Understanding the Hash Function
The secure hash is an algorithm that takes a stream of data and creates a fixed-length digest from it. The digest is a fingerprint of the data. No message digest is perfect, but theoretically it should have a low collision rate, if any, and be a quick, secure algorithm that provides a unique fingerprint for every message. If even one single bit of data is changed in the message, the digest should change as well. Notice, however, that there is a very remote probability that two different arbitrary messages can have the same fingerprint. When two or more messages can have the same fingerprint, it is known as a collision . When the same exact message is hashed twice, it should generate the same digest. These are just some of the requirements that the hash function is based on and they should be the criteria for which hash algorithm to choose. The hash functions will generally fall into three types of algorithms based on their uses. There are hashes that don't require a key, those that require a secret key, and those that require a key pair. The algorithms that don't require a key are known as message digests. Those algorithms that require a secret key are known as message authentication codes, and those that require a key pair are known as digital signatures. All these algorithms and their differences are discussed in this chapter and the next two chapters. See Figure 9-1 for a breakdown of the algorithms. 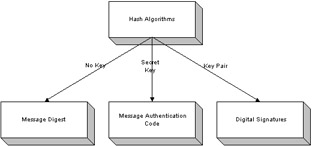 Figure 9-1: Different classifications of hash algorithms
Java Security Solutions ISBN: 0764549286
EAN: 2147483647 Year: 2001
Pages: 222 Authors: Rich Helton, Johennie Helton
flylib.com © 2008-2017. If you may any questions please contact us: flylib@qtcs.net |