An Introduction to XML in .NET
The previous section described the features of .NET that are aimed at accessing relational data, and how they relate to the way you work with data compared to the traditional techniques used in previous versions of ADO. However, there is another technique for working with data within the .NET Framework.
XML is fast becoming the lingua franca of the Web, and is being adopted within many other application areas as well. We discussed the reasons for this earlier, and now look at how XML is supported within .NET. This relates to the .NET support for relational data, as XML is the standard persistence format for data within the .NET data access classes. However, there are also several other techniques for reading, writing, and manipulating XML data and the associated XML-based data formats.
In this book, we're assuming that the reader is familiar with XML as a data storage mechanism, and how it is used through an XML parser and with the associated technologies such as XSLT. Our aim is to show the way that the .NET Framework and ASP.NET can be used with XML data.
| Note | For a primer and other reference materials covering XML and the associated standards and technologies, check out the Wrox Press list of XML books at http://www.wrox.com/. |
The Fundamental XML Objects
The W3C (at http://www.w3.org/) provides standards that define the structure and interfaces that should be provided by applications used for accessing XML documents. This is referred to as the XML Document Object Model ( DOM ), and is supported under .NET by the XmlDocument and XmlDataDocument objects, as shown in Figure 8-12. They provide full support for the XML DOM Level 2 Core. Within their implementation are the node types and objects that are required for the DOM interfaces, such as the XmlElement and XmlAttribute objects:
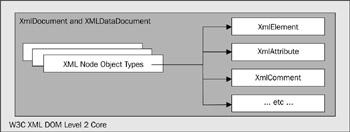
Figure 8-12:
However, .NET extends the support for XML to provide much more in the way of techniques for manipulating XML documents, XML Schemas, and stylesheets. Figure 8-13 shows the main classes that are used when working with XML documents within .NET applications, and how they are related by showing the kinds of paths that you can follow when working with XML data:
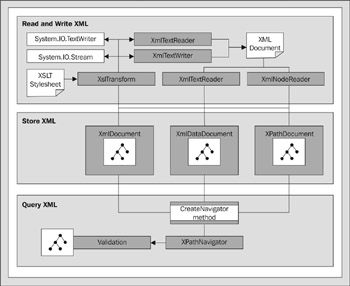
Figure 8-13:
Basically, the classes shown in Figure 8-13 fall into three categories:
-
Reading, writing, and transforming XML :The XmlTextReader , XmlNodeReader , and XmlTextWriter “ plus the XslTransform object for creating files in a different format to the original XML document.
-
Storing and manipulating XML :The function of the XmlDocument , XmlDataDocument , and XPathDocument objects.
-
Querying XML :The function of XPathNavigator object.
There is some overlap between these functions, of course. To validate an XML document while reading it, you can use an XmlValidatingReader , and there are other objects for creating and editing XML Schemas that aren't covered in this book. You can also use the XslTransform object to perform querying of a document as well as transforming it into different formats.
In this section, we'll briefly overview the objects and their commonly used methods , and then to show some simple examples. We'll come back to XML again in Chapter 11 and see some more advanced techniques.
The Document Objects
There are three implementations of the document object for storing and working with XML:
-
The XmlDocument object is the .NET implementation of the standard DOM Level 2 XMLDocument interface. The properties and methods it exposes include those defined by W3C for manipulating XML documents, plus some extensions to make common operations easier.
-
The XmlDataDocument object is an extension of the XmlDocument object, providing the same set of properties and methods. However, it also acts as a "bridge" between XML and relational data access methods. Once loaded with an XML document, it can expose it as a DataSet object. This allows you to use relational data programming techniques to work with the data, as well as the same XML DOM techniques that are used with an XmlDocument object.
-
The XPathDocument object is a fast and compact implementation of an XML storage object that is designed for access via an XPathNavigator object, using only XPath queries or navigation element-by-element using the "pull" technique.
The Commonly Used XML Document Methods
The XPathDocument object has no really useful public methods other than CreateNavigator , as it is designed solely to work with an XPathNavigator object. However, the other two document objects expose the full set of properties and methods specified in the W3C XML DOM Level 2 Core. The extensions to these properties and methods include several very useful methods regularly used to work with XML documents.
The following table shows the extensions for creating specific types of node, and accessing existing nodes in the XmlDocument and XmlDataDocument objects:
| Method | Description |
|---|---|
| Createxxxxxx | Creates a node in the XML document depending on the actual method name . Examples are CreateElement , CreateComment , and CreateTextNode . |
| CloneNode | Creates a duplicate of an XML node (for example, a copy of an element). |
| GetElementById | Returns the single node with the specified value for its ID attribute. |
| GetElementsByTagname | Returns a collection of nodes that contains all the elements with the specified element name. |
The following table shows the series of useful methods that are available for loading and saving XML to and from the XmlDocument and XmlDataDocument objects:
| Method | Description |
|---|---|
| Load | Loads an XML document from a disk file, a Stream , or an XmlTextReader |
| LoadXml | Loads an XML document from a String |
| Save | Saves the entire XML document to a disk file, a Stream , or an XmlTextWriter |
| ReadNode | Loads a node from an XML document that is referenced by an XmlTextReader or XmlNodeReader |
| WriteTo | Writes a node to another XML document that is referenced by an XmlTextWriter |
| WriteContentTo | Writes a node and all its descendents to another XML document that is referenced by an XmlTextWriter |
To use an XPathNavigator with any of the three types of XML document object, create it using the CreateNavigator method as shown in the following table:
| Method | Description |
|---|---|
| CreateNavigator | Creates and returns an XPathNavigator based on the currently loaded document. Applies to all three document objects. Optionally, for the XmlDocument and XmlDataDocument only, accepts a parameter that is a reference to a node within the document that will act as the start location for the navigator. |
The XmlDataDocument adds a single property to those exposed by the XmlDocument class, as shown in the following table:
| Property | Description |
|---|---|
| DataSet | Returns the contents of the XML document as an ADO.NET DataSet . |
The XmlDataDocument also adds methods that provide extra access to the contents of the document, treating it more like a rowset or data table, as shown in the following table:
| Method | Description |
|---|---|
| GetRowFromElement | Returns a DataRow representing the element in the document. |
| GetElementFromRow | Returns an XmlElement representing a DataRow in a table within a DataSet . |
The XPathNavigator Class
In order to make working with XML documents easier, the System.Xml namespace classes include the XPathNavigator , which can be used to navigate within an XML document or to query the content of the document using an XPath expression. Note that an XPathNavigator can be used with any of the XML document objects “ not just an XPathDocument . You can create an XPathNavigator based on an XmlDocument or an XmlDataDocument as well.
-
The XPathNavigator provides methods and properties that allow cursor-style navigation through the XML document; for example, by stepping through the nodes (elements and attributes) in order, or by skipping to the next node of a specific type.
-
The XPathNavigator provides methods that accept an XPath expression, the name of a node or a node type, and return one or more matching nodes. You can then iterate through these nodes.
An XPathNavigator can only be created from an existing document object. This is done using the CreateNavigator method:
Dim objNav1 As XPathNavigator = objXMLDoc.CreateNavigator() Dim objNav2 As XPathNavigator = objXMLDataDoc.CreateNavigator() Dim objNav3 As XPathNavigator = objXPathDoc.CreateNavigator()
The Commonly Used XPathNavigator Methods
The XPathNavigator is designed to act as a pull model interface for an XML document. It allows you to navigate across a document, and select and access nodes within that document. You can also create two (or more) navigator objects against the same document, and compare their positions .
To edit the XML document(s), you can use the reference to the current node exposed by the navigator, or an XPathNodeIterator that contains a collection of nodes, and call the methods of that node or collection. At the same time, the XPathNavigator exposes details about the current node directly, so there are two ways to get information about each node.
The table that follows shows methods used to move around within the document, making different nodes current in the navigator, and to create a new navigator:
| Method | Description |
|---|---|
| MoveToxxxxxx | Moves the current navigator position. Examples are MoveToFirst , MoveToFirstChild , MoveToParent , MoveToAttribute , and MoveToRoot . |
| Clone | Creates a new XPathNavigator that is automatically located at the same position in the document as the current navigator. |
| IsSamePosition | Indicates if two navigators are at the same position within the document. |
The following table shows the methods used to access and select parts of the content of the document:
| Method | Description |
|---|---|
| GetAttribute | Returns the value of a specified attribute from the current node in the navigator |
| Select | Returns an XPathNodeIterator (a NodeList ) containing a collection of nodes that match the specified XPath expression |
| SelectAncestors | Returns an XPathNodeIterator (a NodeList ) containing a collection of all the ancestor nodes in the document of a specific type or which have a specific name |
| SelectDescendants | Returns an XPathNodeIterator (a NodeList ) containing a collection of all the descendant nodes in the document of a specific type or which have a specific name |
| SelectChildren | Returns an XPathNodeIterator (a NodeList ) containing a collection of all the child nodes in the document of a specific type or which have a specific name |
The XmlTextWriter Class
When using an XmlDocument to create a new XML document, you must create document fragments and insert them into the document in a specific way “ a technique that can be error-prone and complex. The XmlTextWriter can be used to create an XML document node by node in serial fashion by simply writing the tags and content to the output stream using the comprehensive range of methods that it provides.
-
The XmlTextWriter takes as its source either a TextWriter that refers to a disk file, the path and name of a disk file, or a Stream that will contain the new XML document. It exposes a series of properties and methods that can be used to create XML nodes and other content, and output them to the disk file or stream directly.
-
The XmlTextWriter can also be specified as the output device for methods in several other objects, where it automatically streams the content to a disk file, a TextWriter , or a Stream .
Note The TextReader , TextWriter , and Stream classes are discussed in Chapter 16.
The Commonly Used XmlTextWriter Methods
The most commonly used methods of the XmlTextWriter are listed in the following table:
| Method | Description |
|---|---|
| WriteStartDocument | Starts a new document by writing the XML declaration to the output. |
| WriteEndDocument | Ends the document by closing all un-closed elements, and flushing the content to disk. |
| WriteStartElement | Writes an opening tag for the specified element. The equivalent method for creating attributes is WriteStartAttribute . |
| WriteEndElement | Writes a closing tag for the current element. The equivalent method for completing an attribute is WriteEndAttribute . |
| WriteElementString | Writes a complete element (including opening and closing tags) with the specified string as the value. The equivalent method for writing a complete attribute is WriteAttributeString . |
| Close | Closes the stream or disk file and releases any references held. |
The XmlReader Classes
You need to be able to read documents from other sources, rather than creating them from scratch. The XmlReader class is a base class from which two public classes, XmlTextReader and XmlNodeReader , inherit.
-
The XmlTextReader takes as its source either a TextReader that refers to an XML disk file, the path and name of an XML disk file, or a Stream containing an XML document. The contents of the document can be read one node at a time, and the object provides information about each node and its value as it is read.
-
The XmlNodeReader takes a reference to an XmlNode instance (usually from within an XmlDocument ) as its source, allowing you to read specific portions of an XML document rather than having to read all of it, if you only want to access a specific node and its children.
-
The XmlTextReader and XmlNodeReader can be used standalone to provide simple and efficient access to XML documents or as the source for another object whereby they automatically read the document and pass it to the parent object.
Like the XPathNavigator , the XmlTextReader provides a pull model for accessing XML documents node-by-node, rather than parsing them into a tree in memory as is done in an XML parser. This allows larger documents to be accessed without impacting on memory usage, and can also make coding easier, depending on the task you need to accomplish.
Furthermore, if you are just searching for a specific value, you won't always have to read the whole document. Taking a broad average, you will reach the specific node you want after reading only half the document. This is considerably faster and more efficient than reading and parsing the whole document every time.
The Commonly Used XmlReader Methods
The XmlTextReader and the XmlNodeReader objects have almost identical sets of properties and methods. The most commonly used methods are shown in the following table:
| Method | Description |
|---|---|
| Read | Reads the next node into the reader object where it can be accessed. Returns False if there are no more nodes to read. |
| ReadInnerXml | Reads and returns the complete content of the current node as a string, containing all the markup and text of the child nodes. |
| ReadOuterXml | Reads and returns the markup of the current node and the complete content as a string, containing all the markup and text of the child nodes as well. |
| ReadString | Returns the string value of the current node. |
| GetAttribute | Returns the value of a specified attribute from the current node in the reader. |
| GetRemainder | Reads and returns the remaining XML in the source document as a string. Useful if you are copying XML from one document to another. |
| MoveToxxxxxx | Moves the current reader position. Examples are MoveToAttribute , MoveToContent , and MoveToElement . |
| Skip | Skips the current node in the reader and moves to the next one. |
| Close | Closes the stream or disk file. |
The XmlValidatingReader Class
There is another object based on the XmlReader base class “ the XmlValidatingReader . You can think of this as an XmlTextReader that does document validation against a schema or DTD. You can create an XmlValidatingReader from an existing XmlReader (an XmlTextReader or XmlNodeReader ), from a Stream , or from a String that contains the XML to be validated .
Once the XmlValidatingReader is created, it can be used just like any other XmlReader . However, it raises an event when a schema validation error occurs, allowing you to ensure that the XML document is valid against one or more specific schemas.
The XslTransform Class
One common requirement when working with XML is the need to transform a document using XML Stylesheet Language (XSL or XSLT). The .NET Framework classes provide the XslTransform object, which is specially designed to perform either XSL or XSLT transformations.
The Commonly Used XslTransform Methods
The XslTransform class has two methods that are used for working with XML documents and XSL/XSLT stylesheets, as shown in the following table:
| Method | Description |
|---|---|
| Load | Loads the specified XSL stylesheet and any stylesheets referenced within it by xsl:include elements |
| Transform | Transforms the specified XML data using the currently loaded XSL or XSLT stylesheet, and outputs the results |
Let's look at some of the common tasks that need to be carried out using XML documents.
EAN: 2147483647
Pages: 243