XML: Meta-Language for Data-Oriented Interchange
| < Day Day Up > |
XML: Meta-Language for Data-Oriented InterchangeThe eXtensible Markup Language (XML) provides a standard text-based language that all applications can understand. XML is completely platform neutral, is a universal data format, and is self-describing . These points will become extremely critical to our Web services security discussions. XML's text-based nature does make messages much bulkier, but no special middleware is needed to process them. Security is much easier to monitor with text-based messages than with proprietary binary formats. This point is critical because security requires monitoring to provide assurance it is working as well as an audit trail for later discovery and defense in case of challenge or incident. XML is the heart and soul of Web services. SOAP and WSDL are described using XML. The core security standards of XML Encryption and XML Signature are also XML-based. Where XML Came From and Why It's ImportantXML is essential to the world of structured data. It was developed to overcome the limitations of the Hypertext Markup Language (HTML), which is good at describing how things should be displayed but is poor at describing what the data means that is being displayed. XML is already the most widely accepted data interchange format ever devised. The granddaddy of markup languages is the Standard Generalized Markup Language (SGML). Its goal was to separate content from presentation. However, SGML was too large and too complex to describe Web documents. It had so many optional features that confounded simple sender-receiver agreements critical to the Web's early vision. So, HTML was the quick and dirty approach used to get the Web going with its rich text and graphics pages linked together using hypertext. HTML succeeded in achieving its goals. It is a simple, human-readable format that uses one set of tags for all documents, and it is completely focused on documents. However, a fixed set of tags cannot describe data. Catalogs need a <PRICE> tag; repair manuals need a <PARTNUM> tag; drugs need <ALLERGEN> and <SIDE-EFFECT> tags. If you could apply these tags, this data description would suddenly become searchable. A non-extensible format could not add new tags and tell people (or machines) what they meant . No one except the browser manufacturers was able to add tags to HTML. In contrast, with XML, companies, consortia, standards bodies, and others can define their own document types with their own unique metadata. HTML allows for little reuse. With XML, Document Type Definitions (DTDs) ”now rapidly being replaced by XML Schema ”allow communities to agree on schemas for types of data. This has been done in chemistry , music, math, insurance, pharmaceuticals , and hundreds of other industries. Individual companies even create schemas for internal use within their companies, as Merrill Lynch has done with its own X4ML. XML addresses the engineering complexity of SGML and the fixed tag set of HTML. XML documents are completely legal SGML documents. XML is not an application of SGML, but it is a true subset of it. The most powerful attribute of SGML is the most powerful attribute of XML as well: It is extensible. Don't be fooled into thinking XML is not mature. The XML subset of SGML has already been in use for 15 years . XML is technically a meta-language. It is used to define other languages. If you tell a computer about your language for insurance forms, software on that computer can parse the XML and extract the customer name and coverage amount correctly. Two different computers running different applications built in different languages by different teams can read the same XML, and both unambiguously have the same information content. This was not possible in HTML or any other format used to communicate between different applications or different organizations. XML and Web ServicesData destined for a Web service can either be created in XML or converted into XML from its native format. This data may be taken from tables in a relational database or processed by a programming language such as Java or C# and then transformed into XML. XML stores data within descriptive element tags like this: <PartNo>54-2345</PartNo> Here, <PartNo> is the descriptive element tag, and 54-2345 is the data it describes. XML tags are enclosed within angle brackets ( < > ) and have a start and an end. The end tag is marked by a leading slash ( / ). Elements can have one or more attributes using name/value pairs: <Price Currency="USD">59.95</Price> <TransportCode Type="Air" Carrier="United">452</TransportCode> XML's tag structure is hierarchical. One tag may contain any number of tags within it as demonstrated in Listing 2.2. Listing 2.2. XML's Hierarchical Tag Structure for a <ShipOrder> Construct<?xml version="1.0"?> <shipOrder> <shipTo> <name>Tove Svendson</name> <street>Ragnhildvei 2</street> <address>4000 Stavanger</address> <country>Norway</country> </shipTo> <items> <item> <title>Empire Burlesque</title> <quantity>1</quantity> <price>10.90</price> </item> <item> <title>Hide your heart</title> <quantity>1</quantity> <price>9.90</price> </item> </items> </shipOrder> XML NamespacesTo protect names in one XML document from being confused with the names in another document, XML namespaces provide a mechanism to keep these names separate and distinct. A namespace operates much the same way a package construct in C++ or Java keeps the names of local data or methods from colliding with names in other classes. Namespaces allow you to create your own element and attribute names without colliding with other element and attribute names that you might need to use in an xml instance. In other words, you could define a CustomerNumber element and so could a supplier that you are working with, and using namespaces have no collision when these two elements are used in the same XML document. Namespaces are often long and are abbreviated using a namespace prefix. Remember that a namespace prefix is just a shortcut to abbreviate a namespace within the context of a namespace declaration (the special xmlns attribute) so even though you will see common prefixes, such as wsee for the Web Services schema, these prefixes could really be anything as long as they are associated with the correct namespace. Namespaces are critical in Web services because even if documents from different organizations are not being processed ”where name collisions are common ”a single Web service employs at least four related documents: the instance document carrying the data, the SOAP envelope defining the message format, the WSDL instance document describing the interface, and the WSDL schema validating the interface definition. This is the minimum number of documents involved with a Web services conversation; others are added depending on the service. Namespaces are uniform resource identifiers (URI) that look like this: xmlns:myns="http://www.myorg.com/namespace/XML" This name is prepended to elements in the XML document in which it resides. Technically, what you want is just a uniform resource name ( URN ) . A URN is just a name and does not point to anything and cannot be dereferenced. The only reason to use a URI as opposed to a URN is that the URI is a name with a DNS-registered hostname embedded in it that is guaranteed to be unique across the entire global Internet; therefore, it creates a unique prefix (that is, it's easier and more secure).
XML SchemaSGML includes a means of defining which particular elements and attributes are used to define meaning in an XML document. These are called Document Type Definitions. Confusingly, DTDs are specified in a different language than SGML itself. DTDs have other limitations as well. Until recently, XML also used DTDs to define the tags and their meanings used in documents. XML Schemas provide an alternative to DTDs to address these limitations. XML Schemas are created to define and validate an XML document. They are specified in XML itself. Schemas describe data types and specify any required ordering of elements. If a need is found for additional types, a schema can be changed independently of the data. It is common practice that the xsd namespace prefix identifies an element as part of an XML Schema, as shown in Listing 2.3. Listing 2.3. An XML Schema for ShipOrder<xsd:schema xmlns:xsd="http://www.w3.org/1999/XMLSchema"> <xsd:element name="shipOrder" type="order"/> <xsd:complexType name="order"> <xsd:element name="shipTo" type="shipAddress"/> <xsd:element name="items" type="cdItems"/> </xsd:complexType> <xsd:complexType name="shipAddress"> <xsd:element name="name" type="xsd:string"/> <xsd:element name="street" type="xsd:string"/> <xsd:element name="address" type="xsd:string"/> <xsd:element name="country" type="xsd:string"/> </xsd:complexType> <xsd:complexType name="cdItems"> <xsd:element name="item" type="cdItem"/> </xsd:complexType> <xsd:complexType name="cdItem"> <xsd:element name="title" type="xsd:string"/> <xsd:element name="quantity" type="xsd:positiveInteger"/> <xsd:element name="price" type="xsd:decimal"/> </xsd:complexType> </xsd:schema> XML Schemas are critical for the automatic validation of XML instance documents, which are documents that purport to be valid instances of an XML document that conforms to a specified XML Schema or definition. Simple types in XML Schemas are string , integer , double , float , date , and time . A type is specified as part of the element definition: <xsd:element name="CustomerNumber" type="xsd:integer"/> XML processors validate instance documents by processing the schema along with the document, matching elements in the document to the corresponding element definition in the schema, and checking the type specified to ensure a match. Complex types can be modeled as well using a special ComplexTypes construct. XML Schemas are an important innovation for XML security. XML Schemas are more complex than DTDs, but they also provide for much tighter constraints on the XML document being defined. This is good when you're defining XML security because accuracy and consistency are essential. XML Schemas are critical tools for precisely defining Web Services Security technologies such as XML Signature, XML Encryption, and WS-Security. XML TransformationsXML Transformations are the reason we say Web services are a loosely coupled form of middleware. Traditional middleware created tightly coupled and, therefore, brittle connections. This was true of DCE, RMI, CORBA, and DCOM. Changes made in any part of the system had to ripple through the entire system in harmony, or the whole system stopped working. With XML transformations, one part of the Web services system can be changed and made to perform necessary XML transformations dynamically at runtime to remain compatible with the as-yet-unchanged parts of the system. The incredible power of XML over other data representations is that it is a data representation that all applications can understand: You can define and validate new document structures, and you can transform documents in transit. This is one reason why we say that XML is the "secret sauce" that makes Web services such a radically new and powerful form of middleware. As you will see, XML transformations are an important part of XML security and therefore of Web Services Security. At the very least, you will be required to transform XML documents to completely consistent canonical forms before applying XML Signatures. First, though, let's explore four particularly important XML transformations that you will need to understand for later discussions. The four transformations described in the following sections are XPath, XSLT, XQuery, and XMLBeans. XPathThe primary purpose of XPath is to refer to parts of an XML document. This transformation is called XPath because, at its simplest, it is a way to refer to part of an XML document in a similar manner to a file system path. For example, you can refer to the root node of an XML document by using the XPath expression / . You could refer to an XML node foo below the current node by using this XPath expression: ./foo . This is the basic idea of XPath. Like everything in XML, it seems to go from simple to complex reasonably quickly. We will not describe XPath in depth here, but we encourage you to become familiar with XPath for several reasons. First, when it is used in XML Signature, you must understand XPath to understand what is being signed. Second, it is used in many other specifications, such as XSLT, Xpointer, XML Encryption, and more. We highly recommend the XPath tutorial at ZVON: http://www.zvon.org/xxl/XPathTutorial/General/examples.html The tutorial not only takes you through the XPath syntax, but it also has an interactive lab where you can try different XPath statements. XSLTXSLT, which stands for Extensible Stylesheet Language Transformations, transforms an XML document into a different structure. A style sheet provides instructions on how to modify or restructure a document. In this way, you can change the names of element tags, reorder sequence, add and remove elements, and so on. A typical scenario for XSLT might be to receive a purchase order and transform it to match the required internal structure. This means less error processing is required downstream. Another use is to merge multiple documents into one. Frequently, XSLT is used to perform outbound transformations from internal (or archaic) to industry standard formats. In the insurance industry, XSLT is used to translate internal forms into industry standard ACORD (an XML dialect ) format. XSLT can be used to transform an XML document into other types of documents. This capability is useful for creating HTML when XML is being displayed in a browser, creating a wireless-suitable presentation, emitting VoiceXML for a voice response system85you get the idea. XQueryXQuery is an emerging transformation language covering the same territory that XSLT does, but in a different, more query-focused way. You could argue that XSLT is more amenable to document-style transformation ”for example, transforming an XML document into an HTML document ”and that XQuery is better at data-style transformation, such as querying an XML document with the result being another XML document. (This is not altogether true, however; both XSLT and XQuery are perfectly capable of doing both.) As you will see in the following example, XQuery was influenced heavily by SQL and other query languages, so you would likely use XQuery when you want to query an XML document, or multiple documents joined together, like you would a database. XQuery relies heavily on XPath. In fact, with XPath 2.0, the two technologies are tightly coupled ”so much so that one of the many XQuery specifications is titled the XQuery 1.0 and XPath 2.0 Data Model (see the XQuery 1.0 and XPath 2.0 Data Model at http://www.w3.org/TR/xpath-datamodel/ ) . Quite often, an XQuery looks like an XPath statement surrounded by some outer XML, like this: <books> { doc("http://bstore1.example.com/bib.xml")//author } </books> Notice the XPath statement within the braces after the XQuery function doc("http://..") ; you probably guessed that this statement points to the XML document data you are querying. You can put any XPath statement you want in braces throughout an XML template. The result of the XQuery will be an XML document that looks like this: <books> <author>Fred Jones</author> <author>James Thurber</author> </books> This example of XQuery is extremely simple, but this type of transformation is very valuable . Although this example does not show it, XQuery defines a full query structure similar to SQL, usually abbreviated FLWR (pronounced FLOWER), which stands for For, Let, Where, Return . This book does not go into great detail on XQuery, so suffice it to say that XQuery is extremely powerful and can become complex very quickly. The specifications for XQuery are among the most voluminous, with complexity rivaling the XML Schema specification. Much of this complexity is related to striving to meet the challenge of both data-oriented and document-oriented use cases and also making sure that XQuery is as "correct," in a mathematical/logical sense, as possible. Dozens of XQuery implementations are on the market, and it is a foregone conclusion that XQuery will be an important technology for manipulating and querying XML in the future. Note At least a dozen formal W3C specifications are related to XQuery, and many more papers and presentations (but very few primers, unfortunately ) are available. You can find a good online article introducing XQuery written by Howard Katz from FatDog software on IBM developerWorks at http://www-106.ibm.com/developerworks/xml/library/x-xquery.html XMLBeansXMLBeans is a tool that allows developers to access the full power of XML in a Java-friendly way. It is an XML-Java binding tool. The idea is that you can take advantage of the richness and features of XML and XML Schema and have these features mapped as naturally as possible to the equivalent Java language and typing constructs. XMLBeans uses XML Schema to compile Java interfaces and classes that you can then use to access and modify XML instance data. Using XMLBeans is similar to using any other Java interface/class. When there is an XML element <Foo> in an XML document, XMLBeans will present a getFoo or setFoo method just as you would expect when working with Java. Although a major use of XMLBeans is to access XML instance data with strongly typed Java classes, there are also APIs that allow you access to the full XML infoset as well as allow you to reflect into the XML Schema itself through an XML Schema Object model. Note XMLBeans was submitted to Apache by BEA Systems in September 2003 and is currently in the Apache incubation process. [9]
XML's Role in Web Services SecurityEverything in Web services is described and specified in XML. Good or bad, that is a fact. SOAP is an XML format. SAML ”a way of expressing identity and what an identity is allowed to do ”is an XML format. All the WS-Security specifications are XML formats. So, there is an overarching need for standards for expressing security data in XML format. There has been no need to invent new cryptography technologies for XML or Web services. The XML security and Web services security standards developers have applied tried-and-true cryptography directly to XML. This is important because we need persistent message-level security, and by leveraging decades of well- tested cryptography, we are less likely to get it wrong. XML messages move from server to server and may make several hops in moving from source to destination; while doing so, these messages need to maintain their security the entire way. The Transport Layer Security (TLS but alternatively called SSL) works only point to point, so messages are decrypted as soon as a server receives them. This means the messages are in the clear on the server, and if they need to move on to another server, they need to be re-encrypted, a prohibitively expensive proposition. This need for keeping messages secret led to the development of XML Encryption, the topic of Chapter 5, "Ensuring Confidentiality of XML Messages." Besides message-level confidentiality, there is a need for XML message integrity. Are the bits in the message that is received absolutely identical to the bits in the message that was sent? Additionally, who was the sender of the message? Not all messages require that these questions be answered, but when purchase orders, patient records, contracts, and thousands of other types of critical documents are being transported, it is essential that they are. These questions are answered by XML Signature, the topic of Chapter 4, "Safeguarding the Identity and Integrity of XML Messages." Web services will, more often than not, access critical data and services of organizations that do not want that data accessed by the wrong entities. They want the individuals, organizations, and machines accessing their information to be authorized to do so. They need to know for sure who it is (machine or individual), and they need to know what that machine or individual is trying to do. In security vernacular, these organizations need authentication and authorization. SAML is the XML specification for identity, authentication, and authorization. We will discuss SAML in Chapter 6. SAML is the basis of some very important projects such as The Liberty Alliance and Microsoft Passport, both of which we also discuss in Chapter 6. When you know the authenticated identity of the Web service client, you need to specify in finely granular fashion the rights the client has to access specific content and services. There are currently two somewhat overlapping standards for this task; they are known as XACML and XrML. We cover both in Chapter 9, "Trust, Access Control, and Rights for Web Services." As you build security into your Web services, the need for Public Key Infrastructure (PKI) will become readily apparent. You will need a way to prove the identity of sender, recipient, or both. Because you cannot assume people are always who they claim to be, you need trusted third parties whom you trust to vouch for the claims of people presenting their identities to you. This is the role of PKI, which is discussed in detail in Chapter 3. PKI for Web services is specified in XML format in an emerging standard called XML Key Management Specification (XKMS). We believe that Web services, with its strong need for keys that can be used to encrypt, decrypt, and sign data, will be the strongest impetus for PKI since SSL drove the need for server-based X.509 certificates. This being so, the XKMS standard, which specifies how keys are created, exchanged, and tested for validity within the context of Web services, will be an important part of the security foundation of Web services. XKMS is covered in detail in Chapter 9. The standard framework for including XML-formatted security data into SOAP messages is WS-Security. WS-Security builds on all the XML security standards we have just mentioned, such as XML Signature, XML Encryption, SAML, XACML, and XrML. WS-Security does not invent any new security concepts or standards; it simply extends SOAP to include security data about the messages a particular SOAP envelope is carrying. WS-Security is the focus of Chapter 7. A very useful way to look at the role of XML in Web Services Security is to examine the relationships among all the XML security frameworks that make up the overall Web services standards stack. This relationship is shown in Figure 2.3. Figure 2.3. XML frameworks that define the core Web Services Security specification.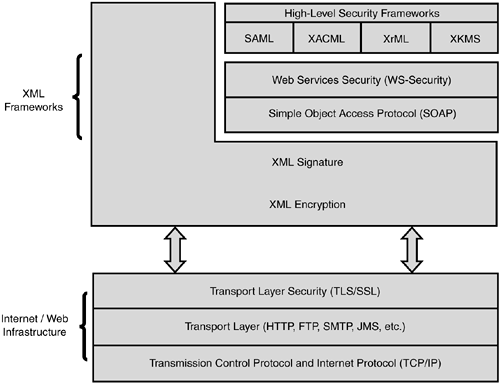
|
| < Day Day Up > |
EAN: 2147483647
Pages: 119