The Universal DBMS
The Universal DBMS
Database Management Systems began life as tools to store, index, and access large numbers of relatively short and simply structured records. Hierarchical, network, and other data organization schemes were used by mainframe databases in the 1970s. In the 1980s, relational database management systems (RDBMS) became popular on midrange and even workstation class systems. RDBMS systems were optimized for relatively small records with simple field types such as integers or characters . In part, this was a performance and capacity issue. Large multimedia data types, such as images or video, were less common and typically only managed with customized hardware and software. Production use of object-oriented software was still uncommon and therefore there was little need for huge object-oriented database systems. Today, in large part because of the explosive growth of the web, multimedia data is common and new languages such as Java have greatly simplified object-oriented programming. As a result, the leading RDBMS vendors have re-architected their database products to provide universal DBMS capabilities designed to handle any data type effectively.
Multimedia data, such as video or even large images, are a good example of a data type that was not handled well by earlier RDBMS systems. While most RDBMS systems could store an image or even a video clip as a binary large object (BLOB), that was all they could do. They did not provide any operators to index or search BLOB data types. In addition, maximum RDBMS record sizes often were not sufficient for storing larger images or video clips. RDBMS performance, with I/O optimized for smaller records, did not store multimedia data types well even when maximum record sizes were not an issue. Large image data and video data was thus traditionally stored in regular flat data files, with the RDBMS being used, if at all, only to store ancillary information, or metadata, about the images.
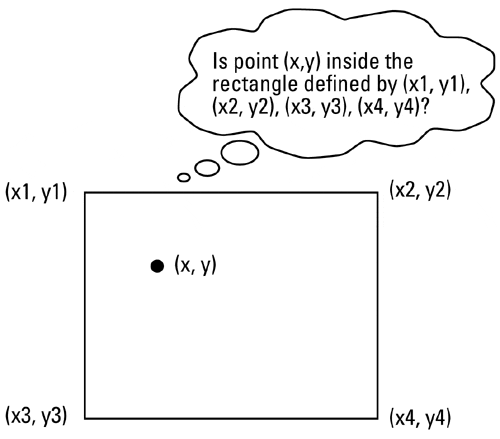
Another example of a specialized data type not handled well by traditional RDBMS systems is geographically encoded data with latitude-longitude pairs. In this case, while a RDBMS can easily store latitude-longitude pairs in a record, many do not provide any effective method to spacially index or search on such data types. For instance, consider a RDBMS table storing rectangular area data defined by four latitude-longitude pairs. To answer a user query of the type, "is the point (x, y) inside the rectangular area defined by (x1, y1), (x2, y2), (x3, y3), (x4, y4)?" would be very time-consuming with a pure RDBMS. As shown in Figure 4-1, this is a very simple problem to solve visually. Since this type of data is not relational, however, the RDBMS would have to do a sequential search through each record in the table searching for a record where
Figure 4-1. Spacial Data Record Query
-
x1 < x < x4
-
y1 < y < y4
This type of search is a very time consuming computational problem for a traditional database to solve. In part because of limitations like these, geographic information system (GIS) vendors typically implemented their own data storage programs for spacial data, using non-relational indexing and search mechanisms such as R-Tree representations.
DBMS vendors have taken three approaches to developing universal DBMS systems:
-
adding "bolt-on" data types and operators to an existing RDBMS;
-
integrating new data types and operators into the kernel of an existing RDBMS; or
-
adding more traditional RDBMS data types and operators into an object-oriented DBMS. For each new data type, a DBMS must also implement storage, indexing, and searching functions. Each approach has its own pros and cons.
Implementing new data types and operators via "bolt-on" software has the advantage of being easier to implement as the new functionality can often be implemented with very little knowledge of or impact to the DBMS kernel. This method of implementing new data types has been called both "Data Blades" and "Data Cartridges" by RDBMS vendors. In addition, if RDBMS vendors publish the interface they are using for bolting-on new data types, third parties may develop their own bolt-on data types leading to more choices and functionality for the software developer. One of the disadvantages to this approach is that since the bolt-ons typically modify key RDBMS kernel data structures, possible corruption in a bolt-on may lead to corruption or malfunctioning of the RDBMS. It is thus imperative to test each piece of bolt-on software as carefully and thoroughly as the kernel itself is tested . This however, becomes difficult to do as the bolt-on code base grows in size or starts being implemented by third parties other than the RDBMS vendor.
The second method, integrating new data types and operators into the RDBMS kernel, is often more difficult and time consuming to implement, mainly because it can involve significant changes to the core kernel of the RDBMS. Each change to the kernel must be carefully architected and designed so as to not increase functionality and performance in one area at the detriment of another. By their very nature, such modifications can only be completed by the RDBMS vendor who thus controls the availability of each new data type, versus leaving the process open to third party implementations . On the positive side, quality and performance of the RDBMS can be more tightly controlled using this type of approach. In practice, many RDBMS vendors have taken the approach of providing new data types via some combination of these first two approaches.
The third way to develop a universal database is to start with an object-oriented DBMS (OODBMS) and add relational data types and operators. In theory, this is much easier to do than visa-versa. However, in practice, the RDBMS vendors have a long history of providing the scalability and performance required by the mainstream DBMS marketplace . OODBMS vendors may be able to provide similar functionality, but not performance against relational data types. For the most part, therefore, usage of OODBMS systems has stayed confined to relatively niche, low volume applications.
EAN: 2147483647
Pages: 193