12.9 BST Implementations of Other ADT Operations
The recursive implementations given in Section 12.5 for the fundamental search, insert, and sort operations using binary tree structures are straightforward. In this section, we consider implementations of select, join, and remove. One of these, select, also has a natural recursive implementation, but the others can be cumbersome to implement and can lead to performance problems. The select operation is important to consider because the ability to support select and sort efficiently is one reason that BSTs are preferred over competing structures for many applications. Some programmers even avoid using BSTs so that they need not deal with the remove operation; in this section, we shall see a compact implementation that ties together these operations and uses the rotation-to-the-root technique of Section 12.8.
Generally, the operations involve moving down a path in the tree; so, for random BSTs, we expect the costs to be logarithmic. However, we cannot take for granted that BSTs will stay random when multiple operations are performed on the trees. We shall return to this issue at the end of this section.
To implement select, we can use a recursive procedure that is analogous to the quicksort-based selection method that is described in Section 7.8. In this discussion, as in Section 7.8, we use zero-based indexing so that, for example, we choose k = 3 to get the item with the fourth smallest key because that one would be in a[3] if the items were in sorted order in the array a. To find the item with the (k + 1)st smallest key in a BST, we check the number of nodes in the left subtree. If there are k nodes there, then we return the item at the root. Otherwise, if the left subtree has more than k nodes, we (recursively) look for the item with the (k + 1)st smallest key there. If neither of these conditions holds, then the left subtree has t items with t < k, and the item with the (k + 1)st smallest key in the BST is the item with the (k - t)th smallest key in the right subtree. Program 12.20 is a direct implementation of this method. As usual, since each execution of the method ends with at most one recursive call, a nonrecursive version is immediate (see Exercise 12.89).
Program 12.20 Selection with a BST
This recursive procedure finds the item with the (k + 1)st smallest key in a BST, assuming an eager count implementation where the subtree size is maintained for each tree node (see Exercise 12.60). Compare the program with quicksort-based selection in an array (Program 9.6).
private ITEM selectR(Node h, int k) { if (h == null) return null; int t = (h.l == null) ? 0 : h.l.N; if (t > k) return selectR(h.l, k); if (t < k) return selectR(h.r, k-t-1); return h.item; } ITEM select(int k) { return selectR(head, k); } The select implementation in Program 12.20 is the primary algorithmic motivation for maintaining a subtree-size field in each BST node. We also use this field to support a trivial eager count implementation (see Exercise 12.60), and we shall see another use in Chapter 13. The drawbacks to having the subtree-size field are twofold: it uses extra space in every node, and every method that changes the tree needs to update the field. Maintaining the subtree-size field may not be worth the trouble in some applications where insert and search are the primary operations, but it is a small price to pay in applications where it is important to support the select operation in a dynamic symbol table.
We can change this implementation of the select operation into a partition operation, which rearranges the tree to put the kth smallest element at the root, with precisely the same recursive technique that we used for root insertion in Section 12.8: If we (recursively) put the desired node at the root of one of the subtrees, we can then make it the root of the whole with a single rotation. Program 12.21 gives an implementation of this method. Like rotations, partitioning is not an ADT operation because it is a method that transforms a particu-lar symbol-table representation and should be transparent to clients. Rather, it is an auxiliary routine that we can use to implement ADT operations or to make them run more efficiently. Figure 12.18 depicts an example showing how, in the same way as in Figure 12.15,this process is equivalent to proceeding down the path from the root to the desired node in the tree, then climbing back up, performing rotations to bring the node up to the root.
Figure 12.18. Partitioning of a BST
This sequence depicts the result (bottom) of partitioning an example BST (top) about the median key, using (recursive) rotation in the same manner as for root insertion.
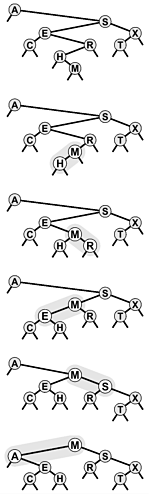
Program 12.21 Partitioning of a BST
Adding rotations after the recursive calls transforms the selection method of Program 12.20 into a method that puts the item with the (k + 1)st smallest key in the BST at the root.
Node partR(Node h, int k) { int t = (h.l == null) ? 0 : h.l.N; if (t > k) { partR(h.l, k); h = rotR(h); } if (t < k) { partR(h.r, k-t-1); h = rotL(h); } return h; } To remove a node with a given key from a BST, we first check whether the node is in one of the subtrees. If it is, we replace that subtree with the result of (recursively) removing the node from it. If the node to be removed is at the root, we replace the tree with the result of combining the two subtrees into one tree. Several options are available for accomplishing the combination. One approach is illustrated in Figure 12.19, and an implementation is given in Program 12.22. To combine two BSTs with all keys in the second known to be larger than all keys in the first, we apply the partition operation on the second tree in order to bring the smallest element in that tree to the root. At this point, the left subtree of the root must be empty (otherwise, there would be a smaller element than the one at the root a contradiction), and we can finish the job by replacing that link with a link to the first tree. Figure 12.20 shows a series of removals in an example tree, which illustrate some of the situations that can arise.
Figure 12.19. Removal of the root in a BST
This diagram shows the result (bottom) of removing the root of an example BST (top). First, we remove the node, leaving two sub-trees (second from top). Then, we partition the right subtree to put its smallest element at the root (third from top), leaving the left link pointing to an empty subtree. Finally, we replace this link with a link to the left subtree of the original tree (bottom).
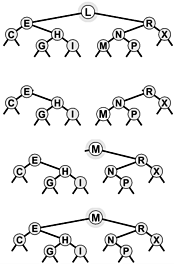
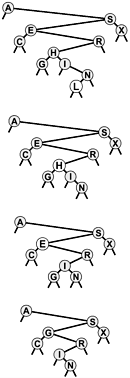
Figure 12.20. BST node removal
This sequence depicts the result of removing the nodes with keys L, H, and E from the BST at the top. First, the L is simply removed, since it is at the bottom. Second, the H is replaced with its right child, the I, since the left child of I is empty. Finally, the E is replaced with its successor in the tree, the G.
This approach is asymmetric and is ad hoc in one sense: Why use the smallest key in the second tree as the root for the new tree, rather than the largest key in the first tree? That is, why do we choose to replace the node that we are removing with the next node in the inorder traversal of the tree, rather than the previous node? We also might want to consider other approaches. For example, if the node to be removed has a null left link, why not just make its right child the new root, rather than using the node with smallest key in the right subtree? Various similar modifications to the basic remove procedure have been suggested. Unfortunately, they all suffer from a similar flaw: The tree remaining after removal is not random, even if the tree was random beforehand. Moreover, it has been shown that Program 12.22 tends to leave a tree slightly unbalanced (average height proportional to ![]() ) if the tree is subjected to a large number of random remove insert pairs (see Exercise 12.95).
) if the tree is subjected to a large number of random remove insert pairs (see Exercise 12.95).
These differences may not be noticed in practical applications unless N is huge. Still, this combination of an inelegant algorithm with undesirable performance characteristics is unsatisfying. In Chapter 13, we shall examine two different ways to address this situation.
It is typical of search algorithms to require significantly more complicated implementations for removal than for search. The key values play an integral role in shaping the structure, so removal of a key can involve complicated repairs. One alternative is to use a lazy removal strategy, leaving removed nodes in the data structure but marking them as "removed" so that they can be ignored in searches. In the search implementation in Program 12.15, we can implement this strategy by skipping the equality test for such nodes. We must make sure that large numbers of marked nodes do not lead to excessive waste of time or space; but if removals are infrequent, the extra cost may not be significant. We could reuse the marked nodes on future insertions when convenient (for example, it would be easy to do so for nodes at the bottom of the tree). Or we could periodically rebuild the entire data structure, leaving out the marked nodes. These considerations apply to any data structure involving insertions and removals they are not peculiar to symbol tables.
We conclude this chapter by considering the implementation of remove with handles and join for symbol-table ADT implementations that use BSTs. We assume that handles are links and omit further discussion about packaging issues so that we can concentrate on the two basic algorithms.
The primary challenge in implementing a method to remove a node with a given handle (link) is the same as it was for linked lists: We need to change the pointer in the structure that points to the node being removed. There are at least four ways to address this problem. First, we could add a third link in each tree node, pointing to its parent. The disadvantage of this arrangement is that it is cumbersome to maintain extra links, as we have noted before on several occasions. Second, we could use the key in the item to search in the tree, stopping when we find a matching pointer. This approach suffers from the disadvantage that the average position of a node is near the bottom of the tree, and this approach therefore requires an unnecessary trip through the tree. Third, in a low-level language such as C, we could use a pointer to the pointer to the node as the handle. This method is difficult to implement directly in Java. Fourth, we could adopt a lazy approach, marking removed nodes and periodically rebuilding the data structure, as just described.
The last operation for symbol-table ADTs that we need to consider is the join operation. In a BST implementation, this amounts to merging two trees. How do we join two BSTs into one?
Various algorithms present themselves to do the job, but each has certain disadvantages. For example, we could traverse the first BST, inserting each of its nodes into the second BST (this algorithm is a one-liner: wrap insert into the second BST in an object used as a parameter to a traversal of the first BST). This solution does not have linear running time, since each insertion could take linear time. Another idea is to traverse both BSTs, put the items into an array, merge them, and then build a new BST. This operation can be done in linear time, but it also uses a potentially large array.
Program 12.23 is a compact linear-time recursive implementation of the join operation. First, we insert the root of the first BST into the second BST, using root insertion. This operation gives us two subtrees with keys known to be smaller than this root, and two subtrees with keys known to be larger than this root, so we get the result by (recursively) combining the former pair to be the left subtree of the root and the latter to be the right subtree of the root (!). Each node can be the root node on a recursive call at most once, so the total time is linear.
Program 12.22 Removal of a node with a given key in a BST
This implementation of the remove operation removes the first node with key v encountered in the BST. Working top down, it makes recursive calls for the appropriate subtree until the node to be removed is at the root. Then, it replaces the node with the result of combining its two subtrees the smallest node in the right subtree becomes the root, then its left link is set to point to the left subtree.
private Node joinLR(Node a, Node b) { if (b == null) return a; b = partR(b, 0); b.l = a; return b; } private Node removeR(Node h, KEY v) { if (h == null) return null; KEY w = h.item.key(); if (less(v, w)) removeR(h.l, v); if (less(w, v)) removeR(h.r, v); if (equals(v, w)) h = joinLR(h.l, h.r); return h; } void remove(KEY v) { removeR(head, v); } An example is shown in Figure 12.21. Like removal, this process is asymmetric and can lead to trees that are not well balanced, but randomization provides a simple fix, as we shall see in Chapter 13. Note that the number of comparisons used for join must be at least linear in the worst case; otherwise, we could develop a sorting algorithm that uses fewer than N lg N comparisons, using an approach such as bottom-up mergesort (see Exercise 12.99).
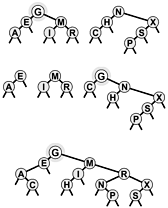
Figure 12.21. Joining of two BSTs
This diagram shows the result (bottom) of combining two example BSTs (top). First, we insert the root G of the first tree into the second tree, using root insertion (second from top). We are left with two subtrees with keys less than G and two subtrees with keys greater than G. Combining both pairs (recursively) gives the result (bottom).
We have not included the code necessary to maintain the count field in BST nodes during the transformations for join and remove, which is necessary for applications where we want to support select (Program 12.20) as well. This task is conceptually simple, but requires some care. One systematic way to proceed is to implement a small utility method that sets the count field in a node with a value one greater than the sum of the count fields of its children, then call that routine for every node whose links are changed. Specifically, we can do so for both nodes in rotL and rotR in Program 12.18, which suffices for the transformations in Program 12.19 and Program 12.21,since they transform trees solely with rotations. For joinLR and removeR in Program 12.22 and join in Program 12.23, it suffices to call the node-count update routine for the node to be returned, just before the return statement.
Program 12.23 Joining of two BSTs
If either BST is empty, the other is the result. Otherwise, we combine the two BSTs by (arbitrarily) choosing the root of the first as the root, root inserting that root into the second, then (recursively) combining the pair of left subtrees and the pair of right subtrees.
private Node joinR(Node a, Node b) { if (b == null) return a; if (a == null) return b; insertT(b, a.item); b.l = joinR(a.l, b.l); b.r = joinR(a.r, b.r); return b; } public void join(ST b) { head = joinR(head, b.head); } The basic search, insert, and sort operations for BSTs are easy to implement and perform well with even a modicum of randomness in the sequence of operations, so BSTs are widely used for dynamic symbol tables. They also admit simple recursive solutions to support other kinds of operations, as we have seen for select, remove, and join in this chapter, and as we shall see for many examples later in the book.
Despite their utility, there are two primary drawbacks to using BSTs in applications. The first is that they require a substantial amount of space for links. We often think of links and records as being about the same size (say, one machine word) if that is the case, then a BST implementation uses two-thirds of its allocated memory for links and only one-third for keys. Our use of myKey and myItem objects adds two or three more references per item (see Exercise 12.63). This effect is less important in applications with large records and more important in environments where pointers are large. If memory is at a premium, we may prefer one of the open-addressing hashing methods of Chapter 14 to using BSTs.
The second drawback of using BSTs is the distinct possibility that the trees could become poorly balanced and lead to slow performance. In Chapter 13, we examine several approaches to providing performance guarantees. If memory space for links is available, these algorithms make BSTs an attractive choice to serve as the basis for implementation of symbol-table ADTs, because they lead to guaranteed fast performance for a large set of useful ADT operations.
Exercises
12.89 Implement a nonrecursive BST select method (see Program 12.20).
12.92 Implement a nonrecursive BST remove method (see Program 12.22).
12.93 Implement a version of remove for BSTs (Program 12.22) that removes all nodes in the tree that have keys equal to the given key.
12.95 Run experiments to determine how the height of a BST grows in response to a long sequence of alternating random insertions and removals in a random tree of N nodes, for N = 10, 100, and 1000, and for up to N2 insertion removal pairs for each N.
12.96 Implement a version of remove (see Program 12.22) that makes a random decision whether to replace the node to be removed with that node's predecessor or successor in the tree. Run experiments as described in Exercise 12.95 for this version.
12.100 Implement a version of join (see Program 12.23) that makes a random decision whether to use the root of the first tree or the root of the second tree for root of the result tree. Run experiments as described in Exercise 12.98 for this version.
| Top |
EAN: 2147483647
Pages: 158