Section 2.5. Overview of Processes in MINIX 3
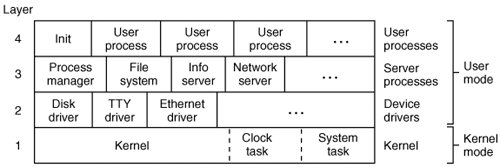
2.5. Overview of Processes in MINIX 3Having completed our study of the principles of process management, interprocess communication, and scheduling, we can now take a look at how they are applied in MINIX 3. Unlike UNIX, whose kernel is a monolithic program not split up into modules, MINIX 3 itself is a collection of processes that communicate with each other and also with user processes, using a single interprocess communication primitivemessage passing. This design gives a more modular and flexible structure, making it easy, for example, to replace the entire file system by a completely different one, without having even to recompile the kernel. 2.5.1. The Internal Structure of MINIX 3Let us begin our study of MINIX 3 by taking a bird's-eye view of the system. MINIX 3 is structured in four layers, with each layer performing a well-defined function. The four layers are illustrated in Fig. 2-29. Figure 2-29. MINIX 3 is structured in four layers. Only processes in the bottom layer may use privileged (kernel mode) instructions. |
Component | Description | Loaded by |
|---|---|---|
kernel | Kernel + clock and system tasks | (in boot image) |
pm | Process manager | (in boot image) |
fs | File system | (in boot image) |
rs | (Re)starts servers and drivers | (in boot image) |
memory | RAM disk driver | (in boot image) |
log | Buffers log output | (in boot image) |
tty | Console and keyboard driver | (in boot image) |
driver | Disk (at, bios, or floppy) driver | (in boot image) |
init | parent of all user processes | (in boot image) |
floppy | Floppy driver (if booted from hard disk) | /etc/rc |
is | Information server (for debug dumps) | /etc/rc |
cmos | Reads CMOS clock to set time | /etc/rc |
random | Random number generator | /etc/rc |
printer | Printer driver | /etc/rc |
Initialization of the Process Tree
Init is the first user process, and also the last process loaded as part of the boot image. You might think building of a process tree such as that of Fig. 1-5 begins once init starts running. Well, not exactly. That would be true in a conventional operating system, but MINIX 3 is different. First, there are already quite a few system processes running by the time init gets to run. The tasks CLOCK and SYSTEM that run within the kernel are unique processes that are not visible outside of the kernel. They receive no PIDs and are not considered part of any tree of processes. The process manager is the first process to run in user space; it is given PID 0 and is neither a child nor a parent of any other process. The reincarnation server is made the parent of all the other processes started from the boot image (e.g., the drivers and servers). The logic of this is that the reincarnation server is the process that should be informed if any of these should need to be restarted.
As we will see, even after init starts running there are differences between the way a process tree is built in MINIX 3 and the conventional concept. Init in a UNIX-like system is given PID 1, and even though init is not the first process to run, the traditional PID 1 is reserved for it in MINIX 3. Like all the user space processes in the boot image (except the process manager), init is made one of the children of the reincarnation server. As in a standard UNIX-like system, init first executes the /etc/rc shell script. This script starts additional drivers and servers that are not part of the boot image. Any program started by the rc script will be a child of init. One of the first programs run is a utility called service. Service itself runs as a child of init, as would be expected. But now things once again vary from the conventional.
Service is the user interface to the reincarnation server. The reincarnation server starts an ordinary program and converts it into a system process. It starts floppy (if it was not used in booting the system), cmos (which is needed to read the real-time clock), and is, the information server which manages the debug dumps that are produced by pressing function keys (F1, F2, etc.) on the console keyboard. One of the actions of the reincarnation server is to adopt all system processes except the process manager as its own children.
After the cmos device driver has been started the rc script can initialize the real-time clock. Up to this point all files needed must be found on the root device. The servers and drivers needed initially are in the /sbin directory; other commands needed for startup are in /bin. Once the initial startup steps have been completed other file systems such as /usr are mounted. An important function of the rc script is to check for file system problems that might have resulted from a previous system crash. The test is simplewhen the system is shutdown correctly by executing the shutdown command an entry is written to the login history file, /usr/adm/wtmp. The command shutdown C checks whether the last entry in wtmp is a shutdown entry. If not, it is assumed an abnormal shutdown occurred, and the fsck utility is run to check all file systems. The final job of /etc/rc is to start daemons. This may be done by subsidiary scripts. If you look at the output of a ps axl command, which shows both PIDs and parent PIDs (PPIDs), you will see that daemons such as update and usyslogd will normally be the among the first persistent processes which are children of init.
Finally init reads the file /etc/ttytab, which lists all potential terminal devices. Those devices that can be used as login terminals (in the standard distribution, just the main console and up to three virtual consoles, but serial lines and network pseudo terminals can be added) have an entry in the getty field of /etc/ttytab, and init forks off a child process for each such terminal. Normally, each child executes /usr/bin/getty which prints a message, then waits for a name to be typed. If a particular terminal requires special treatment (e.g., a dial-up line) /etc/ttytab can specify a command (such as /usr/bin/stty) to be executed to initialize the line before running getty.
When a user types a name to log in, /usr/bin/login is called with the name as its argument. Login determines if a password is required, and if so prompts for and verifies the password. After a successful login, login executes the user's shell (by default /bin/sh, but another shell may be specified in the /etc/passwd file). The shell waits for commands to be typed and then forks off a new process for each command. In this way, the shells are the children of init, the user processes are the grandchildren of init, and all the user processes in the system are part of a single tree. In fact, except for the tasks compiled into the kernel and the process manager, all processes, both system processes and user processes, form a tree. But unlike the process tree of a conventional UNIX system, init is not at the root of the tree, and the structure of the tree does not allow one to determine the order in which system processes were started.
The two principal MINIX 3 system calls for process management are fork and exec. Fork is the only way to create a new process. Exec allows a process to execute a specified program. When a program is executed, it is allocated a portion of memory whose size is specified in the program file's header. It keeps this amount of memory throughout its execution, although the distribution among data segment, stack segment, and unused can vary as the process runs.
All the information about a process is kept in the process table, which is divided up among the kernel, process manager, and file system, with each one having those fields that it needs. When a new process comes into existence (by fork), or an old process terminates (by exit or a signal), the process manager first updates its part of the process table and then sends messages to the file system and kernel telling them to do likewise.
2.5.3. Interprocess Communication in MINIX 3
Three primitives are provided for sending and receiving messages. They are called by the C library procedures
send(dest, &message);
to send a message to process dest,
receive(source, &message);
to receive a message from process source (or ANY), and
sendrec(src_dst, &message);
to send a message and wait for a reply from the same process. The second parameter in each call is the local address of the message data. The message passing mechanism in the kernel copies the message from the sender to the receiver. The reply (for sendrec) overwrites the original message. In principle this kernel mechanism could be replaced by a function which copies messages over a network to a corresponding function on another machine, to implement a distributed system. In practice this would be complicated somewhat by the fact that message contents sometimes include pointers to large data structures, and a distributed system would have to provide for copying the data itself over the network.
Each task, driver or server process is allowed to exchange messages only with certain other processes. Details of how this is enforced will be described later. The usual flow of messages is downward in the layers of Fig 2-29, and messages can be between processes in the same layer or between processes in adjacent layers. User processes cannot send messages to each other. User processes in layer 4 can initiate messages to servers in layer 3, servers in layer 3 can initiate messages to drivers in layer 2.
When a process sends a message to a process that is not currently waiting for a message, the sender blocks until the destination does a receive. In other words, MINIX 3 uses the rendezvous method to avoid the problems of buffering sent, but not yet received, messages. The advantage of this approach is that it is simple and eliminates the need for buffer management (including the possibility of running out of buffers). In addition, because all messages are of fixed length determined at compile time, buffer overrun errors, a common source of bugs, are structurally prevented.
The basic purpose of the restrictions on exchanges of messages is that if process A is allowed to generate a send or sendrec directed to process B, then process B can be allowed to call receive with A designated as the sender, but B should not be allowed to send to A. Obviously, if A tries to send to B and blocks, and B tries to send to A and blocks we have a deadlock. The "resource" that each would need to complete the operations is not a physical resource like an I/O device, it is a call to receive by the target of the message. We will have more to say about deadlocks in Chap. 3.
Occasionally something different from a blocking message is needed. There exists another important message-passing primitive. It is called by the C library procedure
notify(dest);
and is used when a process needs to make another process aware that something important has happened. A notify is nonblocking, which means the sender continues to execute whether or not the recipient is waiting. Because it does not block, a notification avoids the possibility of a message deadlock.
The message mechanism is used to deliver a notification, but the information conveyed is limited. In the general case the message contains only the identity of the sender and a timestamp added by the kernel. Sometimes this is all that is necessary. For instance, the keyboard uses a notify call when one of the function keys (F1 to F12 and shifted F1 to F12) is pressed. In MINIX 3, function keys are used to trigger debugging dumps. The Ethernet driver is an example of a process that generates only one kind of debug dump and never needs to get any other communication from the console driver. Thus a notification to the Ethernet driver from the keyboard driver when the dump-Ethernet-stats key is pressed is unambiguous. In other cases a notification is not sufficient, but upon receiving a notification the target process can send a message to the originator of the notification to request more information.
There is a reason notification messages are so simple. Because a notify call does not block, it can be made when the recipient has not yet done a receive. But the simplicity of the message means that a notification that cannot be received is easily stored so the recipient can be informed of it the next time the recipient calls receive. In fact, a single bit suffices. Notifications are meant for use between system processes, of which there can be only a relatively small number. Every system process has a bitmap for pending notifications, with a distinct bit for every system process. So if process A needs to send a notification to process B at a time when process B is not blocked on a receive, the message-passing mechanism sets a bit which corresponds to A in B's bitmap of pending notifications. When B finally does a receive, the first step is to check its pending notifications bitmap. It can learn of attempted notifications from multiple sources this way. The single bit is enough to regenerate the information content of the notification. It tells the identity of the sender, and the message passing code in the kernel adds the timestamp when it is delivered. Timestamps are used primarily to see if timers have expired, so it does not matter that the timestamp may be for a time later than the time when the sender first tried to send the notification.
There is a further refinement to the notification mechanism. In certain cases an additional field of the notification message is used. When the notification is generated to inform a recipient of an interrupt, a bitmap of all possible sources of interrupts is included in the message. And when the notification is from the system task a bitmap of all pending signals for the recipient is part of the message. The natural question at this point is, how can this additional information be stored when the notification must be sent to a process that is not trying to receive a message? The answer is that these bitmaps are in kernel data structures. They do not need to be copied to be preserved. If a notification must be deferred and reduced to setting a single bit, when the recipient eventually does a receive and the notification message is regenerated, knowing the origin of the notification is enough to specify which additional information needs to be included in the message. And for the recipient, the origin of the notification also tells whether or not the message contains additional information, and, if so, how it is to be interpreted,
A few other primitives related to interprocess communication exist. They will be mentioned in a later section. They are less important than send, receive, sendrec, and notify.
2.5.4. Process Scheduling in MINIX 3
The interrupt system is what keeps a multiprogramming operating system going. Processes block when they make requests for input, allowing other processes to execute. When input becomes available, the current running process is interrupted by the disk, keyboard, or other hardware. The clock also generates interrupts that are used to make sure a running user process that has not requested input eventually relinquishes the CPU, to give other processes their chance to run. It is the job of the lowest layer of MINIX 3 to hide these interrupts by turning them into messages. As far as processes are concerned, when an I/O device completes an operation it sends a message to some process, waking it up and making it eligible to run.
Interrupts are also generated by software, in which case they are often called traps. The send and receive operations that we described above are translated by the system library into software interrupt instructions which have exactly the same effect as hardware-generated interruptsthe process that executes a software interrupt is immediately blocked and the kernel is activated to process the interrupt. User programs do not refer to send or receive directly, but any time one of the system calls listed in Fig. 1-9 is invoked, either directly or by a library routine, sendrec is used internally and a software interrupt is generated.
Each time a process is interrupted (whether by a conventional I/O device or by the clock) or due to execution of a software interrupt instruction, there is an opportunity to redetermine which process is most deserving of an opportunity to run. Of course, this must be done whenever a process terminates, as well, but in a system like MINIX 3 interruptions due to I/O operations or the clock or message passing occur more frequently than process termination.
The MINIX 3 scheduler uses a multilevel queueing system. Sixteen queues are defined, although recompiling to use more or fewer queues is easy. The lowest priority queue is used only by the IDLE process which runs when there is nothing else to do. User processes start by default in a queue several levels higher than the lowest one.
Servers are normally scheduled in queues with priorities higher than allowed for user processes, drivers in queues with priorities higher than those of servers, and the clock and system tasks are scheduled in the highest priority queue. Not all of the sixteen available queues are likely to be in use at any time. Processes are started in only a few of them. A process may be moved to a different priority queue by the system or (within certain limits) by a user who invokes the nice command. The extra levels are available for experimentation, and as additional drivers are added to MINIX 3 the default settings can be adjusted for best performance. For instance, if it were desired to add a server to stream digital audio or video to a network, such a server might be assigned a higher starting priority than current servers, or the initial priority of a current server or driver might be reduced in order for the new server to achieve better performance.
In addition to the priority determined by the queue on which a process is placed, another mechanism is used to give some processes an edge over others. The quantum, the time interval allowed before a process is preempted, is not the same for all processes. User processes have a relatively low quantum. Drivers and servers normally should run until they block. However, as a hedge against malfunction they are made preemptable, but are given a large quantum. They are allowed to run for a large but finite number of clock ticks, but if they use their entire quantum they are preempted in order not to hang the system. In such a case the timed-out process will be considered ready, and can be put on the end of its queue. However, if a process that has used up its entire quantum is found to have been the process that ran last, this is taken as a sign it may be stuck in a loop and preventing other processes with lower priority from running. In this case its priority is lowered by putting it on the end of a lower priority queue. If the process times out again and another process still has not been able to run, its priority will again be lowered. Eventually, something else should get a chance to run.
A process that has been demoted in priority can earn its way back to a higher priority queue. If a process uses all of its quantum but is not preventing other processes from running it will be promoted to a higher priority queue, up to the maximum priority permitted for it. Such a process apparently needs its quantum, but is not being inconsiderate of others.
Otherwise, processes are scheduled using a slightly modified round robin. If a process has not used its entire quantum when it becomes unready, this is taken to mean that it blocked waiting for I/O, and when it becomes ready again it is put on the head of the queue, but with only the left-over part of its previous quantum. This is intended to give user processes quick response to I/O. A process that became unready because it used its entire quantum is placed at the end of the queue in pure round robin fashion.
With tasks normally having the highest priority, drivers next, servers below drivers, and user processes last, a user process will not run unless all system processes have nothing to do, and a system process cannot be prevented from running by a user process.
When picking a process to run, the scheduler checks to see if any processes are queued in the highest priority queue. If one or more are ready, the one at the head of the queue is run. If none is ready the next lower priority queue is similarly tested, and so on. Since drivers respond to requests from servers and servers respond to requests from user processes, eventually all high priority processes should complete whatever work was requested of them. They will then block with nothing to do until user processes get a turn to run and make more requests. If no process is ready, the IDLE process is chosen. This puts the CPU in a low-power mode until the next interrupt occurs.
At each clock tick, a check is made to see if the current process has run for more than its allotted quantum. If it has, the scheduler moves it to the end of its queue (which may require doing nothing if it is alone on the queue). Then the next process to run is picked, as described above. Only if there are no processes on higher-priority queues and if the previous process is alone on its queue will it get to run again immediately. Otherwise the process at the head of the highest priority nonempty queue will run next. Essential drivers and servers are given such large quanta that normally they are normally never preempted by the clock. But if something goes wrong their priority can be temporarily lowered to prevent the system from coming to a total standstill. Probably nothing useful can be done if this happens to an essential server, but it may be possible to shut the system down gracefully, preventing data loss and possibly collecting information that can help in debugging the problem.
EAN: 2147483647
Pages: 102