similar, except it runs in the opposite direction.
19.5.3.1. Encoding
The constructor in the CharsetEncoder class is protected. Encoders are created by first getting a Charset object for the encoding and then invoking its newEncoder( ) method:
public abstract CharsetEncoder newEncoder( ) throws UnupportedOperationException
This method throws an UnupportedOperationException if this is one of those uncommon character sets that does not support encoding. For example:
Charset utf8 = Charset.forName("UTF-8");
CharsetEncoder encoder = utf8.newEncoder( );
The encoder encodes bytes from a CharBuffer into a ByteBuffer:
public final CoderResult encode(CharBuffer in, ByteBuffer out, boolean endOfInput)
encode( ) reads as much data as possible from the CharBuffer and writes the encoded bytes into the ByteBuffer. You normally call this method repeatedly, passing in more data each time. All but the last time, you pass false as the final argument, indicating that this is not the end of the input data. The last time you call encode( ), you pass true. (If necessary, you can encode until there are no bytes remaining while passing false and then encode zero bytes while passing TRue, but you do need to pass TRue the last and only the last time you call the method.) Finally, you invoke the flush( ) method to write any last bytes that need to be written. The output buffer can then be flipped and drained somewhere else.
For example, this method converts a string into a ByteBuffer containing the UTF-8 encoding of the string:
public static ByteBuffer convertToUTF8(String s) {
CharBuffer input = CharBuffer.wrap(s);
Charset utf8 = Charset.forName("UTF-8");
CharsetEncoder encoder = utf8.newEncoder( );
ByteBuffer output = ByteBuffer.allocate(s.length( )*3);
while (input.hasRemaining( )) {
encoder.encode(input, output, false);
}
encoder.encode(input, output, true);
encoder.flush(output);
output.flip( );
return output;
}
In UTF-8, each char in the string is encoded into at most three bytes in the output array, so there's no possibility of underflow or overflow. However, there is a small chance of the data being malformed if surrogate characters are used incorrectly in the input string. Java doesn't check for this. To check for it (and you should, or this code could get caught in an infinite loop), you need to inspect the return value from encode( ). The return value is a CoderResult object that has five methods to tell you what happened:
public boolean isError( ) public boolean isUnderflow( ) public boolean isOverflow( ) public boolean isMalformed( ) public boolean isUnmappable( )
(There's no result for success. If the encoding succeeded, these five methods each return false.) Inspecting the result, and throwing an error if the encoding failed for any reason, the convertToUTF8( ) method now becomes this:
public static ByteBuffer convertToUTF8(String s) throws IOException {
CharBuffer input = CharBuffer.wrap(s);
Charset utf8 = Charset.forName("UTF-8");
CharsetEncoder encoder = utf8.newEncoder( );
ByteBuffer output = ByteBuffer.allocate(s.length( )*3);
while (input.hasRemaining( )) {
CoderResult result = encoder.encode(input, output, false);
if (result.isError( )) throw new IOException("Could not encode " + s);
}
encoder.encode(input, output, true);
encoder.flush(output);
output.flip( );
return output;
}
CharsetEncoder also has a convenience method that encodes all the remaining text in a character buffer and returns a ByteBuffer of the necessary size:
public final ByteBuffer encode(CharBuffer in) throws CharacterCodingException
This avoids problems with underflow and overflow. However, if the data is malformed or a character cannot be converted into the output character set, it may throw a CharacterCodingException. (This is configurable with the onMalformedInput( ) and onUnmappableCharacter( ) methods.)
You can use a single CharsetEncoder object to encode multiple buffers in sequence. If you do this, you will need to call the reset( ) method between buffers:
public final CharsetEncoder reset( )
This returns the same CharsetEncoder object to enable method invocation chaining.
19.5.3.2. Decoding
The CharsetDecoder class is almost a mirror image of CharsetEncoder. It converts from bytes to characters rather than from characters to bytes. The constructor in the CharsetDecoder class is protected too. Instead, an encoder for a character is created by first getting a Charset object for the encoding and then invoking its newDecoder( ) method:
Charset utf8 = Charset.forName("UTF-8");
CharsetDecoder decoder = utf8.newDecoder( );
The decoder decodes bytes from a ByteBuffer into a CharBuffer:
public final CoderResult decode(ByteBuffer in, CharBuffer out, boolean endOfInput)
As much data as possible is read from the ByteBuffer, converted into chars, and written into the CharBuffer. You call this method repeatedly, passing in more data each time. All but the last time, you pass false as the final argument. The last time you call decode( ), pass TRue. Finally, invoke the flush( ) method to clear any last state. At this point, the final data is flushed into the output buffer, which can be flipped and drained somewhere else. For example, this method converts a byte array containing UTF-8 text into a string:
public static String convertFromUTF8(byte[] data) throws IOException {
ByteBuffer input = ByteBuffer.wrap(data);
Charset utf8 = Charset.forName("UTF-8");
CharsetDecoder decoder = utf8.newDecoder( );
CharBuffer output = CharBuffer.allocate(data.length);
while (input.hasRemaining( )) {
CoderResult result = decoder.decode(input, output, false);
if (result.isError()) throw new IOException( );
}
decoder.decode(input, output, true);
decoder.flush(output);
output.flip( );
return output.toString( );
}
CharsetDecoder also has a convenience method that decodes all the remaining data in a byte buffer and returns a CharBuffer of the necessary size:
public final CharBuffer decode(ByteBuffer in) throws CharacterCodingException
This avoids problems with underflow and overflow. However, if the data is malformed or a character cannot be converted into the output character set, it may throw a CharacterCodingException. (This is configurable with the onMalformedInput( ) and onUnmappableCharacter( ) methods.)
You can reuse a single CharsetDecoder object to decode multiple buffers in sequence. If you do this, you will need to call the reset( ) method between buffers:
public final CharsetDecoder reset( )
19.5.3.3. Error handling
Each call to encode( ) or decode( ) returns a CoderResult object. This object tells you whether the encoding succeeded, and, if so, how many bytes were encoded. Normally, all you care about is whether the encoding succeeded or not. This is revealed by the isError( ) method:
public boolean isError( )
However, if you care about why the encoding failed, several more methods in CoderResult reveal the reason. Encoding can fail because there were insufficient characters to encode into bytes:
public boolean isUnderflow( )
This might happen if only the first half of a surrogate pair were supplied at the end of the input buffer.
Encoding or decoding can fail because there are too many characters to encode into the output buffer:
public boolean isOverflow( )
Decoding can fail because the data is malformed in some way:
public boolean isMalformed( )
For instance, this might happen in UTF-8 if the bytes of a multibyte character were shuffled.
Encoding can fail because the character you're trying to encode is unmappable:
public boolean isUnmappable( )
For instance, this would happen if you were trying to encode the Greek letter a using the ISO-8859-1 character set because this character set does not contain the letter a.
Some charsets may also tell you the length of the bad data that caused the encoding or decoding to fail:
public int length( ) throws UnsupportedOperationException
However, not all will, and this method may throw an UnsupportedOperationException.
The whole idea of returning a special object to specify the error is a little strange for Java. This is exactly what exceptions were designed to replace. If you like, you can cause the CoderResult to throw an equivalent exception instead, using the throwException( ) method:
public void throwException( ) throws CharacterCodingException
Depending on the type of the error, this throws a BufferUnderflowException, BufferOverflowException, MalformedInputException, or UnmappableCharacterException. For example:
CoderResult result = decoder.decode(input, output, false); if (result.isError()) result.throwException( );
Sometimes you want to throw the exception and then stop reading or writing. For example, this would be appropriate if you were feeding data to an XML parser. However, if you're in the less draconian world of HTML, you might want to just keep on trucking. To loosen up this way, you can set the action for malformed input and/or unmappable characters to CodingErrorAction.IGNORE or CodingErrorAction.REPLACE with onUnmappableCharacter( ) and onMalformedInput( ):
public final CharsetEncoder onMalformedInput(CodingErrorAction action) public final CharsetEncoder onUnmappableCharacter(CodingErrorAction action)
Ignoring simply drops bad data while replacing changes the bad data to a specified replacement character (usually the question mark, by default). There's no separate method for overflow and underflow errors. They count as malformed input. For example, these statements tell a CharsetEncoder to drop malformed input and to replace unmappable characters:
encoder.onMalformedInput(CodingErrorAction.IGNORE); encoder.onUnmappableCharacter(CodingErrorAction.REPLACE);
You can also set the action to CodingErrorAction.REPORT. This is usually the default and simply indicates that the encoder or decoder should return an error in a CoderResult or throw a CharacterCodingException.
The replaceWith( ) method changes the replacement bytes the encoder uses when it encounters an unmappable character while operating in replace mode:
public final CharsetEncoder replaceWith(byte[] replacement) throws IllegalArgumentException
Not all byte sequences are legal here. The replacement array must contain characters allowed in the encoding. If not, this method throws an IllegalArgumentException.
There's also a getter method for this value:
public final byte[] replacement( )
The CharsetDecoder class has similar methods, except that it uses a string replacement value instead of a byte replacement value:
public final CharsetDecoder replaceWith(String newReplacement) public final String replacement( )
19.5.3.4. Measurement
A CharsetEncoder can estimate the number of bytes that will be required for each char that's encoded:
public final float averageBytesPerChar( )
This may be exact for some encodings, but for variable-width encodings such as UTF-8 it's only approximate. Java estimates UTF-8 as averaging 1.1 bytes per character, but the exact ratio can vary widely from one string to the next.
A CharsetEncoder can also tell you the theoretical maximum number of bytes that will be needed for each character:
public final float maxBytesPerChar( )
Both of these values can be useful in choosing the size of the ByteBuffer to encode into.
19.5.3.5. Encodability
Encoders have the useful ability to tell whether or not a particular character, string, or character sequence can be encoded in a given encoding:
public boolean canEncode(char c) public boolean canEncode(CharSequence cs)
For example, this is very useful for XML serializers writing non-Unicode encodings. These need to know whether any given string can be written directly or needs to be escaped with a numeric character reference such as or . Serializers that operate in Java 1.3 and earlier have to either use undocumented classes in the sun packages, use really ugly hacks where they first convert the bytes into a string and then look to see if a replacement character was used, or implement their own lookup tables for all this data. In Java 1.4 and later, by contrast, serializers can just create an appropriate encoder and then call canEncode( ).
Basic I/O
Introducing I/O
- Introducing I/O
- What Is a Stream?
- Numeric Data
- Character Data
- Readers and Writers
- Buffers and Channels
- The Ubiquitous IOException
- The Console: System.out, System.in, and System.err
- Security Checks on I/O
Output Streams
- Output Streams
- Writing Bytes to Output Streams
- Writing Arrays of Bytes
- Closing Output Streams
- Flushing Output Streams
- Subclassing OutputStream
- A Graphical User Interface for Output Streams
Input Streams
- Input Streams
- The read( ) Method
- Reading Chunks of Data from a Stream
- Counting the Available Bytes
- Skipping Bytes
- Closing Input Streams
- Marking and Resetting
- Subclassing InputStream
- An Efficient Stream Copier
Data Sources
File Streams
Network Streams
Filter Streams
Filter Streams
- Filter Streams
- The Filter Stream Classes
- The Filter Stream Subclasses
- Buffered Streams
- PushbackInputStream
- ProgressMonitorInputStream
- Multitarget Output Streams
- File Viewer, Part 2
Print Streams
Data Streams
- Data Streams
- The Data Stream Classes
- Integers
- Floating-Point Numbers
- Booleans
- Byte Arrays
- Strings and chars
- Little-Endian Numbers
- Thread Safety
- File Viewer, Part 3
Streams in Memory
- Streams in Memory
- Sequence Input Streams
- Byte Array Streams
- Communicating Between Threads Using Piped Streams
Compressing Streams
- Compressing Streams
- Inflaters and Deflaters
- Compressing and Decompressing Streams
- Zip Files
- Checksums
- File Viewer, Part 4
JAR Archives
- JAR Archives
- Meta-Information: Manifest Files and Signatures
- The jar Tool
- The java.util.jar Package
- JarFile
- JarEntry
- Attributes
- Manifest
- JarInputStream
- JarOutputStream
- JarURLConnection
- Pack200
- Reading Resources from JAR Files
Cryptographic Streams
- Cryptographic Streams
- Hash Functions
- The MessageDigest Class
- Digest Streams
- Encryption Basics
- The Cipher Class
- Cipher Streams
- File Viewer, Part 5
Object Serialization
- Object Serialization
- Reading and Writing Objects
- Object Streams
- How Object Serialization Works
- Performance
- The Serializable Interface
- Versioning
- Customizing the Serialization Format
- Resolving Classes
- Resolving Objects
- Validation
- Sealed Objects
- JavaDoc
New I/O
Buffers
- Buffers
- Copying Files with Buffers
- Creating Buffers
- Buffer Layout
- Bulk Put and Get
- Absolute Put and Get
- Mark and Reset
- Compaction
- Duplication
- Slicing
- Typed Data
- Read-Only Buffers
- CharBuffers
- Memory-Mapped I/O
Channels
- Channels
- The Channel Interfaces
- File Channels
- Converting Between Streams and Channels
- Socket Channels
- Server Socket Channels
- Datagram Channels
Nonblocking I/O
The File System
Working with Files
- Working with Files
- Understanding Files
- Directories and Paths
- The File Class
- Filename Filters
- File Filters
- File Descriptors
- Random-Access Files
- General Techniques for Cross-Platform File Access Code
File Dialogs and Choosers
Text
Character Sets and Unicode
- Character Sets and Unicode
- The Unicode Character Set
- UTF-16
- UTF-8
- Other Encodings
- Converting Between Byte Arrays and Strings
Readers and Writers
- Readers and Writers
- The java.io.Writer Class
- The OutputStreamWriter Class
- The java.io.Reader Class
- The InputStreamReader Class
- Encoding Heuristics
- Character Array Readers and Writers
- String Readers and Writers
- Reading and Writing Files
- Buffered Readers and Writers
- Print Writers
- Piped Readers and Writers
- Filtered Readers and Writers
- File Viewer Finis
Formatted I/O with java.text
- Formatted I/O with java.text
- The Old Way
- Choosing a Locale
- Number Formats
- Specifying Width with FieldPosition
- Parsing Input
- Decimal Formats
Devices
The Java Communications API
- The Java Communications API
- The Architecture of the Java Communications API
- Identifying Ports
- Communicating with a Device on a Port
- Serial Ports
- Parallel Ports
USB
- USB
- USB Architecture
- Finding Devices
- Controlling Devices
- Describing Devices
- Pipes
- IRPs
- Temperature Sensor Example
- Hot Plugging
The J2ME Generic Connection Framework
- The J2ME Generic Connection Framework
- The Generic Connection Framework
- ContentConnection
- Files
- HTTP
- Serial I/O
- Sockets
- Server Sockets
- Datagrams
Bluetooth
- Bluetooth
- The Bluetooth Protocol
- The Java Bluetooth API
- The Local Device
- Discovering Devices
- Remote Devices
- Service Records
- Talking to Devices
Character Sets
