2.2 Coordination Challenges
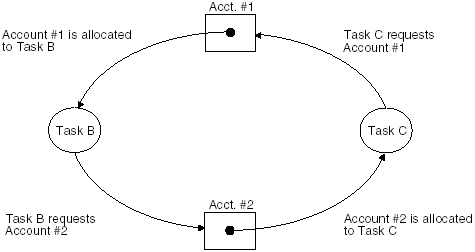
| If a program has routines that can execute in parallel, and these routines share any files, devices, or memory locations, then several coordination issues are introduced. For example, lets say we have an electronic bank withdrawal and deposit program that is divided into three tasks that can execute in parallel. We label the tasks A, B, C. Task A receives requests from Task B to make withdrawals from an account. Task A also receives requests from Task C to make deposits to an account. Task A accepts and processes requests on a first-come, first-serve basis. What if we have an account that has a balance of $1,000 and Task C wants to make a $100 deposit to the account and Task B wants to make a $1,100 withdrawal from the account? What happens if Task B and Task C both try to update the same account at the same time? What would the balance be? Obviously an account balance can only hold one value at a time. Task A can only apply one transaction at a time to the account, so there's a problem. If Task B's request executes a fraction of a second faster than Task C, then the account will have a negative balance. On the other hand, if Task C gets to the account first, then the account will not have a negative balance. So the balance of the account depends on which task happens to get its request to Task A first. Furthermore, we can execute Tasks B and C several times, each time starting with the same amounts, and sometimes Task B would execute a fraction of a second faster and sometimes Task C would execute faster. Clearly some form of coordination is in order. To coordinate tasks that are executing in parallel requires communication between the tasks and synchronization of their work. Four common types of problems occur when the communication or the synchronization is incorrect. Problem #1 Data RaceIf two or more tasks attempt to change a shared piece of data at the same time and the final value of the data depends simply on which tasks get there first, then a race condition has occurred. When two or more tasks are attempting to update the same data resource at the same time, the race condition is called data race. In our electronic banking program, which task gets to the account balance first turns out to be a matter of operating system scheduling, processor states, latency, and chance. This situation creates a race condition. Under these circumstances, what should the bank report as the account's real balance? So while we would like our electronic banking program to be able to simultaneously handle many banking deposits and withdrawals, we need to coordinate the tasks in the program if the deposits and withdrawals happen to be applied to the same account. Whenever tasks concurrently share a modifiable resource, rules and policies will have to be applied to the task's access. For instance, in our banking program we might apply any deposits to the account before we apply any withdrawals. We might set a rule that only one transaction has access to an account at a time. If more than one transaction for the same account arrives at the same time, then the transactions must be held and organized according to some rule and then granted access one at a time. These organization rules help to accomplish proper synchronization. Problem #2 Indefinite PostponementScheduling one or more tasks to wait until some event or condition occurs can be tricky. First, the event or condition must take place in a timely fashion. Second, it requires carefully placed communications between tasks. If one or more tasks are waiting for a piece of communication before they execute and that communication either never comes, comes too late, or is incomplete, then the tasks may never execute. Likewise, if the event or condition that we assumed would eventually happen actually never occurs, then the tasks that we have suspended will wait forever. If we suspend one or more tasks waiting on some condition or event that never occurs, this is known as indefinite postponement. In our electronic banking example, if we set up rules that cause the withdrawal tasks to wait until all deposit tasks are completed, then the withdrawal tasks could be headed for indefinite postponement. The assumption is that there are deposit tasks. If no deposit requests are made, what will cause the withdrawal tasks to execute? What if the reverse happens, that is, what if deposit requests are continuously made to the same account? As long as a deposit is in progress, no withdrawal can be made. This situation can indefinitely postpone withdrawals. Indefinite postponement might take place if no deposit tasks appear or if deposit tasks constantly appear. What if deposit requests appear correctly but we fail to properly communicate the event? So as we try to coordinate our parallel task's access to some shared data resource, we have to be mindful of situations that can create indefinite postponement. We discuss techniques for avoiding indefinite postponement in Chapter 5. Problem #3 DeadlockDeadlock is another waiting-type pitfall. To illustrate an example of deadlock, lets assume that the three tasks in our electronic banking program example are working with two accounts instead of one. Recall that Task A receives withdrawal requests from Task B and deposit requests from Task C. Tasks A, B, and C can execute concurrently. However, Tasks B and C may only update one account at a time. Task A grants access on a first-come, first-serve basis. Lets say that Task B has exclusive access to Account 1, and Task C has exclusive access to Account 2. But Task B needs access to Account 2 to complete its processing and Task C needs access to Account 1 to complete its processing. Task B holds on to Account 1 waiting for Task C to release Account 2 and Task C holds on to Account 2 waiting for Task B to release Account 1. Tasks B and C are engaged in a deadly embrace, also known as a deadlock. Figure 2-3 shows the deadlock situation between Tasks B and C. Figure 2-3. The deadlock situation between Tasks B and C. The form of deadlock shown in Figure 2-3 requires concurrently executing tasks that have access to some shared writeable data to wait on each other for access to that shared data. In Figure 2-3 the shared data are Accounts 1 and 2. Both tasks have access to these accounts. It happens that instead of one task getting access to both accounts at the same time, each task got access to one of the accounts. Since Task B can't release Account 1 until it gets Account 2, and Task C can't release Account 2 until it gets Account 1, the electronic banking program is locked. Notice that Tasks B and C can drive another task(s) into indefinite postponement. If other tasks are waiting on access to Accounts 1 or 2 and Tasks B and C are engaged in a deadlock, then those tasks are waiting for a condition that will never happen. In attempting to coordinate concurrently executing tasks, deadlock and indefinite postponement are two of the ugliest obstacles that must be overcome . Problem #4 Communication DifficultiesMany commonly found parallel environments (e.g., clusters) often consist of heterogeneous computer networks. Heterogeneous computer networks are systems that consist of different types of computers often running different operating systems with different network protocols. The processors involved may have different architectures, different word sizes, and different machine languages. Besides different operating systems, different scheduling and priority schemes might be in effect. To make matters worse , each system might have different qualities of data transmission. This makes error and exception handling particularly challenging. The heterogeneous nature of the system might include other differences. For instance, we might need to share data and logic between programs written in different languages or developed using different software models. The solution might be partially implemented in Fortran, C++, and Java. This introduces interlanguage communication issues. Even when the distributed or parallel environment is not heterogeneous, there is the problem of communicating between two or more processes or between two or more threads. Because each process has its own address space, sharing variables , parameters, and return values between processes requires the use of IPC (inter-process communication) techniques. While IPC is not necessarily difficult, it adds another level of design, testing, and debugging to the system. The POSIX specification supports five basic mechanisms used to accomplish communication between processes:
Each of these IPC mechanisms have strengths, weaknesses, traps, and pitfalls that the software designer and developer must manage in order to facilitate reliable and efficient communication between two or more processes. Communication between two or more threads (sometimes called lightweight processes) is easier because threads share a common address space. This means that each thread in the program can easily pass parameters, get return values from functions, and access global data. However, if the communication is not appropriately designed, then deadlock, indefinite postponement, and other data race conditions can easily occur. Both parallel and distributed programming have these four types of coordination problems in common. Although purely parallel processing systems are different from purely distributed processing systems, we have purposely blurred the lines between the coordination problems in a distributed system versus the coordination problems in a parallel system. This is partly because there is an overlap between the kinds of problems encountered in parallel programming and those encountered in distributed programming. It's also partly because the solutions to the problems in one area are often applicable to problems in the other. However, the primary reason we lose the distinction is that hybrid systems that are part parallel and part distributed are quickly becoming the norm. The state of the art in parallel computing involves clusters, beowolfs, and grids. Exotic cluster configurations is comprised of commodity, off-the-shelf parts that are readily available. These architectures involve multiple computers with multiple processors. Furthermore, single processor systems are on the decline. So, in the future purely distributed systems will be built with computers that have multiple processors (forcing the hybrid issue). This means that as a practical matter the software designer and developer will most likely be faced with problems of distribution and parallelization . Therefore, we discuss the problems in the same space. Table 2-1 presents a matrix of the combinations of parallel and distributed programming with hardware configurations. Table 2-1. A Matrix of the Combinations of Parallel and Distributed Programming with Hardware Configurations
Notice in Table 2-1 that there are configurations where parallelism is accomplished by using multiple computers. This can be the case using the PVM library. Likewise, there are configurations where distribution can be accomplished on a single computer using multiple processes, or threads. The fact that multiple processes or threads are involved means that the work of the program is "distributed." The combinations in Table 2-1 imply that coordination problems that are normally associated with distributed programming can pop up in parallel programming situations and problems that are normally associated with parallel programming can appear in distributed programming situations. Regardless of the hardware configuration, there are two basic mechanisms for communicating between two or more tasks: shared memory, and message passing. To effectively use the shared memory mechanism, the programmer must constantly be aware of data race, indefinite postponement, and deadlock pitfalls. The message passing scheme offers other showstoppers such as interrupted transmissions (partial execution), garbled messages, lost messages, wrong messages, too long messages, late messages, early messages, and so on. Much of this book is about the effective use of both mechanisms. |
EAN: 2147483647
Pages: 133