Connection Pools
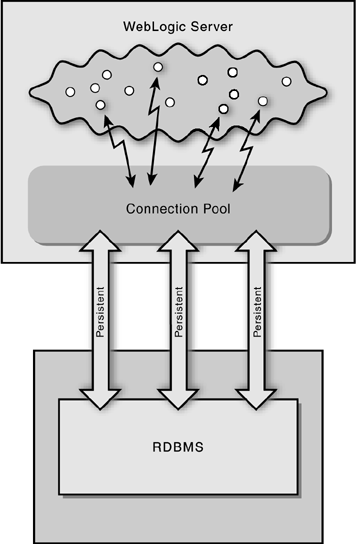
| When writing an application that interacts with a database, the obvious strategy from a programmer's viewpoint is to create and destroy connections on an as-needed basis. Closer inspection, however, reveals this strategy to be a wellspring of performance problems. Even if the application and the data source are located on the same physical machine, the handshaking between the database and the application that occurs is time consuming and expensive in terms of server resources. When, as is commonly the case, the database connection must be made across a network, the problem is compounded. Besides the fact that communication across a network is dramatically slower than communication among processes on a local machine, you must also take into account the overhead incurred in establishing a fresh network connection for each database transaction before you can even begin to address the database handshaking that I was whining about a couple of sentences ago. Clearly something had to be done. That something turns out to be connection pools. (See Figure 7-2.) A connection pool is a named collection of JDBC connections. Figure 7-2. Connection Pools Connection pools are another aspect of the J2EE application framework. They are based on the clever observation that, regardless of what any particular application is doing at any given time, the set of applications deployed on a server will usually be interacting with the database at about the same rate. Connection pools work by maintaining some number of open connections to a database at all times. The exact number is server specific and may in fact rise or fall depending on client demand. When a client process needs to interact with the database, it does not attempt to establish a network connection or go through the normal handshaking process; rather, it simply checks out an existing open connection from the connection pool. Similarly, when the client process is finished with the connection, it does not close it but instead returns it to the pool for reuse by some other client. Thus, the majority of the network and database connection overhead is neatly circumvented. For obvious reasons, all connections in a given connection pool must be to the same database. If you need to connect to more than one database, you can use MultiPools (see the discussion below). WebLogic also provides facilities for optimizing the delivery of results. Creating a Connection PoolTo create a new connection pool, click the Services folder, expand the JDBC folder, and then click Connection Pools. Click the "Create a new Connection Pool" link and fill out the fields as follows :
When you have filled out the values under the General tab, click the Create button to create your connection pool. Next, you need to specify the values that will be used in maintaining your connection pool. Under the Connections tab, fill out the following fields as appropriate:
|
EAN: 2147483647
Pages: 134