Output Streams, Writers, and Encodings
| Most of the time you don't want to dump an XML document to System.out . Instead you want to write it in a file or onto a network socket. You might even store it in a string and pass it to some other process. What connects all of these possible targets in Java is the java.io.OutputStream class. Files, sockets, and even strings can all be treated as just another kind of stream. XML documents are text, and that text is made up of Unicode characters. When the Unicode characters are actually written onto a stream, you need to pick a character encoding that specifies how each character is converted into bytes. This encoding can be one of the Unicode encodings such as UTF-8 or UTF-16, or it can be a local code page such as ISO-8859-1 or MacRoman. Characters that don't exist in the local code page can be escaped using numeric character references. The encoding declaration will be set to indicate the character set in use. The normal way that Java converts characters into bytes in a specific encoding is by chaining an OutputStreamWriter to an OutputStream . As chars and strings are written onto the OutputStreamWriter , they are converted to bytes in the specified encoding, which are then written onto the underlying OutputStream . Let's suppose you want to dump the Fibonacci numbers into a file called fibonacci.xml in the current working directory. First you would open a FileOutputStream to that file, like this: OutputStream fout = new FileOutputStream("fibonacci.xml"); If performance is at all a concern, you would immediately chain this FileOutputStream to a BufferedOutputStream like this: OutputStream bout = new BufferedOutputStream(fout); Then you would chain the BufferedOutputStream to an OutputStreamWriter . You'd pass the Java name of the encoding you want as the second argument to the OutputStreamWriter() constructor. For example, the following line chooses the ISO-8859-1, Latin-1 encoding, although it uses Java's name for this encoding, "8859_1": OutputStreamWriter out = new OutputStreamWriter(bout, "8859_1"); Finally, you would write the output onto that OutputStreamWriter , making sure to include the right encoding declaration using the XML name for the encoding. Example 3.9 demonstrates . Example 3.9 A Java Program That Writes an XML File import java.math.BigInteger; import java.io.*; public class FibonacciFile { public static void main(String[] args) { BigInteger low = BigInteger.ONE; BigInteger high = BigInteger.ONE; try { OutputStream fout= new FileOutputStream("fibonacci.xml"); OutputStream bout= new BufferedOutputStream(fout); OutputStreamWriter out = new OutputStreamWriter(bout, "8859_1"); out.write("<?xml version=\"1.0\" "); out.write("encoding=\"ISO-8859-1\"?>\r\n"); out.write("<Fibonacci_Numbers>\r\n"); for (int i = 1; i <= 10; i++) { out.write(" <fibonacci index=\"" + i + "\">"); out.write(low.toString()); out.write("</fibonacci>\r\n"); BigInteger temp = high; high = high.add(low); low = temp; } out.write("</Fibonacci_Numbers>\r\n"); out.flush(); // Don't forget to flush! out.close(); } catch (UnsupportedEncodingException e) { System.out.println( "This VM does not support the Latin-1 character set." ); } catch (IOException e) { System.out.println(e.getMessage()); } } } One change from the System.out version is that the line breaks have to be encoded explicitly. Although they aren't really necessary for this XML document, the examples are prettier if the XML doesn't consist of one long line of text. I recommend using a carriage -return/ linefeed pair ( \r\n ) as your line break. This is the native format for DOS and Windows, and most Unix and Macintosh text editors can handle it. More important, it is the standard line ending for network protocols such as HTTP and SMTP. XML parsers do normalize all line breaks to a single linefeed on input, so the proper choice of line break for an XML document is not nearly as fraught as for some other types of files. Nonetheless, picking carriage-return/linefeed does help when processing or transmitting XML documents with non-XML-aware tools. Although most XML parsers written in Java support exactly those encodings that are available in Java, they don't use the same names. Java tends to use underscores whereas XML tends to use hyphens in encoding names, or to eliminate the hyphens completely. The reason is that earlier Java virtual machines used reflection to locate the classes that convert between different encodings, so its encoding names needed to be legal Java class names. Table 3.1 lists the Java and XML equivalents of the standard character sets and encodings. Later versions of Java, especially Java 1.4, often allow multiple names for the same encoding. Here I've picked the names that are supported across the broadest range of virtual machines. In Table 3.1, I have deliberately omitted XML legal encodings that are not yet supported by Java, such as ISO-8859-10, ISO-8859-11, ISO-8859-14, and ISO-8859-16. It's not hard to add them in Java 1.4; but because they're not available by default, you're better off picking UTF-8 or one of the other Unicode encodings. The exact list of encodings Java supports varies from virtual machine to virtual machine and from version to version. Java 1.4 is a major leap forward in support for many character sets, as well as for different aliases for character set names. However, since the standard Unicode and ISO encodings enable you to handle most environments today, there's little reason to use other encodings in XML documents. Table 3.1. Standard Character Sets and Encodings
Some parsers, including Xerces-J, have an option to recognize the Java names, and all of the other encodings Java supports. This can be useful when you're reading XML documents that other people and systems send to you. However, you should not generate documents that use these encodings. The standard encodings in Table 3.1 should be sufficient for any document you need to create, and they are a lot more cross-platform compatible than platform-specific code pages such as Cp1252 and MacRoman. In a few cases you might prefer to use standard non-Unicode, non-ISO national character sets such as KS C 5601 for Korean or KOI8-R for Cyrillic. These are okay too, but still a little less well recognized around the world than the standard encodings listed in Table 3.1. The general principle is to be conservative in what you generate, but liberal in what you accept. In other words, try to stick to the most standard encodings when writing documents, but accept any encoding you recognize when reading documents. Other character sets that you should not use in XML but which are available in Java include UTF-16BE and UTF16-LE. These are big-endian and little-endian encodings of Unicode without an explicit byte order mark. XML documents in UTF-16 must have an explicit byte order mark; it may not be omitted. UTF-8 documents may have a byte order mark; but in general should not for maximum compatibility with other software. Note Output streams, output stream writers, files, Unicode, character sets, and character encodings, and many other aspects of input and output in Java are covered in much more detail in another of my books: Java I/O . O'Reilly & Associates, 1999. ISBN 1-56592-485-1. |
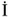 ,
, 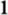 ,
,  ,
, 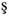 ,
, 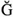 , and
, and 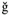 take the place of the Icelandic letters ,
take the place of the Icelandic letters , 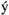 ,
, 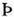 ,
, 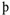 ,
, 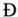 , and
, and 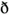
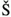 ,
,  ,
, 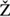 ,
,  , ’, “, and
, ’, “, and  .
. EAN: 2147483647
Pages: 191