Enterprise Architecture
|
| < Free Open Study > |
|
Today the architecture and infrastructure of an enterprise-scale application can be extremely diverse. An enterprise can consist of legacy mainframes from the 1960's coupled with modern systems. Over the past decade legacy and modern systems have been integrated using networks and the Internet.
Businesses retain their legacy systems because the economic cost of transferring their core business practices to a modern system is prohibitive. However, the consequence of maintaining legacy systems, introducing new systems, and merging them with systems from other organizations is that the architectural landscape of the enterprise is complicated.
Consider a financial services company that has existed for 30 years. Thirty years ago, it defined its core business processes on a mainframe system in COBOL. Over the years the company was involved in several acquisitions and mergers, and the business processes of these other companies were integrated with the system. These businesses developed applications using the best technology available at the time. The result is that today the company has a complex architecture that links many diverse hardware and software systems. Of course, these systems not only have to link up internally, but also externally via the Web.
The distributed environment of the Web allows employees working at a PC in their office to interact with any other connected system or resource, both within and outside the business. External systems (for example, those of suppliers) can be included in the network and hence communicate with the enterprise employees and systems through the Web. The problem is then to establish a common language or protocol to enable these systems to communicate.
Networks and Protocols
In developing for distributed computing systems, the underlying physical connections are the foundations upon which the system is built. Take away the network and your distributed applications will lose most of their usefulness. Often the basic network structure is transparent to the developer. Java's "write once, run anywhere" philosophy has led to the development of a strong arsenal of network-related API that makes development of distributed applications easier, making a basic understanding of the topology of the network over which we develop important. As we begin to work with servlets in a distributed environment, we start by looking briefly at the physical connections made between computers and how our systems are linked.
In a network, all linked systems are connected - whether by physical or wireless network. The network serves as a link for communication between computer systems and the software that runs on them. Three basic network topologies are shown in the following diagram:
-
The star topology is used to connect computers to a central point, often known as a hub
-
The ring topology connects computers in a closed loop where each computer connects to the next, until the loop is closed
-
The bus topology connects to a single shared medium over which systems communicate
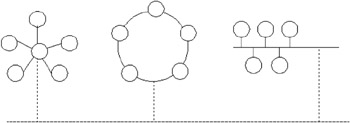
Of course these are not the only topologies used to implement a network. The topologies shown are used mainly in local area networks (LANs). They are the most common structures, with most of the alternative topologies being a derivative or combination of these. As new networking and communication technologies evolve, such as Bluetooth, the topology of the enterprise network tends to become more complex. The demands on the network (and network administrators) to support an ever-increasing range of technologies are a constant challenge.
Networks are designed to act as communication channels, allowing diverse and otherwise incompatible systems to connect to the same network and communicate. We are all aware of how our networks can include different operating systems and different devices in the same network. We can, using a browser communicate with a server that may run on a completely different operating system to that on which the browser is running. So, the question is, how do incompatible systems communicate?
Any resource can join the network, so long as it can communicate using the protocol(s) agreed for the network.
A protocol is a set of rules agreed for communication. A number of protocols have been developed to specify common standards and message formats, so that different systems can exchange information and data. These protocols were designed to provide specific services and are layered to provide a (relatively) reliable networking service.
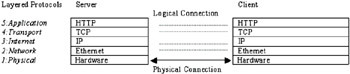
At the physical level, the hardware physical connection takes place between the communicating computers. This essentially comprises the network cards and the wired (or wireless) connection between the systems. This allows the computers to communicate by providing a medium over which messages can travel.
At the network layer, the network implements a protocol such as the Ethernet to facilitate communication between the computers. This deals with how data should be broken into frames and sent across the network. It also defines items like the size of data to be sent, the format for breaking up and reassembling large messages, and how to deal with network problems.
Messages sent from one system are wrapped up in the layered protocols and then sent across to the another system via the network. The system that receives the message unwraps the message from within the layers of protocol. Logically, each equivalent layer is communicating with its corresponding level on the other computer. Each of these layers are, at the most basic level, providing a bridge between the systems, and the protocol layers above them provide additional services.
It is a little like a more reliable version of translation where the top levels communicate in the home language, but the message must be translated into a series of intermediate languages or codes before it can be exchanged. The receiver then sends the message back through a defined series of translators or decoders, until the message has been translated into the home language again.
TCP/IP
The Transmission Control Protocol (TCP) and the Internet Protocol (IP) layers are commonly grouped together because the two protocols provide complementary services. The TCP/IP protocols are by no means the only protocols that can be used for these layers, but they have, as the Web has developed, become the standard protocols for communication over the Web.
The Internet Protocol defines how pieces of data (known as packets) are formatted, as well as a mechanism for routing the packet to its destination. This protocol uses IP addresses of connected computers in the routing of data across the network. This is a relatively unreliable protocol, as data can be lost or arrive out of sequence. The Transmission Control Protocol provides the application layer with a connection-oriented communication service. This layer provides the reliability that the underlying IP layer lacks, by ensuring that all packets of data are received (and resent if necessary) and are reassembled in the correct order.
Together the TCP/IP protocols provide a reliable service, with the layers dividing the responsibilities between them to provide the reliable connections that the overlying application layer requires.
HTTP
The application layer of the communication is most frequently provided by the HTTP or Hypertext Transfer Protocol. Other protocols are in use also, such as the e-mail protocols POP3, SMTP, and IMAP, as well as the File Transfer Protocol (FTP), but HTTP is by far most prevalent within web applications. Web containers and J2EE applications are required to support HTTP as a protocol for requests and responses. As this is the most common top-level protocol of the web, by using this protocol applications can communicate with most servers with confidence that the message will be understood.
HTTP provides a defined format for sending and receiving requests, and acts as a common language that applications and systems developed on different systems and in different languages can all understand.
Why Not Use Remote Procedure Calls?
Remote Procedure Calls (RPC) is a mechanism by which a client can make specific requests to a program on a server (passing variables as required). The server then returns a result to the client that made the request. The client that makes a call must follow a predefined format.
In Java, RPC is implemented in Remote Method Invocation (RMI), by which Java applications can invoke methods of a class on a remote server according to the process defined for RMI method calls. This is done with the use of interfaces that define the remote object whose methods we want to call. The request is then made on the remote object, with the help of the interface, as if it was a local object. Java uses vendor-provided custom protocol implementations to convey the request. Sun uses the Java Remote Method Protocol over TCP/IP. Alternatively, RMI method invocation may be carried over the IIOP (Internet Inter-Orb Protocol) between Java applications (RMI-IIOP), which is language independent, allowing interaction using a remote interface with any compliant object request broker (ORB).
CORBA (Common Object Broker Request Architecture) provides a language-independent mechanism for invoking methods or procedures on a remote application.
RMI and CORBA are more complex to implement than HTTP, making them inappropriate for many web applications. HTTP is the protocol of choice in the distributed environment, and for the majority of web-based applications (with all types of clients) is the pre-eminent choice, giving the best reliability and flexibility. It is therefore the most supported.
Both HTTP and RPC dictate that both client and server understand the common request-response process. However, if you update classes involved in RPC type requests, you frequently have to update both the client and server classes, even if the change only affected one side. With HTTP, so long as the format of requests is agreed, the server updates do not need any modification on the client (and vice versa).
HTTP is the standard language of the web, used and understood by more servers and clients. This makes it the ideal protocol to use for most web and servlet development.
Tiered Architectures
The old model of two-tiered client-server development, where the client application connected directly with the data source, has been largely superceded. Enterprise applications are becoming more prevalently multi-tiered applications, spanning three or more tiers. The separation and consolidation of logical parts of the application into many different tiers has a couple of key benefits:
-
By modularizing functions into specific tiers, we encapsulate related rules and functionality together, enabling easier maintenance and development
-
Modularization also enhances the flexibility and reusability of business, presentation, or other logic in component based development
-
Developers with particular skills can focus on the logic specific to a particular tier (for instance database specialists can focus on the database tier), while the contract between tiers defines the relationships between tiers, and what services they can expect from the other tiers
Here's what a three-tiered architecture often looks like:
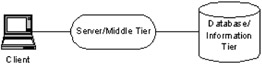
The client tier is where the data and information is described or displayed to the user.
The server or middle tier responds to client requests for data and/or actions. This is where the core application logic is usually held. However, the middle tier is frequently separated into two distinct tiers:
-
The business tier is responsible for holding the business processing logic. It is concerned with implementing the business rules for the application faithfully.
-
The web tier (or presentation tier) is reserved for presenting or wrapping the business data for the client. It responds to the client requests and forwards them to the business tier where the business logic is applied to the processing of the request.
The business tier will return the outcome of the request (data or other response) and the web tier will prepare the response for the client.

In this book we will focus on servlet development within web applications, which resides firmly in the web tier of the model.
Finally, the database/enterprise information of the application is the where the data or information resides. This is often described as the database layer, but equally can comprise of a legacy information system, or indeed any other information system, including another server application. There may be many such systems in this layer providing data or services to the middle tier, either directly or indirectly.
The J2EE Platform
A number of services are often required by applications, specifically those in the middle tier. These services, such as security, database connections, and so on, are standard across many web applications, so providing them individually for each web application would significantly hinder development. We would like the server in the middle tier to make some (or all) of these services available to applications running on it, so that the application developer does not need to include code in each application to do so instead. In this case server vendors provide the API libraries to support the services and the means for accessing them.
In Java terms, we have a developer-friendly situation where the provision of the services and APIs that support them have been standardized across compliant Java servers. This means that we can start application development on one standards-compliant server, and then deploy the application on another compliant server from a different vendor with little difficulty.
This is where the Java 2 Platform, Enterprise Edition comes into the picture. This is not a server, but a set of specifications for technologies, services, and architecture that a J2EE-compliant server must provide. From a programmer's point of view this allows us to focus on developing the application rather than having to learn about how it interacts with the server. Different vendors do provide additional services and tools on their servers, but having a standard framework allows the flexibility to deploy across different vendor servers, assuming that we use the standard services and APIs provided for by the J2EE specifications.
Servlets are an integral part of J2EE. They sit on the web tier responding to, and processing, client requests. They provide the client tier with a standard gateway to the information available from the business or database/enterprise information tier. They can service many types of clients in a standard request-response cycle over any suitable protocol (such as HTTP).
Servlets are responsible in the J2EE model for providing dynamic content to the client. This means that they are the bridge between the client and the web application, and their main service is to exchange and transfer data with the client in the standard request response structure. As part of this process they receive client requests, usually with some additional information (for example request parameters). Then they process this information, communicating with other sources required to process the data, such as databases, or other information sources. Finally they return a response to the client.
|
| < Free Open Study > |
|
EAN: 2147483647
Pages: 130