Extracting data from the operational systems
5.2 Extracting data from the operational systems
Once you have identified the data you need in the warehouse for analysis purposes, you need to locate the operational systems within the company that contain that data. The data needed for the warehouse is extracted from the source operational systems and written to the staging area, where it will later be transformed. To minimize the performance impact on the source database, data is generally downloaded without applying any transformations to it.
Often the owners of the operational systems will not allow the warehouse developers direct access to those systems but will provide periodic extracts. These extracts are generally in the form of flat, sequential operating system files, which will make up the staging area.
Application programs need to be developed to select the fields and records needed for the warehouse. If the data is stored in a legacy system, these may be written in COBOL and require special logic to handle things such as repeating fields in the "COBOL occurs clause." The data warehouse designers need to work closely with the application developers for the OLTP systems who are building the extract scripts to provide the necessary columns and formats of the data.
As part of designing the ETL process, you need to determine how frequently data should be extracted from the operational systems. It may be at the end of some time period or business event, such as at the end of the day or week or upon closing of the fiscal quarter. It should be clearly defined what is meant by the "end of the day" or the "last day of the week," particularly if you have a system used across different time zones. The extraction may be done at different times for different systems and staged to be loaded into the warehouse during an upcoming batch window. Another aspect of the warehouse design process involves deciding what level of aggregation is to be used to answer the business queries. This also has an impact on what and how much data is extracted and transported across the network.
Some operational systems may be in relational databases, such as Oracle 8i or 9i, Oracle Rdb, DB2/MVS, Microsoft SQL Server, Sybase, or Informix. Others may be in a legacy database format, such as IMS or Oracle DBMS. Others may be in VSAM, RMS indexed files, or some other structured file system.
If you are able to access the source systems directly, you can get the data out by a variety of techniques depending on the type of system the data is in. For small amounts of data, you can use a gateway or ODBC. For larger amounts of data, a custom program directly connecting to the source database in the database's native Application Programming Interface (API) can be written. Many ETL tools simplify the extraction process by providing connectivity to the source.
5.2.1 Identifying data that has changed
After the initial load of the warehouse, as the source data changes, the data in the warehouse must be updated or refreshed to reflect those changes on a regular basis. A mechanism needs to be put into place to monitor and capture changes of interest from the operational systems. Rather than rebuilding the entire warehouse periodically, only the changes need to be applied. By isolating changes as part of the extraction process, less data needs to be moved across the network and loaded into the data warehouse.
Changed data includes both new data that has been added as well as updates and deletes to existing data. For example, in the EASYDW warehouse, we are interested in all new orders as well as updates to existing product information and customers. If we are no longer selling a product, the product is deleted from the order-entry system, but we still want to retain the history in the warehouse. This is why surrogate keys are recommended for use in the data warehouse. If the product_key is reused in the production system, it does not affect the data warehouse records.
In the data warehouse, it is not uncommon to change the dimension tables, because a column such as a product description may change. Part of the warehouse design involves deciding how changes to the dimensions will be reflected. If you need to keep one version of the old product description, you could have an additional column in the table to store both the current description and the previous description. If you needed to keep all the old product descriptions, you would have to create a new row for each change, assigning different key values. In general, you should try to avoid updates to the fact table.
There are various ways to identify the new data. One technique to determine the changes is to include a time stamp to record when each row in the operational system was changed. The data extraction program then selects the source data based on the time stamp of the transaction and extracts all rows that have been updated since the time of the last extraction. When moving orders from the order processing system into the EASYDW warehouse, this technique can be used by selecting rows based on the purchase_date, as illustrated later in this chapter.
If the source is a relational database, triggers can be used to identify the changed rows. Triggers are stored procedures that can be invoked before or after an event, such as when an insert, update, or delete occurs. The trigger can be used to save the changed records in a table from where the extract process can later retrieve the changed rows. Be very careful of triggers in high-volume applications, since they can add significant overhead to the operational system.
Sometimes you may not be able to change the schema to add a time stamp or trigger. Your system may already be heavily loaded, and you do not want to degrade the performance in any way. Or the source may be a legacy system, which does not have triggers. Therefore, you may need to use a file comparison to identify changes. This involves keeping before and after images of the extract files to find the changes. For example, you may need to compare the recent extract with the current product or customer list to identify the changes.
Changes to the metadata or data definitions must also be identified. Changes to the structure of the operational system, such as adding or dropping a column, impact the extraction and load programs, which may need to be modified to account for the change.
5.2.2 Oracle change data capture
In Oracle 9i a new technique was introduced to facilitate identifying changes when the source system is an Oracle 9i database. The results of all INSERT, UPDATE, and DELETE operations can be saved in tables called change tables. The data extraction programs can then select the data from the change tables.
Change data capture, often referred to as CDC, uses a publish-subscribe interface to capture and distribute the change data, as illustrated in Figure 5.2. The publisher, usually a DBA, determines which user tables in the operational system are used to load the warehouse and sets up the system to capture and publish the change data. A change table is created for each source table with data that needs to be moved to the warehouse.
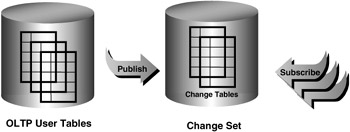
Figure 5.2: Change data capture publish/ subscribe architecture.
The extract programs then subscribe to the source tables; therefore, there can be any number of subscribers. Each subscriber is given his or her own view of the change table. This isolates the subscribers from each other while they are simultaneously accessing the same change tables. The subscribers use SQL to select the change data from their subscriber views. They see just the columns they are interested in and only the rows that they have not yet processed. If the updates of a set of tables are dependent on each other, the change tables can be grouped into a change set. If, for example, you had an order header and an order detail table, these two tables would be grouped together in the same change set to maintain transactional consistency.
In Oracle 9i the changes are captured synchronously, in real time, as part of the transaction on the operational system. The change data is generated as DML operations are performed on the source tables. When a new row is inserted into the user table, it is also stored in the change table. When a row is updated in a user table, the updated columns are stored in the change table. The old values, new values, or both can be written to the change table. When a row is deleted from a user table, the deleted row is also stored in the change table. This does add overhead to each transaction, but simplifies the data extraction process.
Publishing change data
In the EASYDW warehouse, we are interested in all new orders from the order-entry system. The DBA creates the change tables, using the DBMS_LOGMINER_CDC_PUBLISH.CREATE_CHANGE_TABLE supplied procedure, and specifies a list of columns that should be included. A change table contains changes from only one source table.
In many of the examples in this chapter we will use a schema named OLTP, which is part of the operational database. In the following example, the DBA uses the CREATE_CHANGE_TABLE supplied procedure to capture the PRODUCT_ID, CUSTOMER_ID, PURCHASE_DATE, PURCHASE_TIME, PURCHASE_PRICE, SHIPPING_CHARGE, and TODAY_SPECIAL_OFFER columns from the ORDERS table in the OLTP schema. The name of the change table is ORDERS_CHANGE_TABLE. Since there is only one change table in our example, the default and only supported set type in Oracle 9i, SYNC_SET, is used.
After the column list there are a number of parameters, which allow you to specify:
-
Whether you want the change table to contain the old values for the row, the new values, or both
-
Whether you want a row sequence number, which provides the sequence of operations within a transaction
-
The row ID of the changed row
-
The user who changed the row
-
The time stamp of the change
-
The object id of the change record
-
A source column map, which indicates what source columns have been modified
-
A target column map to track which columns in the change table have been modified
-
An options column to append to a CREATE TABLE DDL statement
An application can check either the source column map or the target column map to determine which columns have been modified.
SQL> EXECUTE DBMS_LOGMNR_CDC_PUBLISH.CREATE_CHANGE_TABLE - ('oltp', 'orders_change_table', 'SYNC_SET', 'oltp', 'orders', - 'product_id VARCHAR2(8), - customer_id VARCHAR2(10),- purchase_date date, - purchase_time NUMBER(4,0), - purchase_price NUMBER(6,2), - shipping_charge NUMBER(5,2), - today_special_offer VARCHAR2(1)', - 'BOTH', 'Y','N','Y','Y','N','Y','Y',NULL); A sample of the output will be seen later in the chapter. To see a list of change tables that have been published, query the CHANGE_TABLES dictionary table.
SQL> SELECT CHANGE_TABLE_NAME FROM CHANGE_TABLES; CHANGE_TABLE_NAME ------------------ ORDERS_CHANGE_TABLE
The DBA then grants SELECT privileges on the change table to the subscribers.
Subscribing to change data
The extraction programs create subscriptions to access the change tables. A subscription can contain data from one or more change tables in the same change set.
The all_source_tables dictionary view lists the source tables that have already been published by the DBA. In this example, changes for the ORDERS table in the OLTP schema have been published.
SQL> SELECT * FROM ALL_SOURCE_TABLES; SOURCE_SCHEMA_NAME SOURCE_TABLE_NAME ------------------------------ ------------------ OLTP ORDERS
Creating a subscription
There are several steps to creating a subscription, as follows:
-
Get a subscription handle.
-
List all the tables and columns the extract program wants to subscribe to.
-
Activate the subscription.
In order to create a subscription to the change data, obtain a subscrip-tion handle to the change set using the GET_SUBSCRIPTION_HANDLE procedure. The subscription handle will be passed into the other supplied procedures. In the following example, a variable called "subhandle" is first created.
SQL> VARIABLE subhandle NUMBER; SQL> EXECUTE DBMS_LOGMNR_CDC_SUBSCRIBE.GET_SUBSCRIPTION_HANDLE - (CHANGE_SET => 'SYNC_SET', - DESCRIPTION => 'Changes to orders table', - SUBSCRIPTION_HANDLE => :subhandle);
Next, a subscription is created using the SUBSCRIBE procedure. A subscription can contain one or more tables from the same change set. The SUBSCRIBE procedure lists the schema, table, and columns of change data that the extract program will use to load the warehouse. In this example, the subscribe procedure is used to get changes from all the columns in the ORDERS table in the OLTP schema. The subscribe procedure is executed once for each table in the subscription. In this example we were only interested in changes from one table.
SQL> EXECUTE DBMS_LOGMNR_CDC_SUBSCRIBE.SUBSCRIBE - (SUBSCRIPTION_HANDLE => :subhandle, - SOURCE_SCHEMA => 'oltp', - SOURCE_TABLE => 'orders', - COLUMN_LIST => 'product_id,customer_id,purchase_date, - purchase_time,purchase_price,shipping_charge,today_special_offer');
After subscribing to all the change tables, the subscription is activated using the ACTIVATE_SUBSCRIPTION procedure. Activating a subscription is done to indicate that all tables have been added, and the subscription is now complete.
SQL> EXECUTE DBMS_LOGMNR_CDC_SUBSCRIBE.ACTIVATE_SUBSCRIPTION - (SUBSCRIPTION_HANDLE => :subhandle);
Once a subscription has been created, and new data added to the source tables, it is available for processing.
Processing the change data
To illustrate how change data is processed, two rows are inserted into the orders table. As data is inserted into the orders table, the changes are also stored in the ORDERS_CHANGE_TABLE.
SQL> INSERT INTO oltp.orders(order_id,product_id, - customer_id, purchase_date, purchase_time, purchase_price, - shipping_charge,today_special_offer - sales_person_id,payment_method) - VALUES ('123','SP1031','AB123495','01-JAN-02', 1031,156.45,6.95,'N','SMITH','VISA'); 1 row created. SQL> INSERT INTO oltp.orders(order_id,product_id, - customer_id, purchase_date, purchase_time, purchase_price, - shipping_charge,today_special_offer - sales_person_id,payment_method) - VALUES ('123','SP1031','AB123495','01-FEB-02', 1031,156.45,6.95,'N','SMITH','VISA'); 1 row created. In order to process the change data, a program loops through the steps listed in the following text and illustrated in Figure 5.3. A change table is dynamic; new change data is appended to the change table at the same time the extraction programs are reading from it. In order to present a consistent view of the contents of the change table, data is viewed for a window of time. Prior to accessing the data, the window is extended. In Figure 5.3 rows 1-8 are available in the first window. While the program was processing these rows, rows 9-15 were added to the change table. Purging the first window, and extending the window again can access rows 9-15.
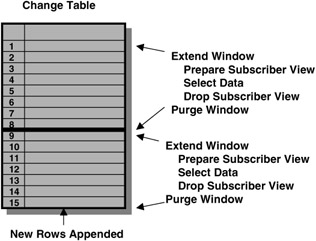
Figure 5.3: Querying change data.
Rather than accessing the change table directly, the subscribers need to create a view. The program prepares a subscriber view, selects the data from the change table using the view, and then drops the view.
Step 1: Extend the window
Change data is only available for a window of time: from the time the EXTEND_WINDOW procedure is invoked until the PURGE_WINDOW procedure is invoked. To see new data added to the change table, the window must be extended using the EXTEND_WINDOW procedure.
SQL> EXECUTE DBMS_LOGMNR_CDC_SUBSCRIBE.EXTEND_WINDOW - (SUBSCRIPTION_HANDLE => :subhandle);
Step 2: Prepare a subscriber view
Instead of accessing the change tables directly, the subscribers need to create a view to retrieve the data. In the following example, a variable called "viewname" is first created.
SQL> VARIABLE viewname VARCHAR2(4000);
The view is created using the PREPARE_SUBSCRIBER_VIEW procedure. The contents of the view will not change, even when more data is added to the change table.
SQL> EXECUTE DBMS_LOGMNR_CDC_SUBSCRIBE.PREPARE_SUBSCRIBER_VIEW - (SUBSCRIPTION_HANDLE => :subhandle, - SOURCE_SCHEMA => 'oltp', - SOURCE_TABLE => 'orders', - VIEW_NAME => :viewname);
Step 3: Select data from the view
In this example, the contents of the view will be examined. First the name of the view is determined and then used as part of the SELECT statement.
SQL> PRINT viewname; VIEWNAME -------------- CDC#CV$2131489
The first column of the output shows the operation: "I" for insert. Next the commit scn and commit time are listed, followed by the user who made the change. The new data is listed for each row. The row source ID, indicated by RSID$, shows the order of the statements in the transaction.
SQL> SELECT OPERATION$, CSCN$, COMMIT_TIMESTAMP$, USERNAME$, CUSTOMER_ID, PRODUCT_ID, RSID$ FROM cdc#cv$2131489; OP CSCN$ COMMIT_TI USERNAME$ CUSTOMER_ID PRODUCT_ID RSID$ --- ----- --------- --------- ----------- ---------- ---- I 345643 28-FEB-02 OLTP AB123495 SP1031 1 I 345643 28-FEB-02 OLTP AB123495 SP1031 2
Step 4: Drop the subscriber view
When you are through processing the data in the subscriber view, it is dropped using the drop_subscriber_view procedure.
SQL> EXECUTE DBMS_LOGMNR_CDC_SUBSCRIBE.DROP_SUBSCRIBER_VIEW - (SUBSCRIPTION_HANDLE => :subhandle, - SOURCE_SCHEMA => 'oltp', - SOURCE_TABLE => 'orders');
Step 5: Purge the window
The window is purged when the data is no longer needed using the purge_window procedure. When all subscribers have purged their windows, the data in those windows is automatically deleted.
SQL> EXECUTE DBMS_LOGMNR_CDC_SUBSCRIBE.PURGE_WINDOW - (SUBSCRIPTION_HANDLE => :subhandle);
Ending the subscription
When an extract program is no longer needed, you can end the subscription, using the drop_subscription procedure.
SQL> EXECUTE DBMS_LOGMNR_CDC_SUBSCRIBE.DROP_SUBSCRIPTION - (SUBSCRIPTION_HANDLE => :subhandle);
Transporting the changes to the staging area
Now that the changes have been captured from the operational system, they need to be transported to the staging area. The extract program could write them to a data file outside the database, use FTP to copy it, and use SQL*Loader or external tables to load the change data into the staging area. Alternatively, the changes could be written to a table and moved to the staging area using transportable tablespaces. Both these techniques are discussed later in this chapter.
EAN: 2147483647
Pages: 91
- Chapter IX Extrinsic Plus Intrinsic Human Factors Influencing the Web Usage
- Chapter XI User Satisfaction with Web Portals: An Empirical Study
- Chapter XV Customer Trust in Online Commerce
- Chapter XVI Turning Web Surfers into Loyal Customers: Cognitive Lock-In Through Interface Design and Web Site Usability
- Chapter XVII Internet Markets and E-Loyalty