Important Variable ConceptsProperties, Scope, Type, and Namespace
| Variables in Integration Services function much like variables in structured programmingthey store values temporarily. However, in Integration Services, they are also objects, and therefore have properties and behaviors. This section drills down a little more on variable properties and behavior. Variable PropertiesFor an object that simply serves as a temporary storage location for other objects, the variable is a fairly complex thing. There are a few properties that you'd expect, such as Name, Value, and Type. However, there are others that might be a little unexpected, such as RaiseChangedEvent, EvaluateAsExpression, and QualifiedName. So, the following list takes a look at each of these properties and their purpose.
Variable ScopeVariable scope is a feature that provides a way to create variables in a location close to where packages use them. You build packages around a structure of containers and each container creates a pocket of functionality. This is good because it is generally easier to understand and manage packages built this way. For more on this, see Chapter 7, "Grouping Control Flow with Containers." In very simple terms, variable scope is about visibility and safety. If a variable is out of scope, it's not visible. This means that fewer objects have access to the variable, which means that there are fewer opportunities for the variable to be accidentally modified. In small packages, this isn't usually a problem. But the problem is magnified as packages grow more complex. Scoping variables allows you to better organize them and eliminates complexity. For example, if you define a lot of variables at the package level, they are all shown together in a cluttered view. It can be quite time consuming and frustrating to search through large lists of variables to find the one you want, especially when opening selection boxes in the component user interfaces. By scoping variables throughout the package in locations that are closest to where they are used, it is easier to find variables that apply to that part of a package without having to filter through all the unrelated variables. The following are the variable scoping rules in IS:
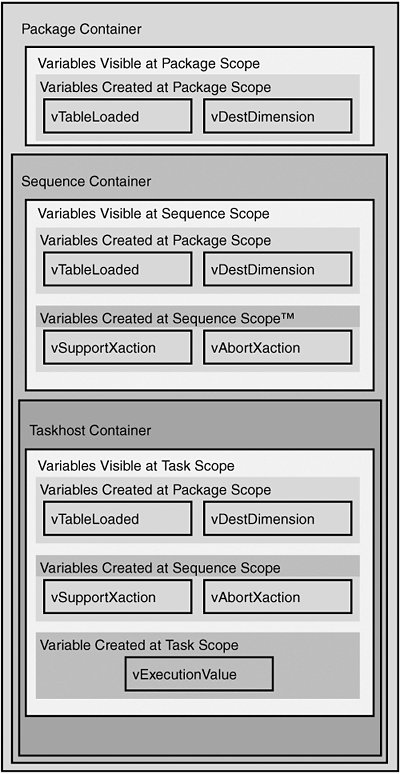
Variable InheritanceAs the simple conceptual model of variables in a package in Figure 12.1 shows, variables created at the package level are visible to the rest of the package. Variables created at the level of the task, on the Taskhost, are only visible to the task. Variables created on a parent container are visible to all its children. Notice that as you get closer to the tasks, the number of variables in scope increases if there are variables created on parent containers. Figure 12.1. Children containers inherit variables created on ancestors Variable HidingA side effect of variable scope is variable hiding, which is what happens when a variable is created with the same name as another variable at higher scope. This effectively hides the variable at higher scope from all containers at or below the level of the new variable. Generally, it's not a good idea to name variables the same. But there are rare times when it is useful. It is because of variable hiding that it is possible to hide parent package variables in child packages. If lower scope variables didn't hide higher scope variables, it would be possible to break a child package by adding a variable with a differently typed value but the same name at outer scope. It would be possible for a component to confuse the two and possibly retrieve the wrong one. Caution Although it is supported, there are very few good reasons for creating locally scoped variables with the same name as globally scoped ones. Unless you have a really good reason, you should avoid doing this. One of the situations in which it is useful to do this is discussed in the section "Parent Package Configurations." Sibling Container Variables Not in the Same ScopeThis is where variable scoping becomes quite powerful because this aspect of scoping is what allows the variables to be localized to subparts of the package where they are used. Figure 12.2 shows a simple conceptual model of a package with two tasks. Notice that there are four variables in the package. Two are found on the package and the other two in the tasks. Task1 has a variable created in its scope called vExecutionValue. Yet it's not visible to Task2. Likewise, vScriptSource, the variable defined in Task2's scope, is not visible to Task1. Figure 12.2. Variables on sibling containers are not in the same scope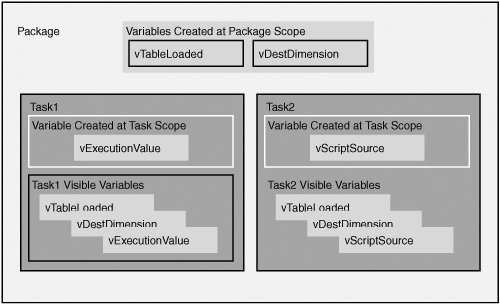 The Execute Package Task Scoping WrinkleWhen you create solutions, you'll ideally create packages that factor along certain functions, and then call out to those packages when you need their function so that you only implement the function once. This is smart package design because it eliminates duplicated effort and if there is an issue with the package, you only need to change it in one place. When you build packages this way, you'll occasionally need to pass information back to the parent package. Perhaps you want to pass back status on the child package or perhaps you use the child package to get information about the machine it's running on and you need a way to get that information back to the parent package. This is simple in IS because child packages follow the same variable scoping rules as containers. The interesting wrinkle here is that the Execute Package Task is considered the parent of the child package. So, because of the rule that variables visible on a parent container are visible to all its children, the variables visible to the Execute Package Task are visible to the child package it is configured to execute as well. Parent Package ConfigurationsYou might experience a problem when using variables from parent packages if you try to run the child package separately. The reason is because the child package attempts to reference the parent variable and it isn't available. You have at least two options for debugging packages that reference parent package variables:
Variable TypeVariables are capable of holding various types of values. The designer shows the available variable data types as managed data types. It's a little more complicated than that, however. IS variables are actually implemented as COM objects, and they are essentially COM VARIANTs. The designer exposes the available types as managed types. Also, the Data Flow Task uses a wider set of types to reflect the broader type set that SQL Server and other databases provide. Table 12.1 lists those types and how they map to one another. Variable NamespacesVariable namespaces have been the source of some confusion in the past. They shouldn't be. It's a very simple concept. Think of people names. In many cultures, there is the notion of a first and last name. In western cultures, the first name is how most people refer to a personit's the casual or "nickname." The last name is used to indicate family, clan, or other affiliation and is generally more formal. First names are commonly used in everyday interactions, but last names are important because they imply grouping and can have other important benefits such as familial association, might even imply some history, and give finer distinction to an individual. In eastern cultures, such as Japan, your family name is your first name and your familiar name is your last. But, the rule still holds true that people call you by your first name because Japanese are typically more formal than your average American and they still use their first names. The point is that few people struggle with first/last name issues even though they're much more complicated than variable namespaces in Integration Services. Variable namespaces are like last names for variables. They're used for grouping variables. Even if you live in Washington State, part of your family lives in Kansas, part in the UK, and part in the Carolinas, you're all part of a family. Namespaces are a way to identify variables as having something in common. Namespaces are also a way to distinguish variables from one another. There are many Kirks, Treys, and Rushabhs in the world. Well, there are a lot of people with those names anyway. Add a last name like Haselden, and you've got a pretty good chance that you've got an original name. Add some scoping, for example, all the Kirk Haseldens in Washington State or Trey Johnsons in Florida, and you've narrowed matters down substantially. Namespaces are sometimes confused for variable scoping as well. In the early days, the designer actually named variables with a namespace that was the name of the container. That was confusing because it made it appear that namespaces and scoping were related somehow. They're absolutely independent. Now the User default namespace is used to differentiate User-created variables from System-created variables. But, that's just the default namespace. You are free to use any namespace you want with the exception of the System namespace. Only IS can use this namespace for system-created variables. Nonqualified variable names are not guaranteed to be unique. So it is possible to create two variables with the same name if their namespaces are different. Variables with a namespace can still be accessed without appending the namespace. For example, suppose you create a variable called Samples::vADORecordSet. You can still use the nonqualified name vADORecordSet to access the variable, or you can use the qualified name Samples::vADORecordSet. Both are legal. However, especially in organizations in which more than one individual builds packages, it is safer to use the qualified name. If someone else modifies the package or subpackage and adds a variable by the same name, it's possible that they will introduce bugs or otherwise break the package because there is no guaranteed order of retrieval for variables. Using the qualified name, you will ensure that you always get the variable you ask for. These are a few cases in which namespaces are useful. Most of them boil down to protecting or creating a pocket in which any name can be used without concern for conflicting with other variable names. One case in which namespaces could be used is for wizards. Imagine you've come up with an idea for a wizard that will build a bit of workflow or data flow and insert it into an existing package. Part of the wizard requirements are that it creates variables for the components to use. If there were no namespaces, you'd have to concern yourself with how to name the variables so that they don't conflict with variables that already exist in the package. With namespaces, you don't need to worry. Simply use a namespace that is related to your wizard, something such as your company name or the wizard name like CommonPatternWizard or AcmeCompany. Any variable you create will now be unique throughout the package. As an observant reader, you'll note that it's possible to pick a namespace that is already being used in the package. But, the probability of conflicts is drastically reduced. Another way to use namespaces to your advantage is to quickly find all the variables within the namespace. The designer allows you to sort the variables by clicking on the column heading. If your package is complex with many variables spread throughout, you can click on the Show All Variables in the Package button and then click on the Namespace column heading to quickly yield a list of all the variables in a given namespace. Tip The Namespace column of the Variables window is not visible by default. Click the upper-right button in the Variables window to open the Choose Variable Columns dialog box and select the Namespace option. |
EAN: 2147483647
Pages: 200