Extensible Stylesheet Language Transformation (XSLT)
| for RuBoard |
In the same way that Cascading Style Sheets are commonly used to transform HTML documents, XSLT transforms XML documents. It can transform XML documents from one document format to another, into other XML dialects, or into completely different file formats such as PostScript, RTF, and TeX.
The best part about XSLT is that it's XML. An XSLT document is a regular XML document. "How can that be?" you ask. "Wouldn't you have issues with circular references?" No. XSLT is just another XML dialect . Modern XML parsers are intelligent enough to know how to use the instructions encoded in an XSLT document (which are just ordinary XML tags and attributes and the like) to transform or provide structure to another document.
XML to HTML: An Example
An XSLT style sheet is XML document that's made up of a series of rules, called templates, that are applied to another XML document to produce a third document. These templates are written in XML using specific tags with defined meanings. Each time a template matches something in the source XML document, a new structure is produced in the output. This is often HTML, as the example we're about to examine demonstrates , but it does not have to be.
Here's an XSLT style sheet (Listing 12-7) that transforms our Recipe XML document into an HTML document that closely resembles the HTML document we built by hand earlier in the chapter:
Listing 12-7 An XSLT style sheet that transforms our XML document into HTML.
<?xml version='1.0'?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <HEAD> <TITLE>Henderson's Hotter-than-Hell Habanero Sauce</TITLE> </HEAD> <body> <H3>Henderson's Hotter-than-Hell Habanero Sauce</H3> Homegrown from stuff in my garden (you don't want to know exactly what). <H4>Ingredients</H4> <table border="2"> <tr BGCOLOR="#00FF00"> <TH>Qty</TH> <TH>Units</TH> <TH>Item</TH> </tr> <xsl:for-each select="Recipe/Ingredients/Ingredient"> <tr> <td><xsl:value-of select="Qty"/></td> <td><xsl:value-of select="Qty/@unit"/></td> <td><xsl:value-of select="Item"/></td> </tr> </xsl:for-each> </table> <P/> <H4>Instructions</H4> <OL> <xsl:for-each select="Recipe/Instructions"> <LI><xsl:value-of select="Step"/></LI> </xsl:for-each> </OL> </body> </html> </xsl:template> </xsl:stylesheet>
This style sheet does several interesting things. First, note the xsl:template match="/" element. As I've said, XSLT transformations occur by applying templates to specific parts of the XML document. The match attribute of this element specifies, via what's known as XML Path (XPath) syntax, to which part of the document the template should apply. In this case, it's the root element. So what the style sheet is saying is: Locate the root element of the document, and when you find it, insert the following text into the output document. What follows are several lines of standard HTML that set up the header of the Web page.
Note the xsl: prefix on the template element. It refers to the xsl namespace. The xsl namespace is where the template element and the other xsl: -prefixed names are defined. Adding the namespace reference makes the xsl: prefix available to the document so that it can reference those names. The URI reference is at the top of the style sheet. It has the form
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Next, notice the HTML table header info that's generated by the style sheet. It contains three sets of HTML <TH> tags that set up the column headers for the table. This section of the code matches that of the original HTML document we created earlier.
The most interesting part of the document is the looping it does. This is where the real power of XSLT lies. Notice the first xsl:for-each loop (in bold type). An XSLT for-each loop does exactly what it sounds like: It iterates through a collection of nodes at the same level in a document. The base node from which it works is identified by its select attribute. In this case, it's the Recipe/Ingredients/Ingredient node. As with the earlier match attribute, this is an XPath to the node we want to access. What this means is that we're going to loop through the ingredients for the recipe. For each one we find, we'll generate a new row in the table.
Note the way in which the nodes within each Ingredient are referenced. We use the xsl:value-of element to insert the value of each field in each ingredient as we come to it. To access the unit attribute of the Qty element, we use the XPath attribute syntax, /@name, where name is the attribute we want to access.
Note the paragraph tag <P/> that follows the looping code. Traditional HTML would permit this tag to be specified without a matching closing tag, but not XML. And this brings up an important point: When you provide HTML code for a style sheet to generate, it must be well formed . That is, it must comply with the rules that dictate whether an XML document is well formed. Remember: A style sheet is an XML document in every sense of the word. It must be well formed or it cannot be parsed.
The code finishes up with another for-each loop. This one lists the Steps in each Instructions element. Note use of the HTML Ordered List (<OL>) and List Item (<LI>) tags. These work just like they do in standard HTMLthey produce a numbered list.
You have several options for using this style sheet to transform the Reciple.xml document. You could use Microsoft's stand-alone XSLT transformer, you could use a third-party XSLT transformer, or you could use the one that's built into your browser, if your browser supports direct XSLT transformations. See the Tools section later in the chapter for more info, but, in my case, I'm using Internet Explorer's built-in XSLT transformer. This requires the addition of an <?xml-stylesheet> element to the XML document itself, just beneath the <?XML VERSION> tag. Here's the complete element:
<?xml-stylesheet type="text/xsl" href="recipe3.xsl"?>
As you can see, the element contains an href attribute that references the style sheet using a URI. Now, every time I view the XML document in Internet Explorer, the style sheet will automatically be applied to transform it. Here's the HTML code that's generated using the style sheet (Listing 12-8):
Listing 12-8 The HTML code generated by the transformation.
<html> <HEAD> <TITLE>Henderson's Hotter-than-Hell Habanero Sauce</TITLE> </HEAD> <body> <H3>Henderson's Hotter-than-Hell Habanero Sauce</H3> Homegrown from stuff in my garden (you don't want to know exactly what). <H4>Ingredients</H4> <table border="2"> <tr BGCOLOR="#00FF00"> <TH>Qty</TH> <TH>Units</TH> <TH>Item</TH> </tr> <tr> <td>6</td> <td>each</td> <td>Habanero peppers</td> </tr> <tr> <td>12</td> <td>each</td> <td>Cowhorn peppers</td> </tr> <tr> <td>12</td> <td>each</td> <td>Jalapeno peppers</td> </tr> <tr> <td></td> <td>dash</td> <td>Tequila</td> </tr> </table> <P /> <H4>Instructions</H4> <OL> <LI>Chop up peppers, removing their stems, then grind to a liquid.</LI> </OL> </body> </html>
And here's what it looks like when viewed from a browser (Figure 12-2):
Figure 12-2. The HTML document in a browser.
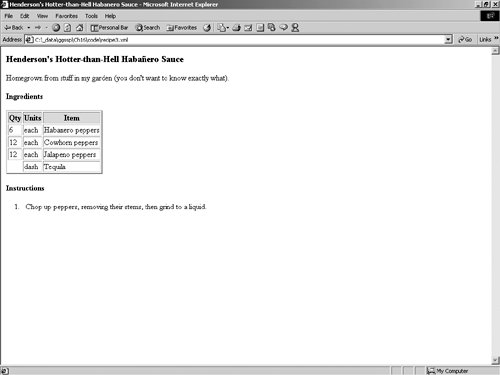
Although it's nifty to be able to translate the XML document into well-formed HTML that matches our original example, what does this really buy us? Wouldn't it have been easier just to have created the document using HTML in the first place?
Perhaps it would have been easier to have created this document in HTML without using XML and a style sheet. However, by separating the storage of the data from its presentation, we can radically alter its formatting without affecting the data. This is not true of HTML. To understand this, check out the style sheet in Listing 12-9:
Listing 12-9 A completely different transformation for the same XML document.
<?xml version='1.0'?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <HEAD> <TITLE>Henderson's Hotter-than-Hell Habanero Sauce</TITLE> </HEAD> <body> <H3>Henderson's Hotter-than-Hell Habanero Sauce</H3> Homegrown from stuff in my garden (you don't want to know exactly what). <H4>Ingredients</H4> <UL> <xsl:for-each select="Recipe/Ingredients/Ingredient"> <LI> <xsl:value-of select="Qty"/>	<xsl:value-of select="Qty/@unit"/> of <xsl:value- of select="Item"/> </LI> </xsl:for-each> </UL> <P/> <H4>Instructions</H4> <table border="2"> <tr BGCOLOR="#00FF00"> <TH>#</TH> <TH>Step</TH> </tr> <xsl:for-each select="Recipe/Instructions"> <tr> <td><xsl:value-of select="position()"/></td> <td><xsl:value-of select="Step"/></td> </tr> </xsl:for-each> </table> </body> </html> </xsl:template> </xsl:stylesheet>
We can use this style sheet to transform the XML document into a completely different HTML layout than the first one (you can specify a new style sheet for a document by changing the document's <?xml-stylesheet> element or by overriding it in your XSLT transformation tool). Figure 12-3 shows what the new Web page looks like in a browser:
Figure 12-3. The transformed document in a browser.
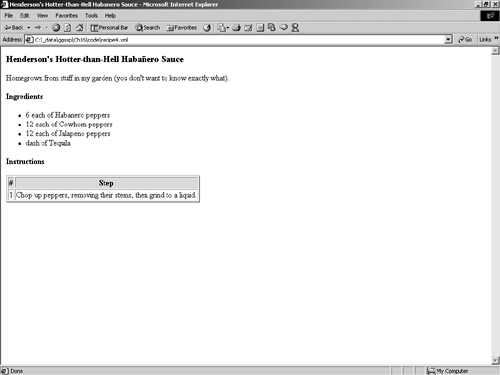
As you can see, the page formatting is completely different. The ingredients table is gone, replaced by a bulleted list. Conversely, the Instruction steps have been moved from an ordered list into a table. The formatting has changed completely, but the data is the same. The XML document didn't change at all.
Because the data now has context, we can access it directly. There's no need to hard code table column or table row references to the HTML and translate the data out of HTML into a usable data format. The data is already in such a format. And, regardless of how we decide to transform or format the data, this will always be true. Because it's stored in XML, the data can be manipulated in virtually any way we see fit.
The xsl:for-each element in our style sheets gave us a glimpse of some of XSLT's power. Like most languages, much of its utility can be found in its ability to perform a task repetitively. XSLT defines a number of constructs that are similarly powerful. Among them are
-
xsl:if
-
xsl:choose
-
xsl: sort
-
xsl:attribute
-
Embedded scripting. IBM's LotusXSL package provides most of the functionality of XSLT, including the ability to call embedded ECMAScript, the European standard JavaScript, from XSLT templates.
You can check the XSLT specification itself for the full list, but suffice it to say, XSLT brings to bear some of the real power and extensibility of XML. It's an example of what I like to refer to as the "programmable data" aspect of XML. Via XSLT, we have the ability not only to specify how data is formatted, but to programmatically change it from within the data itself. This is powerful stuff indeed.
Because we've been performing formatting- related tasks with XSLT and XML, it may appear that XML is just a content management technology. This is not the case. It's far more than that. Certainly, from the perspective of Webmasters, XML and XSLT offer huge advancements over HTML. However, XML is about more than just formatting data or managing content. It is about data, and giving that data sufficient context to be useful in a wide variety of situations. There's a whole world of applications outside the realm of browsers and Web pages. To add the power of XML to those types of applications, we can use something called the Document Object Model.
| for RuBoard |
EAN: N/A
Pages: 223