Comparing Disk Systems
Any platform you'll use will require some form of disk storage. Like processor cores, disks come in many shapes , forms, and make-up. As you'll see, there are a vast array (no pun intended) of disk technologies available, and most have their place and purpose in a WebSphere environment.
In the following sections, you'll look at the various disk technologies common to AIX (PowerPC), Solaris (SPARC), Linux, and Windows (Intel/AMD x86). After that, I'll discuss the pros and cons of each disk technology and provide support for selecting your disk technology.
Disk Technologies
You're probably familiar with the terms IDE and SCSI . Both of these terms refer to the leading disk technology or architecture on the market. There are several other disk architectures available, including Fibre Channel, Serial ATA (S-ATA), and the lesser-known FireWire models using the IEEE 1394 FireWire standard.
Disk technology ”or, more specifically , the choice and implementation of disk technology ”is important for your system. Next to CPU performance, the disk's subsubsystem is probably the next most important aspect for a WebSphere environment (or any environment for that matter).
How you lay out your disks (partitioning and so on), how you implement your disk layouts ”such as Redundant Array of Inexpensive Disks (RAID), Just Basic Old Disk (JBOD), and so on ”and what technology or architecture your disk subsystem is made up of will greatly affect the performance of an application.
You'll now go through the major disk architectures currently available.
ATA: IDE, EIDE
In 1990, the American National Standards Institute (ANSI) ratified an IDE-like standard, now known as ATA-IDE, or just ATA (which stands for Advanced Technology Attachment ). IDE for years now has been the leader in low-end servers and desktop workstations. It's a cheap and effective technology that provides quite good performance for general use.
IDE was really the first of the high-performing , low-cost disk technologies on the market. Not long after IDE appeared, an enhanced version, Enhanced Integrated Disk Electronics (EIDE), was released. The EIDE version is more commonly found in today's PCs, desktops, and notebooks in some form or another.
SCSI: SCSI-2 and Ultra SCSI
SCSI has long been touted as the leader in the storage market for servers. Competing closely with Fibre Channel, the various SCSI standards since SCSI-1 in 1981 all operate with a SCSI protocol and language.
SCSI is a mature and stable disk technology and provides a robust disk attachment platform for higher-end computing. SCSI drives ”or, more specifically, SCSI-2 and more recent SCSI implementations ”support a higher sustained throughput than the typical IDE-based drives . "Disk bandwidth" is higher in a relatively sized SCSI drive than a high-end IDE drive and therefore is better suited to more than one concurrent disk request.
As discussed previously, the majority of IDE drives can come fairly close to the more mainstream SCSI-based drives; however, because of the overall SCSI architecture, there's more growth potential ”in terms of performance ”in SCSI than there is in IDE.
Table 4-4 highlights some of the most mainstream SCSI drive configuration types.
| SCSI Type | Bus Width | Bus Speed | Cable Length (in Meters ) | Maximum Devices |
|---|---|---|---|---|
| Wide Ultra SCSI | 16 bits | 40 megabits (Mb) per second | 1.5 “3 | 8 |
| Ultra2 SCSI Low Voltage Differential (LVD) | 8 bits | 40Mb per second | 12 | 8 |
| Wide Ultra2 SCSI (LVD) | 16 bits | 80Mb per second | 12 | 16 |
| Wide Ultra3 SCSI (LVD) | 16 bits | 160Mb per second | 12 | 16 |
LVD was an important step in SCSI's evolution when it was introduced. Basically, pre-LVD SCSI implementations were limited by a number of factors, including the number of drives (or devices) that could be placed on a SCSI bus and how long the cables were.
As you can imagine, trying to squeeze eight SCSI drives onto a 1.5-meter cable is near impossible . Then came LVD, which essentially provides a differential-based bus technology. A second set of data lines is provided that allows for signals to be driven with the opposite electrical polarity as the original lines. If a 1 bit is represented by +5 volts in the standard data line, that same 1 bit is echoed on the supplemental data line as -5 volts.
As such, there's a higher overall voltage switch to represent the data. There's also redundancy in the transmission paths, and any outside noise that might enter the lines will be canceled out at the receiving end. Further, the resulting differentiated bus provides a boost in cable lengths to 25 meters.
Ultra160 and Ultra320
Ultra160 and Ultra320 are two technologies that are based on the core SCSI technology command set. Ultra160 supports the same speed as Ultra3 SCSI, with a reduced command set. Recently the Ultra320 SCSI flavor was released, which supports a maximum transfer speed of 320MB per second.
Ultra160 and Ultra320 are sound technologies; however, because of their implementation of a reduced SCSI command set, some features may be made available from your selected storage vendor. Be sure to validate the command set used in your Ultra160 and 320 implementations.
iSCSI
iSCSI is the Network Attached Storage (NAS) lover's pinnacle storage architecture. iSCSI is a network or Transmission Control Protocol/Internet Protocol (TCP/IP) implementation ”or, better put, an embedding of SCSI-3 into a protocol level (the TCP packet). In essence, it's an IP-based disk attachment technology.
iSCSI uses the same SCSI protocol commands used in standard SCSI, but the medium isn't a SCSI cable per se. Best of all, iSCSI is device independent. Imagine being able to mesh your data center storage systems and be able to access any data from any system ”long gone are the days where you wonder how you're going to get data off a mainframe when its only disk-connect technology is Escon!
Another obvious benefits of iSCSI is that data centers can now truly start to consolidate storage devices. Coupled with any of the various third-party storage provisioning (storage on demand) software packages, iSCSI can allow system architects and operation managers the ability to truly share disks and tape storage systems from anywhere . Consolidation of backup devices is another benefit of the iSCSI technology.
Some of you may be saying that it's like NAS. Well, it's kind of like NAS; however, it continues where NAS stops. NAS is still a semiclosed technology. You need specialized switches and potentially specialized Host Bus Adaptor (HBA) interface cards. With iSCSI, it's all TCP/IP, and it uses your existing network fabric of routers and switches. It also can share the existing TCP/IP-bound network adapter in your servers.
Obviously, if your data center storage I/O requirements are large, you may need to lay new cable and deploy additional switches to cater to the additional IP load. Networking vendors are also getting on the bandwagon. Companies such as Cisco are embedding iSCSI protocol handlers and offloads into their switching and routing gear. Although this type of hardware isn't required for a straightforward installation of iSCSI, it does appear to require skilled network engineers ! Figure 4-1 highlights a typical iSCSI implementation.
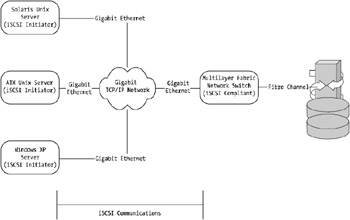
Figure 4-1: High-level iSCSI implementation
iSCSI is a fairly new network implementation and looks to have a long future. Many experts are touting iSCSI to be the replacement for FCAL given the theoretical no-distance limitation of iSCSI and the commodity-based iSCSI interfaces ”in other words, TCP and commodity Fast Ethernet/gigabit+ network infrastructure. There are now several vendors supplying 10GB Ethernet networking infrastructure, which makes the business case for iSCSI quite strong.
Currently, the market is fairly limited in terms of iSCSI, and therefore, I won't focus on this area a great deal. However, within the next year or two, iSCSI will gain a lot of momentum among the leading storage-connect technologies.
SAN and NAS
Although the Storage Area Network (SAN) and NAS technologies aren't technically at the same level as SCSI or ATA, they play an increasingly important part of data center and e-commence systems.
Storage Area Network (SAN)
SAN provides the ability for systems to interface with disk or storage devices over a Fibre-based switching infrastructure. SAN uses SAN switches, which are some-what similar to that of a IP network; however, SAN is closer in fundamental architecture to FCAL than IP.
SAN provides for the interconnection of commodity-type storage units to many systems. Many large enterprises are using SAN to create an enterprise storage array where all the host systems can interface with the centralized enterprise storage array over a SAN mesh.
Figure 4-2 shows a high level overview of how SAN could be implemented.
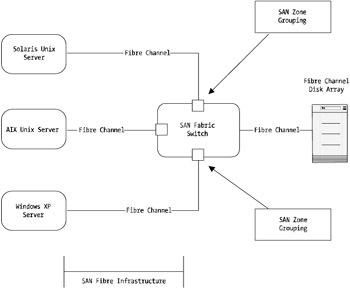
Figure 4-2: High-level SAN implementation
As you can see from Figure 4-2, the SAN allows for a many-to-many or a many-to-one relationship with hosts to storage devices. SAN supports a one-to-one relationship but unless you're trying to obtain some level of cost scalability by using SAN, one-to-one storage to host relationships is best implemented using straight Fibre Channel.
In Figure 4-2 the SAN infrastructure depicted represents a Fibre SAN interconnection that could be over any distance from several meters, or yards, to several hundred kilometers, or miles. There are important design considerations you need to be aware of if you're trying to extend your SAN over distances greater than several hundred kilometers, or miles. Several vendors supply technologies that help extend a SAN to long distances. However, when latency starts to impede performance, other technologies may be better choices such as NAS and iSCSI.
The idea behind SAN is really about storage consolidation and easy integration and management. It provides a wire interface speed of 100MB per second, similar to that of FCAL. However, the method of implementation can reduce or increase this figure greatly ”such as in a situation where you have four hosts interfacing via a SAN to a central disk storage array, with one SAN interconnect from the storage array to the SAN fabric. This would have four hosts sharing a single 100MB per second SAN interconnect from the SAN switch to the storage array.
Network Attached Storage (NAS)
NAS is SAN's counterpart in the enterprise storage market. Essentially, NAS is an IP-based storage network. Where SAN allows the sharing and meshing of storage systems via Fibre-based connections at FCAL-like speeds, NAS provides the sharing and meshing of storage systems via IP-based networks. That is, speeds such as 100Mb per second and 1000Mb per second are the current mass-market speeds in which you can connect your storage array to your hosts over NAS.
Of course, with appropriate bridges and switching hardware, you can increase these speeds via multiplexing and other wide-area technologies such as OC-12, OC-48, and beyond (655Mb per second, 2048Mb per second).
NAS is a great alternative to applications that aren't I/O intensive . In a WebSphere-based environment, unless your deployed J2EE applications require access to data stored at a great distance away (more than approximately 500 kilometers, or 300 miles), then NAS probably doesn't have a place in your high-performance WebSphere environment. With NAS, you get all the TCP/IP overhead you'd get with normal networking.
| Note | I don't want to give the impression that NAS isn't a good technology. I've seen it used in J2EE environments, and it can be a good choice under the right circumstances. At the end of the day, 99.9 percent of all systems can talk via IP. Therefore, it's currently the ultimate technology for interfacing one system type to another system type. Think of how easy it would be to interface a WebSphere-based application on a Sun Solaris system to an IBM MVS system when there's a need to access files on the mainframe from the WebSphere-based application on the Solaris system. Other options exist such as MQ Series, but NAS is a good alternative here. |
Fibre Channel Arbitrated Loop (FCAL)
Fibre Channel-based storage systems have been the high-end computing disk-connect technology of choice for the past 5 “10 years.
FCAL, using the Fibre Channel communications standard, operates in an arbitrated loop configuration whereby all nodes or devices in the loop must "arbitrate" to communicate onto the loop. FCAL most commonly operates using a 100MB per second interface speed, faster than most SCSI implementations and, despite its name , can operate on optical fiber or twisted pair mediums.
For higher-speed FCAL implementations, optical fiber is required. Fiber also has the advantages of being able to operate for longer distances than that of twisted pair. And remember, I'm talking optical fiber. It's not as easy to manipulate as its twisted pair or even SCSI counterparts. That's the trade-off for excellent performance.
Although FCAL is associated with a looping bus topology, it's possible to use Fibre Channel hubs, which allow the loop to be collapsed to individual loops between the end device (such as a disk) and the hub or switch. Like the old days of coaxial-based bus networks, in a full arbitrated loop configuration where all end devices are connected via a loop, if a single device is unplugged or fails, the entire loop fails. As you can imagine, if you have a great deal of data housed on disks with a legacy loop configuration and one disk fails, the resulting effect is disastrous. Figure 4-3 provides a high-level overview of how FCAL operates.
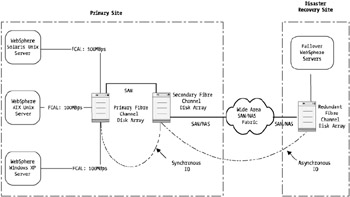
Figure 4-3: FCAL architecture
FCAL-based disks are available and are high performing (more than that of their SCSI counterparts at similar levels of capability and spindle speed). However, many storage vendors nowadays are providing FCAL interfaces to controllers within disk storage cabinets, and the disks themselves are connected to the FCAL "heads" or exposed controller interfaces. This helps reduce the costs of the disks themselves because you can use commodity SCSI or other forms of disk technology in place of FCAL disks while at the same time obtaining the same performance. You'll also get the added benefit of being able to house the disk cabinets away from the servers.
Unless your WebSphere-housed applications are referencing large amounts of data on disk at great frequency, or your disaster recovery data center architecture or other storage requirements require that your disks are located away from the host systems, FCAL could be an overkill for your needs. From a price to performance comparison, they're at the upper level of disk technology costs.
This is an important consideration and one with which many systems engineers and architects need to contend. Therefore, it shouldn't be displaced as an alternative, but remember that the investment is high compared to more standard SCSI implementations. Figure 4-4 depicts the method of locating your disks at a distance from your host's systems while using more standard disk technologies such as SCSI.
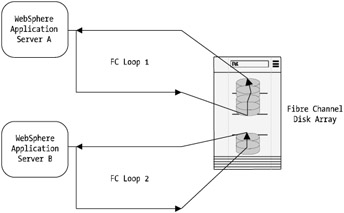
Figure 4-4: Distributed storage architecture example
Remember also that Ultra3 SCSI (Ultra160) can support 160MB per second, and the recently released Ultra320 is also becoming available from a number of vendors. These native SCSI-based technologies are typically better performing for the price and storage capacity you can obtain from FCAL.
On paper, the ATA-100 and ATA-133 are faster than standard FCAL but aren't suitable for large-scale deployment because of architecture limitations, such as the number of drives or devices on the bus. FCAL can still support 127 devices on a single arbitrated loop. If you multiplex your loops, you can get an order of magnitude more devices ”most high-end storage vendors support this.
Although FCAL is limited in performance to 100MB per second, many high-end storage vendors allow you to multipath and, as such, multiplex your storage connections to either SAN, NAS, or Direct Attached Storage (DAS) devices. EMC, one of the world's leading storage array vendors, is a prime candidate for this technology. I've been involved with systems implementations that required multiple DAS zonings to support more than 100MB per second disk I/O and, as such, utilized designs that used four 100MB per second FCAL interfaces, supporting a combined I/O performance rate of 400MB per second.
That all said, it's rumored that the 10GB per second FCAL standard isn't too far away. This technology will outpace anything else on the market. Being able to transfer approximately 1,000MB per second isn't a small measure. Many lower-end systems will struggle to support these speeds.
Even with today's fastest systems, I/O bandwidth (or system bus bandwidth, depending on your architecture of choice) will be in the order of 1.2GB per second and up to 9.6GB per second for sustained, nonaggregated performance.
In summary, FCAL is the Rolls Royce of storage technologies. It scales , can be highly distributed (cross-city and cross-country depending on your I/O characteristics), and has a clear technology growth path into higher-end speeds such as 10GB per second. If you're after top-performing technologies with good growth, FCAL is a good choice.
Serial ATA (S-ATA)
S-ATA is a relatively new disk-connect technology and one I highly recommend you watch. Unlike traditional ATA, which is Parallel-ATA (P-ATA), Serial-ATA (S-ATA) operates using a serial protocol layer, using a seven-wire flat connector, looking not unlike a USB connector.
With the serial interface, a smaller and easier cable design, and an over-hauled power interface supporting three voltage levels (as is found in the 2.5-inch drives typically associated with laptops and other portable devices supporting 2.5-inch hard disks), the overall physical implementation is far easier to use.
Current S-ATA technology is targeted to the low-end market such as desktop PCs and workstations but may eventually gain share in the server area. At the end of the day, the drives are still in essence using standard IDE/ATA technologies and, as such, are similar in performance to Ultra SCSI versus that of IDE/ATA.
Being a new standard means that many of the proven concepts from other disk technologies over the years have been incorporated into the standard. As such, the S-ATA standard will surely become the leading commodity or workstation disk technology in the coming 12 “18 months.
Furthermore, S-ATA is fast. The initial specification supports 150MB per second as standard per drive, and upcoming S-ATA 2 standards will see this speed increase to 300MB per second. Although it's initially only slightly faster than the current standard ATA standard (better known as ATA-133) that operates at 133MB per second, there's a clear and healthy growth path because of the use of a LVD signaling interface, similar to the high-speed Ultra160 and Ultra360 SCSI specifications.
Given the relatively low cost of S-ATA disks, you can purchase almost four S-ATA disks in place of one SCSI-based disk of relative size . Theoretically, this can produce top performance because the load is distributed over four spindles rather than the one. There are downfalls to this approach, however. Bus, HBA (if using an external device), and controller bandwidth may become saturated under this type of load while controlling the I/O and communications of many more disks.
At the end of the day, good solid capacity planning will prove whether this is possible.
"Way Out There" Disk Technologies
Before summarizing the various technologies associated with disks and their impact on a WebSphere implementation, I'll make a few final points about some upcoming disk interfacing technologies.
USB and FireWire are two connection technologies found mostly in desktop-based systems. Currently, they support speeds of 480Mb per second and 400Mb per second, respectively, and USB and FireWire do support low-end disk technologies.
At these speeds, used in a WebSphere server environment, especially one with lots of log file writing, opening files, and closing files (images, JSPs, servlets, and so on), they'll operate at sufficient I/O rates.
The roadmap for FireWire looks quite good. Currently operating at 400Mb per second, recently released draft specifications suggest speeds of 800Mb per second, 1.2 gigabits (Gb) per second, and 3.2Gb per second (I'm talking here megabits and gigabits per second, not megabytes and gigabytes per second).
Another interesting disk or storage technology I've seen is with the use of RAM disks. A small handful of sites I've worked on have implemented RAM disks. While booting the WebSphere application server, the contents of the installedApps directory where the deployed J2EE applications resided and the WebSphere cache directories have loaded into RAM disk. This provides quite a good degree of performance. The downfall is that any contents of the RAM disk are flushed after any system reboot. The need for a script that operates every five to ten minutes is essential to copy back changes and updates made to cache.
RAM disks aren't for everyone and should only really be used in a environment where many small I/Os are taking place to specific areas. I'll discuss this further in later chapters.
Summarizing Storage Technologies in WebSphere Environments
You've looked at a fair number of disk technologies in this chapter. What's important to you now, if it wasn't already, is to look at what is the best disk technology for your WebSphere environment. As you'd expect, there's no "one size fits all," but the following sections will provide some support for deciding on a disk technology.
These sections will break up the disk technologies and rate them in terms of their value or effectiveness in a J2EE WebSphere-based environment. The sections cover individual disk speed, overall architecture performance, architectural complexity, and cost.
Storage Technology: Disk Speed
Disk speed is obviously one of the most important points of any system. From a default position, disk speed in a WebSphere environment doesn't have a major impact on the overall performance of the application unless the application components are performing a lot of I/O to the storage technology.
Databases connected to your WebSphere application server for either repository information (for WebSphere 4) or application information will quickly become the failure point of your environment if you have slow or poorly configured disks.
Imagine a situation where your WebSphere-deployed applications are regularly making requests to a database to retrieve information. Let's assume it's something such as an online order and sales system.
Each page click would require some form of database query to retrieve the information. Using this example, you'll now look at the disk technologies and which ones work and which ones don't work.
| Caution | As I mentioned earlier, there's no one size fits all; however, this example should indicate the best practices for the various disks. |
Figure 4-5 shows the disk technologies. The ranking is performed based on future speed as well current speed.
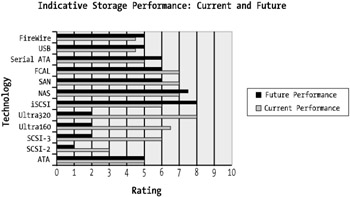
Figure 4-5: Disk performance overview
As you can see, the Ultra320 technology is the highest-performing disk technology. It's important to note that although Ultra160 and Ultra320 are theoretically faster than FCAL, direct FCAL-based disks are the best disk technologies. They offer fast onboard disk caches and quite often come with a great deal of onboard intelligence for real-time tuning and management of the disk I/O logic.
Storage Technology: Overall Performance
Like most things, overall performance consists of many components working together harmoniously. You can't strap a big Chevrolet engine to a budget family sedan and expect it to perform well. The same applies to storage technologies. You can have an array of IBM 73.5GB 15,000rpm drives yet a poorly performing storage bus, thus reducing your expensive disk array to nothing more than a bunch of perceived low-speed storage devices.
It's important to choose the right storage architecture for the "big picture." For this reason, it's important to plan and understand what your WebSphere applications will require. You need to ask questions, if they aren't already obvious, of application designers and architects, preferably before they commence development. The following questions are examples of what you can ask your developers or application architects to discover the fundamentals of the software architecture from a file I/O point of view:
-
If there's file I/O occurring, what's the nature of the I/O? (Is it random or sequential? How many concurrent requests will there be? What's the size of the I/O requests? What's the I/O transaction rate?)
-
Do the application components expect the resulting I/O to be completed within a certain timeframe?
-
Are the application components associated with the file I/O multithreaded? Specifically, are requests made to a file I/O factory in a separate thread, ensuring that I/O delays don't freeze the main thread of the application?
Let's look at those points in a little more detail.
Specifically, you should identify what the nature of the file I/O is. This will help determine what technology is viable for your system. For example, if the architects and software planners state that the requests are far and few between, such as simply logging information to an ASCII log file, then the I/O rate is minimal. Technologies such as NAS and the lower-end ATA-based technologies will perform the role sufficiently if the I/O transaction rate is low.
For ATA (S-ATA or P-ATA), the current technology standards support a fair amount of I/O. In the SCSI and FCAL worlds , you can roughly pin the number of I/Os for a particular disk on the number of revolutions per minute of the disk, divided by 100. For example, a 10,000rpm SCSI-2 disk will allow approximately 100 I/Os per second.
This rule doesn't always work, but it's a good guide. An ATA-based drive is somewhat slower, and the rate of I/O varies greatly. Depending on your manufacturer of choice, this reduction in performance can be anywhere from 20 “50 percent less than that of a similarly sized SCSI-based disk. This is primarily because of the actual ATA disk having slightly lower-performing onboard logic and chipsets.
Therefore, if your application architect states that with 5,000 concurrent users on your system, you'll be performing 500 file I/Os per second, or a 10 percent I/O to active session ratio. For this case, you'd want to have at least five SCSI-2 or SCSI-3 drives or five native FCAL or mixed/native FCAL and SCSI-2/3 drives. SAN would perform the role sufficiently as long as your fan-out ratio (the number of disks presented versus the number of systems interfacing to them and the number of host Fibre Channel connections to number or disk cabinet connections) is at worst 1:4 (one disk cabinet to Fibre Channel connection per four host-based Fibre Channel connections).
Of course, if you're looking to increase I/O performance and or provide some buffering to the five disks, look at striping your disks with either something such as RAID 5 or RAID 0 (or RAID 0+1 to gain mirroring). Doing this increases your number of spindles, which effectively increases the available file I/O rate ”more disks equal more I/Os per second.
Some disk vendors such as EMC provide proprietary mirroring and striping capabilities. EMC provides a similar technology to RAID 5 and RAID 0+1 known as RAID-S. Consider these types of capabilities if the storage vendors aren't offering the disk technology you're looking for (in other words, FCAL, SCSI-3, and so on).
From a database perspective, I/O rate is one of the biggest killers of database performance. Without getting into database fundamentals, the most important point I can make about databases and their system architecture is this: Distribute your I/O load! Whether you do this via a distributed database technology such as Oracle 9 i RAC or you simply lay out the database files on separate individual disks and then mirror and stripe them, it's imperative to do this from a high-performing database point of view.
Generally speaking, the further down the physical tiers you look, the more disk I/O is important. If I had to rate the importance of file I/O or, more specifically, disk I/O from Web tier to application server tier to database tier, the weighted requirement would be low for Web tier, medium for application server tier, and high for database tier . Also, don't be afraid to mix and match your disk technologies.
For this reason, for larger implementations, my preference is this:
-
Use onboard SCSI-based drives for thin Web servers (for example, Ultra160 or Wide Ultra 2).
-
For application servers where file I/O is at a medium level and only standard logging is taking place that's properly threaded, use SCSI-based disks such as Ultra160 or Wide Ultra 2 (and always mirrored and typically stripped),
-
Or use FCAL-based interfaces to external disk cabinets operating either native FCAL disks or higher-end SCSI-based disks such as SCSI3 or Ultra160 and Ultra320.
For the database tier, I always use the fastest possible disks available in the budget. Again, Ultra160 SCSI disks or FCAL technologies work well. Many of the bigger Unix vendors supply low-end systems with onboard FCAL connections and disks. The Sun V880 server supports up to 12 FCAL disks internal to the chassis. If it's only your database that requires high-speed disks, these servers make a great cost-effective alternative to having external storage cabinets.
The other points in the first question such as the concurrency of the file I/O and transfer size of the I/O are also important. In some cases, slower technologies such as ATA and NAS can provide fairly good I/O; however, if you're I/O size is high, then bus bandwidth can be a problem. If your application is requesting 800 I/Os per second yet the block transfer size is 32KB, then this would require approximately (not taking into account bus overhead and so on) 25MB per second of bandwidth.
Calculating Disk Performance: Disk Transfer Time
It's probably worth briefly explaining some calculations on disk I/O performance characteristics. I'll use the previous example to show how to do the calculations. You'll first want to select some disks. For the comparison, I've selected two disks from IBM (it's easy to find full disk specifications from IBM):
-
The first disk is a 34.2GB ATA-based disk with an average seek time of 9 milliseconds (ms), a track-to-track read time of 2.2ms, an average latency at 4.17ms, and 2MB of cache. The average transfer speed that this disk is capable of is 18.35MB per second.
-
The second disk is a 36.9GB SCSI-2 disk with an average seek time of 6.8ms, a track-to-track read time of 0.6ms, an average latency at 4.17ms, and 4MB of cache. The average transfer speed that this disk is capable of is 25.7MB per second.
These disks are a few years old and are provided as an example only. Both disks are also 7,200rpm.
The method to therefore calculate the time-to-transfer speed, based on 512KB worth of data, is to use an equation as follows :
[Seek time / Latency] + [512KB / Disk average transfer rate] = Time to transfer
Therefore, using these two disks, you can calculate that the transfer time for 512KB of data is as follows:
Disk 1: [9 / 4.17] + [512K / 18.35] = 30.05 milliseconds Disk 2: [6.8 / 4.17] + [512K / 25.7] = 21.55 milliseconds
You'll look at what happens if you add additional disks, but before you do that, you need to be sure the bus you've chosen can support the speed.
Calculating Disk Performance: Bus Bandwidth
Before looking at the impact of adding additional disks, you should know that adding additional disks alone won't always provide you with the increase in performance you might expect. There's obviously only a finite amount of bandwidth on your disk bus. Whether this is the system bus or the disk bus itself (SCSI, FCAL, ATA), there's always a limitation. Most of the time, the way to get around the limitation is to simply add another bus. For SCSI, FCAL, SAN, NAS, and iSCSI, it's relatively easy to add additional buses (just add another HBA!). However, with ATA and IDE, it's sometimes trickier. This is because standard main boards supporting ATA or SCSI only have four ports, and in the x86 world, each pair of IDE ports require a dedicated Interrupt Request (IRQ). With the x86 limitation on IRQs, you need to consider this if you're choosing IDE as your disk.
More recently, vendors have been bringing out expander and daughter boards in a variety of mixtures, where the daughter board (the non-onboard IDE controller) handles the IRQ masking for you, and you essentially use just one IRQ for the entire bank of IDE disks.
To calculate your bandwidth's performance, or the point at which x number of disks will saturate your disk bus, you can use the following equations. You have an idea of how long it takes one disk to transfer 512 kilobits (Kb) worth of data, so you can assume the following:
Transfer speed of 512KB = [ Transfer size / Transfer speed ] = Transfer rate
The calculation for the example is as follows:
Disk 1: = [ 512 / 30.05 ] = 17.04MB per second Disk 2: = [ 512 / 21.55 ] = 23.75MB per second
Now, if you wanted to understand what this equates to in terms of utilization of the two buses, ATA and SCSI, you'd use the following equation:
Bus utilization = [ Transfer rate for 512KB / Bus bandwidth ] = Utilization
Therefore, the calculation is as follows:
Disk 1: = [ 17.04 / 100 ] = 17% ATA bus utilization (ATA-100) Disk 2: = [ 23.75 / 80 ] = 29% SCSI-2 bus utilization (SCSI-2) = [ 23.75 / 160 ] = 14% Ultra160 bus utilization (Ultra 3/Ultra160)
It's important to note that these calculations are guides. There are other per-system factors that need to be included in the calculations if you're looking for a truly scientific outcome. However, what these results are saying is this:
-
ATA-100 has more bus bandwidth available than SCSI-2 (100MB per second versus 80MB per second).
-
A similarly sized SCSI disk with the same rotational speed is faster, transfer-wise, than an equivalent ATA disk.
Now you'll look at the effect of adding disks to your bus.
Calculating Disk Performance: The True Effects of Striping Disks
When you look to distribute load across many disks or spindles, you need to be careful that the total data transfer doesn't saturate the nominated bus. To calculate this, I'll assume you've deployed a WebSphere implementation and have noticed that a file system that's sitting on a particular disk, which houses WebSphere log files, is becoming overloaded.
You've decided you need to distribute the load better by striping two to three disks. The simple calculation you can assume is this: If that particular disk bus is doing nothing else other than handing the I/O associated with your log files, it's a matter of dividing the per-disk transfer speed and rate by the number of disks in the stripe set. I typically add 10 “15 percent overhead to this to account for the slight overhead associated with striping.
Note, however, that adding disks to perform striping doesn't decrease the bus utilization. Again, the simple calculation is to divide or multiple your I/O factor by the number of additional disks. If you're still transferring 512KB, but the 512KB of data is being sourced from a stripe over three disks instead of a single Just a Basic Old Disk (JBOD), the utilization of the bus still remains relatively the same. There will be a slight overhead of 5 percent per additional disk to counter for the additional bus-level commands of talking to three disks instead of one.
However, if one of your deployed applications got word that there was additional storage available and started to use the stripe set that housed your WebSphere log files, this would obviously affect your transfer rate and bus utilization.
For example, say another application started performing debug dumps on your newly created three disk stripe set, originally intended to house WebSphere logs. Being a debug dump, the I/O was fairly high and, as such, would frequently store 4KB of data to your stripe set.
The disk calculations would now look like this:
Disk 1: Transfer time = [9 / 4.17] + [512K + 64K / 18.35] = 31.38 milliseconds Disk 2: Transfer time = [6.8 / 4.17] + [512K + 64K / 25.7] = 22.41 milliseconds
Then, to understand the transfer rate over time, you calculate this:
Disk 1: Transfer rate = [ 512 + 64 / 31.38 ] = 18.35MB/s Disk 2: Transfer rate = [ 512 + 64 / 22.41 ] = 25.70MB/s
This is the calculation for the bus utilization:
Bus utilization = [ Transfer rate for 512KB + 64KB / Bus bandwidth ] = Utilization Disk 1: = [ 18.35 / 100 ] + 5% = 23.35% ATA bus utilization (ATA-100) Disk 2: = [ 25.70 / 80 ] + 5% = 37.12% SCSI-2 bus utilization (SCSI-2) = [ 25.70 / 160 ] + 5% = 21.06% Ultra160 bus utilization (Ultra160)
As you can see, the additional 64KB of data doesn't produce a massive amount of overhead; however, it's increasing. Furthermore, 512KB of data isn't a large amount ”consider the same calculations if your application server is handling large files in excess of a megabyte.
What all this means is that although technologies such as SCSI and FCAL support quite a number of disk, all having them operate on a singular bus can lead to bus saturation.
Storage Technology: Cost
Cost is always a major driver of any architecture. This is unfortunate but true, and WebSphere implementations are no different. From a storage cost perspective, there's vast difference between costs for an ATA-based implementation versus something such as a SAN or Fibre Channel implementation.
In the IT world, fast is best, and best costs. For storage, the costs of your chosen architecture should be driven by the technology ”that is, what technology bests fits your implementation needs as determined by capacity planning and systems engineering? Then you need to look at the cost of the preferred storage technologies.
As explored in Chapter 2, Total Cost of Ownership (TCO) is a good measure of a technology's total cost. This will, or should, include items such as management and support costs of the technology, implementation costs, upgrade and scalability costs, and technology availability costs.
You'll now look at those in some more detail.
Management and Support Costs
Supporting any technology will cost money. Depending on the technology, the support costs will differ . There are several reasons for this, but generally the more complex the technology is, the more specialized the support services are. This drives up support costs. Complexity ”and managing it ”further increases costs.
For this reason, the supporting costs of ATA-133 disks in a lower-end WebSphere server will undoubtedly cost less to support and manage than that of a storage cabinet running Fibre Channel disks. Figure 4-6 shows the support costs associated with the storage technologies covered.
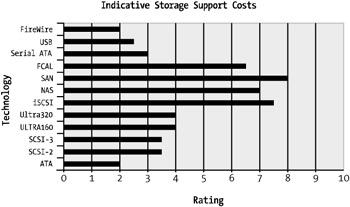
Figure 4-6: Storage support costs
As you can see, the NAS, SAN, and iSCSI implementations are the most costly to support and manage. However, they're among the fastest of the disk storage technologies (refer to Figure 4-5). That said, as enterprise storage solutions such as SAN grow within an organization, the costs for support decrease steadily over time while the SAN's storage "mass," or size, increases.
Implementation Costs
The costs associated with implementation are also driven by the complexity of the technology. SAN and FCAL are examples of this. Closely followed behind these two flagship disk technologies, SCSI, NAS, and iSCSI are the next most costly of storage technologies to implement.
The implementation costs driven by the technology complexity are caused by the size of the implementation. That is, it's rare for anyone to install mission-critical WebSphere servers requiring high storage I/O throughput to use ATA-based disks.
The implementation costs consist of design and architecture costs and physical deployment and configuration costs that include personnel and resources. The more complex the technology, the more costly the resources will be. Figure 4-7 shows the costs associated with the implementation of the storage technologies discussed.
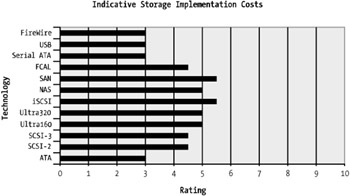
Figure 4-7: Storage implementation costs
The distributed storage technologies such as NAS, SAN, and iSCSI incur the highest implementation costs. Point-to-point implementations are typically the least costly to implement.
It's important to note that these implementation costs assume a new installation. If the tables were turned and the example WebSphere environment was being plugged into existing NAS, SAN, or iSCSI storage fabric, the implementation costs would be greatly reduced for these technologies.
In summary, if your organization is using something such as an enterprise SAN or a preexisting Fibre Channel storage farm, the majority of the implementation costs are already covered, and therefore the implementation costs will be closer to that of SCSI, ATA, and other simpler storage technologies. This is pre-dominately because you'll be initiating an additional connection to an existing enterprise storage solution.
Upgrade and Scalability Costs
A sometimes hidden cost in the selection of a technology is the future upgradeability and scalability costs. If, for example, you select an ATA disk-based storage technology that's typically limited to a small number (typically fewer than six) of interfaces, and you need to upgrade to additional disks, you'll find that there may not be enough interfaces for you to add disks.
Although there may be other solutions to get around this problem (daughter board IDE controllers and so on), it does illustrate the need for scalability.
What about your prized high-performing proprietary FCAL-based disk cabinet? It may come with 100 FCAL bays for storage, but exceeding 100 disks may require the purchase of another external disk storage cabinet. This increases costs for the physical cabinet purchase itself (sometimes 70 “80 percent of the total solution cost), and you'll incur other costs incurred such as feed and water (for example, power, air conditioning, and so on). You'll need to know whether it would've been cheaper to go Ultra160 SCSI and take the hit on the SCSI bus overhead when connecting vast numbers of drives to a host system.
Storage Technology: Architectural Complexity
As mentioned in the previous section, architectural complexity is an important factor in the selection of the storage technology choice. Although it shouldn't be the most important aspect of your selection, you need to be mindful of it.
Storage Technology Summary
In summary, the storage technology you choose for your WebSphere system architecture should be based on an as-needed basis. That is, don't get FCAL for an implementation if you don't think there will be much in the way of high I/O. Of course, consider something such as high-end SCSI or FCAL for your database server tier. However, unless your applications running within WebSphere are regularly writing or reading data to disk, the lower-end disk technologies will suffice.
Network Controllers and Interfaces
Networking is another of the key components of a WebSphere environment ”one that can break or make the performance or availability Service Level Agreements (SLAs) of an application. WebSphere, like any network or distributed-type application environment, benefits greatly from fast, robust, and resilient networking architectures.
I've found you can break down WebSphere networking requirements into three sections:
-
WebSphere cluster networking (node-to-node communications)
-
WebSphere-to-database (repository) networking
-
WebSphere-to-customer (or frontend Web server) networking
You must carefully plan, design, and implement each of these requirements for your WebSphere application environment to operate within nominal performance boundaries. The design should also incorporate availability as a requirement.
You'll now take a look at these three key points in more detail.
| Note | in the next chapter, I discuss WebSphere topologies in detail. Topologies typically involve network design, so the following sections act as an overview. |
WebSphere Cluster Networking
This is a topic that won't apply to you if you're operating a small or lower-end WebSphere environment where you're running a single WebSphere application server node. If, however, you're operating a multinode or multiapplication server WebSphere environment, this will be of importance to you.
Like many J2EE application servers, WebSphere will communicate between application servers for a variety of items. This includes things such as a distributed JNDI tree or data replication (for WebSphere 5+). You may also have internal application communications between nodes for some form of higher-level load balancing. This type of application design will also be affected by slow or high-latency networking infrastructure.
So what does this type of networking requirement entail? I highly recommend you have two WebSphere application server nodes connected via some sort of medium. For availability reasons, you may have these two WebSphere application servers located in different cities approximately 1,000 kilometers, or 620 or so miles, away from one another. Because of this distance, there's an increased latency overhead associated with networking, and depending on the type of networking technology you use between your WebSphere nodes, this may be an unworkable design.
For example, if you were to use a 56Kbps modem to communicate between the two nodes, your latency would be approximately 240ms. Putting aside the fact that 56Kbps wouldn't be able to handle the amount of traffic that would be generated between two WebSphere nodes, the response time your users and customers would experience with the application would be atrocious.
| Note | Don't use satellite (which I've seen being used before!) for this because it too has a high-latency factor associated with it. If you're distributing your WebSphere nodes apart from each other, use the fastest, least overhead technology you can afford. |
You could use ATM, Packet over SONET (PoS), SONET, Frame Relay with a decent Committed Information Rate (CIR), or Digital Data Service (DDS), or, in a pinch , you could use a Virtual Private Network (VPN) over the Internet if your last-mile connections to your Internet Service Provider (ISP) were fast enough and your ISP had sufficiently large and well-performing internal network links.
If you're locating your servers together, then your task is far easier.
Look at using Gigabit Ethernet for the internal connections, even if you don't think you'll come close to using 1Gbps of bandwidth; the low latency of Gigabit Ethernet makes it a good choice.
Further, 100Mb per second Ethernet has a fairly good latency measure against it and is also fine for the role. However, capacity plan your requirements ”if your 100Mb per second becomes overutilized by internal application-to-application or WebSphere-to-WebSphere traffic, you'll quickly see the latency increase.
These days, you can pick up Gigabit Ethernet interface cards for most systems fairly cheaply. Even if you build a point-to-point network (in other words, direct server to server) and use a standard switching network topology for a backup, this will be a low-cost solution.
In later chapters, you'll learn about the tuning of these interconnection links. Depending on your requirements, different TCP settings on your WebSphere hosts can make a big difference to the overall performance.
WebSphere-to-Database Networking
If you're operating a WebSphere 4 platform with a repository or if your applications are using a database for application data, this part of your WebSphere networking environment is critical from a proper network design point of view.
Database communications via something such as JDBC typically follow a fairly random characteristic in terms of size and frequency of the requests. That is, you may have a burst of small queries going to the database from the applications and small result sets. On the other hand, you may have a mixed bag of big and small result sets and few and many queries.
Either way, this part of your WebSphere environment can cause headaches for your users if it's not designed correctly.
Some basic recommendations, and ones I'll cover in more detail in later chapters, are as follows.
Redundancy Paths
Always have redundancy paths from the WebSphere tier to the database server tier. This may be via basic level 2 or 3 load balancing (or switching) or could be something such as the Solaris IPMP (IP Multipathing) software. Apart from a gain in performance (through a possible decrease in latency), this redundant path will result in higher availability.
At worst, for larger environments, use two links from each WebSphere server with different weighted metric values for each interface. This way, if one link goes down, a secondary link is available.
Number of Application Servers
Ensure that the sum of all WebSphere application servers connections don't flood a single database server connection. That is, be mindful of how many WebSphere application servers you have interfacing with the database server. It may be worthwhile, based on your capacity modeling, to have the database server hooked into a switch at gigabit speed and the WebSphere application servers all interfacing to the network at 100Mbps. This will ensure that any one WebSphere application server can't flood the network to the database server with requests should the application become unstable.
If you're using the connection pool manager within WebSphere (which I'll discuss in later chapters), the probability of this occurring will be reduced. However, for good practice, follow this rule.
Location of Application Servers
Locate your database server or cluster physically near your application servers. The purpose of this is to reduce latency. If you're looking to gain some form of disaster recovery, my recommendation isn't to locate the database tier any farther away than 200 kilometers. This will only increase your latency by a number of milliseconds, as opposed to 20 “30ms for a digital line extending 1,000 kilometers.
Database Server Node
Don't try to gain performance from housing your database server on the same node as your WebSphere application server. Albeit not purely a networking issue, housing the database on the same server as the WebSphere engine itself will gain you some performance because of communications going via the local host interface as opposed to out on the wire. However, you'll find that the load and characteristic of the database server on the same node as the WebSphere engine will cancel out most performance architecture you've included as part of your server design.
Unless either your database server requirements are exceptionally small or you have large application servers, steer clear from this topology.
WebSphere-to-Customer (or Web Server) Networking
Given the nature of the traffic generated by the WebSphere HTTP plug-in sitting on the frontend Web servers, you'll find that a high-performing network architecture between the HTTP servers and WebSphere backend will ensure a fast-responding application.
The WebSphere HTTP plug-in talks to the WebSphere backend via HTTP. If you were to look and monitor the traffic exiting from the Web server and destined for the WebSphere engine, you'd see that it's all simple HTTP commands.
Given that your application will, like most HTTP/HTML interfaces, be made up of many components (GIFs, JPEGs, text, frames , and so on), each element that makes up the output on the customers browser will result in additional HTTP requests to the backend. The more elements that make up your output, the more individual requests that will be requested to the WebSphere server.
For this reason, you'll find that traffic quickly increases as customer load increases. Complex user interfaces can be made up of 100 elements; if there are 500 users online, each averaging several page clicks per second, the transaction rate will be quite high.
If the individual requests are delayed because of the latency issue, then the perceived performance of the application will grind to a halt.
Ensure that the link between your Web tier and backend tier is high speed ”at least 100MB is recommended; for redundancy and potentially performance, consider multiple links and routes.
Because the HTTP server will probably be located within a firewall environment, consider the additional latency overhead introduced on the wire transaction by elements such as firewall devices, switches, and routers.
Again, you'll investigate topologies in the next chapter; however, if you're geographically locating your HTTP and WebSphere servers, consider the overhead and traffic requirements associated with delivering HTTP payload over a wide-area infrastructure.
In summary, it's important that your networking infrastructure in this zone of your topology supports a high request rate ”in other words, the lower the latency, the better the overall performance.
EAN: 2147483647
Pages: 111