1.2 The Undefined Web
| < Day Day Up > |
| The concept of a browser talking to a web server is perhaps the most popular client/server system devised (email is the other major one). It didn't take very long before the popularity of this model lead to some interesting questions about the proper relationship between the client and the server. 1.2.1 Scraping DataA couple of web sites, desperate for content, realized that they could scrape the HTML of other sites and display some or all of that information in a different format. For example, let's say that you ran a small web site devoted to the glories of Davis, CA. As shown in Figure 1-4, you set up a site that grabs the weather report from another site (steps 2 and 3) and then grabs the stock quote for the public corporation that runs the local gas station (steps 4 and 5). The user can visit your site and get your information as well as the data from the other two sites as well; throw a banner ad at the top of the page, and you'll soon be rich! Figure 1-4. An application server scraping other sites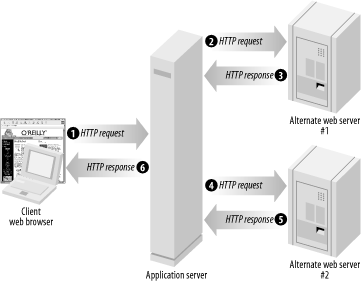 The problem with scraping (dubious ethics aside) is that HTML is extremely fragile. The only promise given with HTML is that a browser can render properly formatted HTML in a human-readable format, and even that's a bit of a reach sometimes. A very minor formatting change can break your HTML parser, and the operator of the site doesn't care (or is actively trying to foil your attempts to steal content). Now, let's take this to the next logical step. Let's say the weather and stock guys notice that you're reading their data, and both call you and generously offer to trade you legitimate access to their data in exchange for links back to their site. You agree, and now you need to set this up. The immediate question becomes: what standards and specifications do you use to tie all this information together? This is perhaps one of the most contentious and controversial aspects of web services. How do you decide the actual implementation details for how these systems are going to talk to each other?
1.2.2 Fragile InterdependenceOne of the most significant problems when trying to figure out how to get two systems to talk to each other is sorting out what dependencies, assumptions, and standards to use. For example, we assume that we will be using TCP/IP and the other core technologies of the Internet, but we may not (for example) be comfortable assuming that our partners are willing to standardize on Java or .NET technologies. Instead of declaring required technologies by fiat, our first instinct is to wait and see what standards get locked down. Preferably, the standards we choose have several solid implementations and have been in use for some time. This allows us to understand more of the pros and cons of any particular technology. HTML, for example, has been in use for some time, but different web browsers can have wildly different interpretations of a given HTML document. Many of the same problems you see with HTML can be seen with web services; for example, consider the seemingly simple questions of style and perspective reflected in the differences between the HTML pages shown in Examples Example 1-1 and Example 1-2 (both display the same text on screen). Example 1-1. Simple HTML<HTML> <HEAD> </HEAD> <BODY> <P ALIGN="CENTER"><B>This is my text!</B></P> </BODY> </HTML> Example 1-1 shows a very human-readable (yet not particularly elegant or sophisticated) version of an HTML page. Example 1-2 shows a page without any extraneous formatting or whitespace, with proper markers and the (admittedly gratuitous) use of CSS. Example 1-2. Complex HTML<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"><html><head> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1"> <style type="text/css"><!-- P { font-style: normal; font-weight: bold; text-align: center; } --></style></head> <body><p>This is my text! </p></body></html>Sometimes differences are merely a matter of style and not substance. For example, consider the differences in method naming standards between Java and Microsoft C/C++. Java developers typically prefer relatively verbose naming, with a strong object-as-noun, method-as-verb nomenclature, heavily influenced by the patterns put forth by the JavaBeans specification that you'll find at:
Microsoft developers are more likely to use Hungarian notation, which as even Microsoft notes, "make the variable names look a bit as though they're written in some non-English language"; see the following for more information:
However,.NET is phasing this out; see the following:
While style issues are relevant when you talk about web services as you'll see, a perfectly usable set of web service interfaces provided by a vendor can still feel very awkward if the interfaces are based on another style and mental model the important thing is that services can still be accessed in a reliable, predictable manner. The goal when using web services is to get away from wildly undefined and fragile processes (such as scraping HTML) and instead move toward refined, manageable systems. |
| < Day Day Up > |