Scalability and Availability: A Primer
You deploy a WebSphere implementation in order to provide application services to users or business partners . Whether it's a Java thick client, a Business-to-Business (B2B) Web Service architecture, or just a simple Web-based Hypertext Markup Language (HTML) interface, the purpose of a WebSphere application is to serve.
Internet banking, e-commerce, package tracking, and online airline ticketing are all examples of products that WebSphere can serve. As you can appreciate, not all of these services will require large amounts of availability. Furthermore, not all of them will require vast amounts of spare resources or the ability to grow and scale. Of availability and scalability, scalability tends to be an issue (or a design and architectural consideration) for the medium to long term, and availability tends to be an issue for your WebSphere application environment in the short term .
Availability, or resiliency , is something that's attributable to how you configure and architect your WebSphere environment (which is why I discuss best practices in detail in Chapter 6). Further, a well-designed, highly available WebSphere platform can actually insulate poorly designed or poorly developed application code. Imagine application code running on a single server (low availability) and a single Java Virtual Machine (JVM) (low scalability) that's buggy and continues to crash.
You could send the code back to the developers, but as you probably know, this can take time and be costly. If your original WebSphere topological architecture has multiple servers or multiple application servers (hence using multiple JVMs), you can insulate, to a degree, bad application code. Of course, if the code is really bad and the JVMs are constantly crashing and restarting, this will undoubtedly affect performance.
It's an age-old question: How much hardware do you add to ensure that your application environment is highly available? There's a point where purchasing more and more hardware to cater for poorly written or designed application code becomes more expensive than changing the code! I'll come back to this later in the chapter.
Scalability: What Is It?
Scalability is the ability of a system to grow, either driven by changes to functionality or technical requirements or driven by organic growth (for example, an increase in registered users over time). When I talk about scalability, you might first think of hardware and infrastructure. Typically, the raw processing power, memory, disk, and network capacity determines how scalable a WebSphere application platform is.
For an application to scale, generally the overall platform housing the application must be able to continue operating under a peak load (or a spike), as well as be able to grow organically as general usage increases over time. What you want to avoid is having to upgrade or alter your topological architecture and your application design every three months to satisfy growth.
On the flip side of hardware, you have software. Software is just as tangible as hardware when it comes to scalability. A classic example of software scalability is a 32-bit platform-specific limitation. In most cases, a 32-bit limitation inhibits memory allocation or file size allocation higher than approximately 2GB. Therefore, you'd need to consider specific platform architectural designs when scaling higher than 2GB for file sizes and memory allocations .
Additional software bounds further limit maximum file and file system sizes, memory allocation sizes, and so forth. For example, most 32-bit JVMs on 32-bit operating systems support up to 2GB of memory heap size. If your environment requires more than 2GB of memory per Java process, then you'll need to go to a 64-bit JVM (64-bit JVMs are in their infancy and only just becoming available) or vertically scale your application architecture by using multiple JVMs (discussed in Chapters 4 and 5).
| Note | The 2GB limit is the upper bound of the JVM heap size. However, other factors within your operating system and platform will constrain your maximum heap to less than the maximum of 2GB. |
In Chapter 5, you'll learn about topological architectures. In that chapter, you'll explore the ways to make your topology scalable so that you can cost-effectively grow your WebSphere environment, with little or no redesign.
Availability: What Is It?
Availability is the measure of a system's or application's processing capability over time. In the case of a WebSphere implementation, this relates directly to how available the WebSphere-managed Java 2 Enterprise Edition (J2EE) application is to users. Simply put, you can model WebSphere availability as follows :
-
WA =
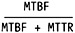
What this says is that WebSphere Availability (WA) is the measure of the Mean Time Between Failure (MTBF), which is then divided by the sum of the Mean Time Between Failure (MTBF) and the Mean Time to Repair (MTTR).
| Note | There are entire books available on the science of availability; as such, an in-depth explanation of availability is beyond the scope of this book. However, what I do cover in this chapter, and in context within later chapters, is how to understand what availability levels you require. |
Availability is a critical key performance indicator for applications. The key to achieving availability is to design and develop good, solid applications, as well as to architect a battle-proven WebSphere-based topological architecture. As such, when measuring availability, there are some important facts to understand.
First, the sum of your overall WebSphere availability is only as good as the mean of the lowest availability component. That is, if you have a WebSphere server cluster with four nodes yet all four nodes are running off the same single power supply that's rated as only having 99.5-percent availability, then all the servers in the world won't provide you with greater than 99.9-percent availability.
At the same time, the more components you have in your environment, the greater chance there is of a component failing. Consider a system with two hard disks, with each hard disk having 100,000 MTBF. This is roughly 11 years of MTBF for each disk; however, as a whole system, you'll have an MTBF on your disks of 100,000 hours divided by 2 (two disks). Similarly, if you have a large system with, say, 200 disks, then the MTBF will decrease to 100,000 divided by 200 ”or, 500 hours. This equates to approximately one disk failure every 21 days.
Understanding the Business Availability Index
Before actually looking at availability measurements, you'll now consider availability from a risk management and business point of view.
It's possible to break down availability, from an organizational perspective, into five groups. Each group progressively involves more cost, is driven by more management attention, and overall receives more focus from budgetary issues and ultimately customer impact. The five progressive levels of redundancy in an organization are as follows:
-
No redundancy
-
Data redundancy
-
System redundancy
-
People redundancy
-
Organizational redundancy
Many Computer Science and Business Information Systems university programs teach this model in a common four-step process; what they tend to omit is the fourth point, people. It's great to have a whiz-bang, highly availability WebSphere implementation, but if your key person who knows 95 percent of the system leaves , then your impressive WebSphere cluster can quickly become nothing more than a Christmas tree decoration!
The following sections briefly describe each of the levels in what I call the business availability index .
Understanding Level 1: No Redundancy
No redundancy is just that. This level may include rudimentary forms of configuration backup, but essentially a level 1 redundant implementation is a potential disaster waiting to happen. Then again, as you'll see in later chapters, having this level of redundancy may just be all your organization needs.
If, however, you're operating a WebSphere-based implementation that's important or critical to your clients or business needs, then consider levels 2 “4.
Understanding Level 2: Data Redundancy
Data redundancy starts to use online or near-online mirrored and redundant data storage technologies. This may be as simple as plain RAID 1 mirroring or something more "exotic" as RAID 5, RAID-S, or some other form of data replication.
It doesn't include replication of data between other hosts because this falls under level 3 redundancy.
Understanding Level 3: System Redundancy
System redundancy refers to multiple load-balanced or hot-standby/failover servers. This is the first availability level you should consider for critical systems. Level 3 relates to all server tiers within a WebSphere environment such as Web servers, database servers, application servers, and other legacy-based systems.
Understanding Level 4: People Redundancy
People redundancy isn't when you're laying off staffers but instead is when you're following some sort of proactive knowledge exchange and skills-transfer program. Similar to some of the concepts from the Extreme Programming (XP) methodology where all development is championed by two people at a time (side by side), this includes daily "handovers," daily knowledge and technology briefings, and so forth. Rotate roles and staff to ensure that all team members get exposure to all aspects of your environment so that when someone leaves your organization, then you're covered and not left standing with a WebSphere-based platform without any experienced employees .
Understanding Level 5: Organization Redundancy
Organization redundancy is all about disaster recovery. If your environment is mission or business critical, this level of redundancy is paramount. It includes active dual-site implementations , hot-standby disaster-recovery configurations, and all forms of data and service replication between two or more sites. This is by far the most complex and expensive of the redundancy levels.
Matching Business Availability with Percentage Availability
To achieve a certain percentage of availability, your application must match one of the previous levels of redundancy. Table 2-1 gives you an overview of common availability percentages, with the corresponding business availability index level.
| Availability Percentage | Business Availability Index |
|---|---|
| 98 percent | Level 1 |
| 99 percent | Levels 2 “3 |
| 99.8 percent | Level 3 |
| 99.9 percent | Levels 3 “4 |
| 99.99 percent | Level 5 |
| 99.999 percent | Level 5 |
| 99.9999 percent | Level 5 |
Table 2-1 quite clearly shows how the various business availability index levels match up against the availability percentages. For example, if you require 99.99 percent or greater availability, you need to ensure that your operational effectiveness is at level 4 or 5. You can use this table as a guide to ensure that you're matching availability expectations with the correct level of attention.
Understanding the Availability Matrix
The result of availability is measured by a percentage of uptime , which is service availability to users. This section describes what it means to be able to provide high levels of availability and what the percentages of availability really mean.
Table 2-2 lists commonly represented availability measurements and their associated downtime per year and per month, depending on how you measure them.
| Availability Percentage | Yearly Downtime | Monthly Downtime |
|---|---|---|
| 98 percent | 7.3 days | 14 hours, 36 minutes |
| 99 percent | 3.65 days | 7 hours, 18 minutes |
| 99.8 percent | 17 hours, 30 minutes | 1 hour , 28 minutes |
| 99.9 percent | 8 hours, 45 minutes | 43 minutes, 48 seconds |
| 99.99 percent | 52.5 minutes | 4 minutes, 23 seconds |
| 99.999 percent | 5.25 minutes | 26.2 seconds |
| 99.9999 percent | 31.5 seconds | 2.6 seconds |
As you can see, as you approach 99.9999-percent availability, the reasonability of this guarantee becomes less and less likely. It's practically impossible to achieve annual availability of 99.9999 percent. However, you can achieve 99.99-percent availability, and even 99.999-percent availability, with a correctly architected WebSphere implementation. The bottom line is that you simply can't guarantee these availability metrics with a single WebSphere platform channel or single- tier application environment. (You'll explore this in more detail in Chapter 5.)
This isn't to say that a system may not be able to meet these availability percentages. That's far from the case. I've seen servers up and available for close to two years without reboots or application failures. Although these systems aren't mission critical, they do serve important purposes in organizations.
| Caution | Over the years I've witnessed much "chest beating " regarding uptime measurements of servers. Although it's great to know that various operating systems can provide constant availability, never put pride of availability in front of security and bug fixes! And remember, it's not always server availability that's important ”it's user -facing or client- facing availability that's key. |
Understanding WebSphere Availability
What are the typical or more common causes of downtime for a WebSphere-based platform? There are several key and somewhat obvious ones, but it's important to understand areas of the platform that are susceptible to outages. Table 2-3 lists the key areas within a WebSphere environment that are susceptible to failures and the likelihood of them occurring.
| Area of Impact | Estimated Percentage |
|---|---|
| Human/operator error | 35 percent |
| Software failures | 40 percent |
| System and environment failures | 25 percent |
As you can see, outages aren't caused only by software (both infrastructure software and application software) and hardware. Many different reports and estimates present the causes of downtime; more often than not, the biggest availability killer is first the software, then the infrastructure and environment, and then people errors.
These areas break down even further; for instance, software failures consist of 85-percent application software and 15-percent infrastructure software (for example, WebSphere, operating systems, and so on). In any light, it's possible to mitigate these areas of risk by employing a well-designed and well-architected WebSphere environment.
But what causes WebSphere downtime? Table 2-4 lists various aspects of a WebSphere-based environment that can cause downtime when they fail. It's important to note that the Likelihood column refers to the chance or likelihood of the impact event occurring. The Overall Impact column refers to the damage done from the impact event. Small indicates that the impact event will generally not cause an outage, Medium indicates it may cause an outage (for example, a partial disruption), and High indicates it may cause the entire system to fail.
| Impact Event | Likelihood | Overall Impact | Mitigation |
|---|---|---|---|
| Disk failures (system) | Medium | Medium | Use redundant or mirrored disk(s) and arrays. |
| Memory failure | Low | High | Depending on platform type, use hot-swappable memory or multiple servers. |
| CPU failure | Low | High | Depending on platform type, use hot-swappable CPUs or multiple servers. |
| Network interface failure | Low | Medium | Use redundant network interface cards with redundant routes. |
| Network infrastructure failure | Low | High | Use redundant network infrastructure (switches, hubs, and so on). |
| Application database failure | Low | High | Use database clusters, High Availability (HA) clusters, or hot-standby databases. |
| WebSphere 4 repository failure | Low | Medium | Use database clusters, HA clusters, or hot-standby databases. |
| WebSphere repository corruption | Low | Medium | Split WebSphere domains and cells . |
| Denial of Service (DoS) attack | Medium | High | Employ firewalls and split WebSphere domains and cells. |
| WebSphere administrative server failure | Low | Medium | Split WebSphere domains and cells with redundant servers. |
| Incorrectly installed application software | Medium to High | High | Split WebSphere domains and cells with redundant servers and deploy to one domain or cell at a time (and test!). |
| WebSphere configuration error | Medium to High | High | Split WebSphere domains and cells with redundant servers to minimize environment cascade failure. |
| Application software failure/crashing | Medium to High | High | Split WebSphere clones , domains, and cells with redundant servers. |
| Web server failure | Low | High | Employ redundant Web servers. |
| Main power failure | Medium | High | Use multiple power supplies with multiple main suppliers for large systems and or use uninterruptible power supplies and generators. |
| Environment/air-conditioning failure | Low to Medium | Medium | Physically distribute your WebSphere and backend application servers. |
| Security breach | Low to Medium | High | Split domains and cells with redundant servers, split firewall environments (consider virtual local area networks), and use different passwords for all hosts. |
| System crash and failed backups | Low to Medium | High | Take duplicate regular dumps of WebSphere configuration (for example, use compressed installedApps directories after each new deployment to preserve production-deployed application code). |
| Environment peak load performance problems | Medium | High | Consider updating or increasing servers and consider distributing your different load types to separate servers. |
Table 2-4 is in no way an exhaustive list of potential availability killers, but it should give you an indication of what can go wrong and some potential mitigation strategies. If some of the concepts mentioned in Table 2-4 are new to you, don't be concerned at this point; you can come back to this table as you go through the rest of the book. Specifically, Chapters 5 through 8 explore a lot of the availability concepts mentioned in Table 2-4; I'll explain each of them from an implementation and design point of view.
At this stage, if you're planning your WebSphere implementation and topological architecture, use Table 2-4 as a checklist of items to consider.
Overall, WebSphere is a complex beast , and its operational effectiveness is determined by numerous aspects of an operational environment, including infrastructure (both software and hardware), environmental factors, people, and process factors.
EAN: 2147483647
Pages: 111
- Step 1.1 Install OpenSSH to Replace the Remote Access Protocols with Encrypted Versions
- Step 1.2 Install SSH Windows Clients to Access Remote Machines Securely
- Step 3.2 Use PuTTY / plink as a Command Line Replacement for telnet / rlogin
- Step 4.3 How to Generate a Key Pair Using OpenSSH
- Step 4.4 How to Generate a Key Using PuTTY