What Constitutes a Performance Improvement?
What Constitutes a Performance Improvement?
This is one of those questions that has been argued since the dawn of computing! You can view a performance improvement and what constitutes one in many ways. The following are some of the key indicators that can be attributed to or deemed as performance improvements within a WebSphere implementation:
-
A decrease in perceived user or customer application response time (in other words, a decrease in wait time between transactions).
-
The ability for the "system" to handle more users or customers (in other words, volume increase).
-
A decrease in operational costs associated with either or both of the previous points.
-
An ability to scale down infrastructure (or consolidate) because of the higher performance of the application on a lesser-powerful infrastructure.
-
The bottom line if Business-to-Business (B2B) activity in any given period will have a direct effect on the revenue-generating capability of the application or system (this typically is connected with the second point).
Although this isn't an exhaustive list, it provides an overview of some of the more obvious and tangible benefits that can be derived from a tuning and optimization strategy.
You'll now explore each of these points in a little more detail.
Decrease in Perceived User or Customer Response Time
A decrease in the perceived user or customer response time is the most obvious of performance improvements. As a system and application management expert, you're exposed to all those calls from users or customers who are complaining of poor or substandard application response times.
Although on many occasions this can be because of problems outside the bounds of your control (for example, the many hops and intermediate service provider pops between you and the remote Internet site), a fair degree of an application's performance is within your control. Some key components within WebSphere that directly affect performance (and are tunable) are as follows :
-
Queues: Web server, Web container, database datasource, and Enterprise JavaBean (EJB) container
-
Threads: The availability and utilization of them
-
Database: Java Database Connectivity (JDBC) pool, Structured Query Language (SQL) statement controls, and the database itself
-
Transaction management: The depth of your transaction containment and so on
-
The Java Virtual Machine (JVM): Garbage collection, utilization of Java objects within the JVM, and general JVM properties
I'll discuss each of these components ”and more ”during their respective chapters later in the book. However, these five areas are where you'll focus a fair degree of effort for performance management. Proper tuning and capacity management of these aspects of WebSphere can literally make or break a system's performance, and a little tuning here and a little tuning there of things such as JVM settings and transaction management can increase or decrease performance by more than 100 percent in no time.
Combine this with how well your platform and applications utilize the database pooled connections, Java objects, and other areas of WebSphere such as data and session persistence ”and then throw in a well-thought-through methodology ”and you can achieve a more than 200-percent improvement in application response time on a poorly performing system.
| Note | I recently was involved with some performance tuning work associated with a WebSphere 4.02 platform that presented customer invoices online. The response time goal for the application was to have 95 percent of all transactions completed ”in other words, backend transactions complete, Hypertext Transfer Protocol (HTTP) transfer to customer commenced ”in less than five seconds. Initial testing was showing average response times of 17 seconds, which was a concern. I'll use this example as a case study later in the book; however, after incorporating a performance methodology into the analysis effort and tuning the environment based on this methodology, the response times came down to between four and six seconds per transaction, which was deemed acceptable. The moral is that the sooner you can implement a performance methodology, the faster and more effectively you'll be able to resolve performance problems. |
Performance management is a time-consuming process; however, its rewards are high. Given this, it justifies working closely with developers to ensure they're writing code that not only functions according to business requirements but also is written with an operations architecture best-practice mindset.
In summary, time well spent brings large rewards: Do the research, do the analysis, and spend the effort. Follow these three mottos, and you'll see positive returns.
Ability for the System to Handle More Users
When a system manager is propositioned to scale up his or her platform to cope with "y" number of additional users, there are two schools of thought people tend to follow; one is mostly wrong, and one is mostly right.
At first thought, being given a requirement to scale a system up "x" fold to accept more customers is typically met with additional processors, memory, and or physical systems. It's the old vertical versus horizontal scaling question. Where this school of thought is mostly wrong (and I'll explain why it's mostly wrong shortly) is that, with the right tuning and optimization approach, you can substantially increase the life of a system without an upgrade (within fair boundaries).
Before you balk and say that's crazy, I need to point out this only works for reasonably sized increments of load. What constitutes reasonable is driven by the nature and characteristics of the application. I've seen a system architecture implemented for a baseline set of users and the call being made to be able to ensure that it'll cope with nearly three times the original load. Tuning and optimization of the platform made this reality.
That said, with the decreasing costs of hardware from IT server vendors , it may in fact be less expensive to purchase more memory or additional Host Bus Adaptors (HBAs) than to perform a thorough review on the application or environment. This can definitely be the case for the midsize upgrades; however, keep in mind that midsize upgrades come in pairs and trios. Therefore, no doubt in the near future, your stakeholders will approach you requiring additional increases in customer load for another functional or capability change. If you get the impression that you can just keep squeezing more and more out of your system by simply purchasing additional hardware, you'll end up painting yourself into a corner.
What I'm trying to say is this: Hardware upgrades aren't always required for additional load of increased performance. In fact, for two out of three situations, hardware upgrades won't be required for additional load or capability enhancements.
Figure 1-5 breaks down the associated costs for an example platform where an increase in hardware has increased support and maintenance costs to provide a two-fold increase in processing capacity.
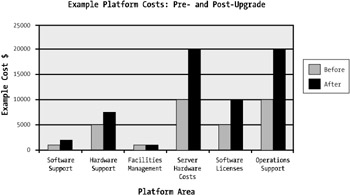
Figure 1-5: Pre- and post-upgrade support costs for an example platform
As depicted in Figure 1-5, the increase in hardware has increased the overall support, maintenance, and license costs for this platform. Because the WebSphere environment hasn't been optimized or hasn't been optimized correctly, the "bang for buck" in dollars per additional transaction is lower.
Figure 1-6, however, shows what can be done in the opposite situation. If a system is optimized correctly, the cost benefit ratio is high. Both these figures are fictitious but do represent the benefits associated with JVM tuning and proper configuration.
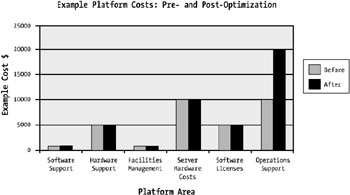
Figure 1-6: Pre- and post-upgrade support costs for an example platform, the optimized approach
As shown in Figure 1-6, the dollar cost per transaction greatly decreases with optimization, and at the same the time, the overall operational costs associated with the platform remain unchanged.
It's important to understand that the same can be said for the opposite. If you get the impression that "a tweak here and a twist there" can give your business customer a 500-percent increase of application load or performance ”without hardware increases ”then this can also paint you into a corner.
Setting expectations and providing a clear outline of your methodology and process for the ongoing life cycle of the system, and its application constituents, is critical to your role as an application or system manager.
Decrease in Operational Costs
Operational costs associated with poor or low application performance are one of those financial burdens that, over time, add up and can suck an IT budget dry. Operational costs are typically associated with management and support, the system's "food and water," and ancillary items such as backup tapes, software concurrency, and the like.
A low-performing application that requires heightened management and support because of increased customer inquiries and support calls, additional system "baby sitting," a reduced ability to perform support tasks during operational hours, and so forth will incur costs at a fairly rapid rate. It can be a " slippery slope" under these conditions, and only through proper risk and program management does a system or application in such poor shape survive.
Figure 1-7 indicates the costs involved in an operational budget for a medium-sized WebSphere environment operating on a four-CPU Unix platform with dual WebSphere application servers.
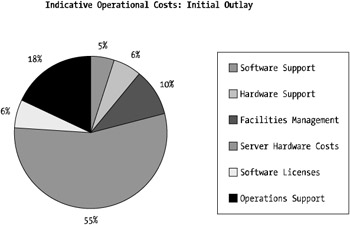
Figure 1-7: Indicative operational costs, initial outlay
The largest of all cost components in Figure 1-7 is the infrastructure costs, followed by license costs. This breakdown assumes a zero-year horizon on the cost outlays (in other words, upfront cost prior to development).
If you look one year into the future, the most significant costs are the maintenance, support, and licensing costs. Maintenance and support as well as ongoing licensing costs are usually driven by the size and hardware platform you're using. Most vendors work on a license and maintenance agreement where the number of CPUs used in your environment drives the total cost.
You can probably see where this is heading ”if you have a well-optimized environment with less hardware, your maintenance costs are reduced and so are your license costs.
In summary, a high-performing application will require less support and baby sitting. Operational tasks can be completed during standard operational hours, and support calls regarding performance and slow response times will be minimized, which reduces the head count for support staff, which in turn directly affects operational support costs.
Ability to Scale Down Infrastructure with an Optimized WebSphere Environment
A system's "food and water" ”power, cooling, and hardware maintenance ”can also be reduced through WebSphere application optimization and tuning. If fewer physical systems are required, food and water costs are reduced.
This is an important factor in obtaining funding for performance optimization and tuning tasks. As you'll see in the next section, sometimes selling the concept of an optimization and tuning program to business stakeholders (those who hold the strings to the money bag!) is difficult. Unless you reduce the true bottom line costs and can prove that through a structured and clear methodology, these stakeholders will not lay out the funds.
By clearly showing you can reduce operational expenditure costs (by reducing the number of servers, which means less support and management costs), you can easily sell the operational and application optimization and tuning efforts.
The Business Bottom Line
Although some of these points about a businesses bottom line and cost analysis are all somewhat "motherhood and apple pie," the number of installations and environments that can't or won't see the benefits of tuning and optimization is amazing.
Technical people will typically see the benefits from a better-performing system and application. Business people need to see the advantages from a bottom line perspective, and unless you can sell these conclusively, then your optimization plan ”or more precisely, its benefits ”needs more work.
In some situations, if an application has a transaction response time of ten seconds and the business representatives and customers are happy, do you need to optimize the system further? Unless optimizing the platform will provide a drastic reduction in infrastructure (and all associated costs), then "if it ain't broke, don't fix it."
| Note | I'm sure we've all faced the opposite of this, which is where a stakeholder or business representative demands unachievable performance requirements such as ensuring that 95 percent of all transactions to and from an IBM OS/390 mainframe complete in less than one second! |
Essentially, one of the key aims of this book ”other than how to optimize ”is to attempt to show the business benefits of optimizing and tuning WebSphere. Many readers may already be at the point of having identified the benefits of optimization and even having the concept sold to business sponsors. Possibly, you may now need to know how and what to do to execute the optimization and tuning efforts.
Either way, by reading and using this book, you should be able to build and complete your WebSphere optimization and tuning strategy.
EAN: 2147483647
Pages: 111