Load Balancers
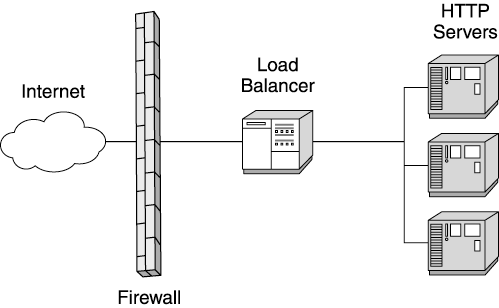
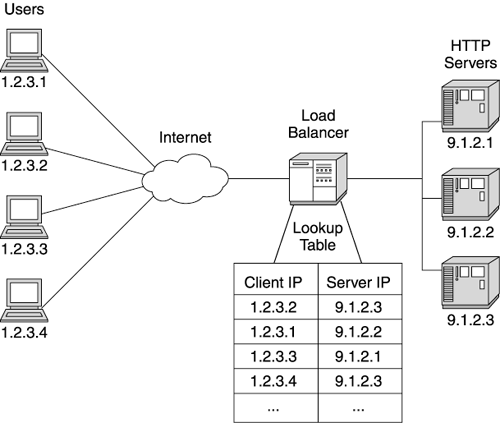
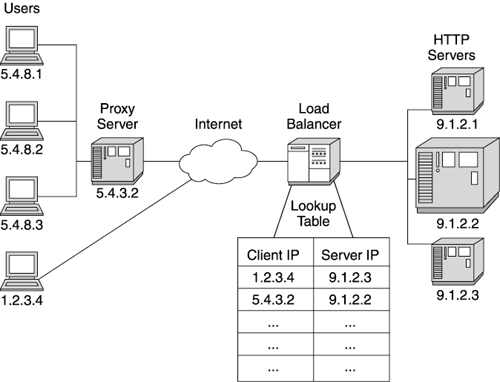
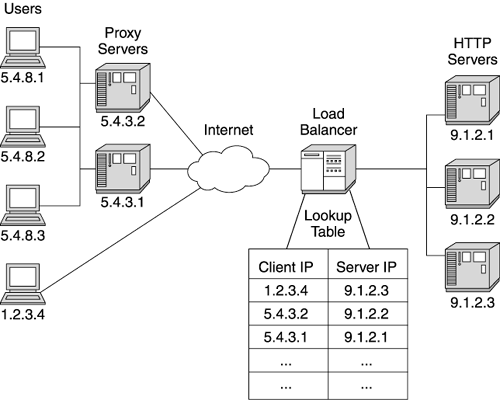
| All but the most trivial web sites use load balancers. Also known as "IP sprayers," load balancers take incoming requests and distribute them across multiple servers. The distribution of requests hides the servers actually responding to the request, and allows the web site to add or reconfigure hardware behind the load balancer without affecting the inbound traffic. Figure 3.6 shows a typical load balancer configuration. Figure 3.6. A load balancer distributing HTTP traffic Your load balancer's implementation depends on the brand you choose. Some companies implement the load balancer in hardware, while others provide load balancing software. (If you use load balancing software, we recommend dedicating a machine to support this function.) Regardless of the implementation, the basic principle behind these products is the same. The load balancer operates at the IP level of your network, analyzing incoming request packets and passing them to the IP addresses of your web site servers. At this level, the load balancer really doesn't analyze the request itself; it only looks at the IP header information. This is a very fast operation, requiring little processing time. Load balancers handling simple IP spraying usually support high traffic volumes because they operate so efficiently . A properly configured load balancer rarely presents performance issues. However, load balancers increasingly add more complexity to their functionality to support sophisticated distribution algorithms. Many support several configurable routing algorithms, as well as allowing customers to program their own routing algorithms. Among routing algorithms, the simplest ” round-robin ”is usually also the fastest for the load balancer to execute. In round-robin, each incoming request routes to the next server in turn . Most load balancers use this algorithm by default if no other is specified. Round- robin works reasonably well, but doesn't adapt well to run-time load problems or different machine capacities . If one server gets a disproportionate number of long-running or computationally intensive requests, this algorithm continues sending more requests to the overused server. Round-robin also proves ineffective when the web site uses a mixture of server machines with different load capacities. To avoid this problem, some web sites use a weighted load distribution algorithm. This algorithm proves useful when balancing traffic among servers with different load capacities. Weighted distribution assigns a percentage of the overall load to particular downstream servers. This allows the load balancer to send the smaller servers fewer requests, while sending more work to larger or newer machines. Sophisticated load balancers support dynamic weighting of their distribution algorithms. These balancers actively monitor the downstream servers and determine their capacity for more traffic. The balancer makes adjustments to the load distribution so that busy servers receive less traffic, while idle servers receive more. Of course, as the complexity of the distribution algorithm increases , the throughput of the load balancer tends to decrease. Remote server monitoring and weighting computations make the load balancer less efficient. Before configuring sophisticated distribution algorithms, determine their impact on the load balancer's performance. Not surprisingly then, the most flexible distribution scheme, content-based routing, is also the slowest. Content-based routing routes requests to servers depending on the data within the request. Typically, routing occurs based on the request's URL or parameters. Obviously, this requires more than an examination of the IP headers: The load balancer must actually examine the request content before making a routing decision. To examine the content, the load balancer must first collect all the request packets (in simple IP routing, the balancer usually sends the packets individually to the destination server) and retrieve the request content. After parsing the content for routing information, the load balancer forwards the request to the correct server. Because of the parsing activity, some load balancers pair with an HTTP server to support this algorithm. (Note: This routing technique does not work with SSL (Secure Socket Layer) because of the complexities of managing encryption keys between the web site and the browser.) In addition to request distribution, load balancers also handle server failures inside the web site. If a downstream server stops responding to forwarded requests, most load balancers remove it from their distribution list and stop sending it requests. As you might guess, depending on the load balancer, the algorithms for detecting and managing a server outage vary in complexity and performance overhead. Likewise, your load balancer may support a hot-failover function. In this configuration, the web site configures two load balancers. One balancer monitors the other and takes over load distribution if the primary load balancer fails. This prevents the load balancer from becoming a single point of failure for your web site. Affinity RoutingSophisticated web sites frequently need more than a request distribution algorithm. These sites often require users to return to the same server machine in the web site cluster throughout their visit to the web site. In these cases, the load balancer keeps track of the server handling a particular user's requests and continually routes the user to the same server. We call this feature affinity routing (also called "sticky routing"). Affinity routing reduces SSL overhead by returning an incoming visitor to the same HTTP server repeatedly. This allows the browser to complete an SSL transaction with the same HTTP server, requiring only one SSL handshake sequence. As we'll discuss later, affinity routing also assists with returning a user to her session information throughout a web site visit. Every incoming TCP/IP packet contains the IP address of the requesting machine. (Usually, this is the address of the browser machine, though there are times when the address is actually a proxy machine, not the browser.) When the load balancer gets the initial request from a browser, it uses one of the algorithms discussed above to decide which server receives the request. The load balancer then adds the browser's IP address to a table, along with the IP address of the server it chose to handle the request. When another request comes from the same IP address, the balancer looks up the server's IP address in the table, based on the browser's address, and routes all subsequent requests from the browser to the same server. (See Figure 3.7 for a diagram of a load balancer using an affinity algorithm.) Figure 3.7. An example of load balancer affinity routing Despite its simplicity, load balancer affinity routing sometimes encounters problems in production web sites. The most familiar problem arises when a disproportionate number of clients access the web site from behind a proxy server (for example, traffic originating from a large ISP or a large enterprise network). The ISP's proxy server hides the real IP addresses of all the browser machines accessing the network through it. Therefore all incoming requests from users of that ISP contain the same IP address . So instead of an IP address representing one user, the ISP's proxy address might represent hundreds or thousands of users. This problem (sometimes called a "net quasar") results in wildly uneven loading of the web site's servers. The load balancer routes all of the users from the ISP or enterprise proxy to the same server machine because of the structure of the affinity routing table (one IP address maps to only one server). Figure 3.8 provides a small example of this problem. However, as more ISPs enter the market, overall traffic load becomes more evenly distributed, reducing the severity of this problem. Nonetheless, if you anticipate large volumes of traffic originating behind a proxy server, consider the impact of these users on any IP affinity routing at your web site. Figure 3.8. Proxy server impacting even load distribution with affinity routing The second major affinity routing problem also involves proxy servers. Again, the client uses the ISP's proxy server to access the Internet. In this case, the ISP uses multiple proxy servers to support the client load. Figure 3.9 shows such a setup. In this example, a user's first request routes through a particular proxy server, but the second request routes through a different proxy server. This time, the load balancer sees a different incoming IP address and routes the request to a different HTTP server. This breaks affinity: The user request receives service from a different machine in the cluster. Some possible solutions to this problem include using more intelligent routing (based on cookies or content parameters) to uniquely identify the user or to share the user's critical information so it's available to any machine in the cluster. Application servers also provide software load balancing that alleviates this problem, as discussed below. Figure 3.9. Users accessing a web site through a proxy server farm Recent improvements in vertical and horizontal scaling have changed the landscape of load distribution. In the early days of Java application servers, web sites used affinity routing to repeatedly send users to the server holding their HTTP session data. To accomplish this, the site paired each application server instance with its own HTTP server. This worked well because at that time each server machine typically ran only one application server instance (JVM). Thus the load balancer mapped the incoming user's IP address to the HTTP server machine's IP address, which corresponded to the single application server instance associated with the HTTP server. Cloning changed the usefulness of load balancers in resolving HTTP session issues. Because multiple application server instances (JVMs) sometimes run on the same machine, mapping a user to a server's IP address does not suffice any more. Cloned application servers need more affinity support than the IP affinity provided by a load balancer. Usually, the application server vendor provides load distribution software to distribute load among the clones and to provide affinity routing if required. |
EAN: 2147483647
Pages: 126