Chapter 3: Designing a Data Warehouse
|
| < Day Day Up > |
|
Overview of Warehouse Design
The following figure shows how SAS ETL Studio is used to flow data into and out of a central data warehouse.
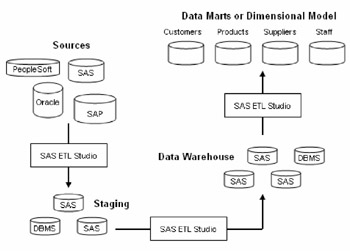
Figure 3.1: Best Practice Data Warehouse
In this model, SAS ETL Studio jobs are used to perform the following tasks:
-
Extract enterprise data into a staging area.
-
Cleanse and validate data and load a central data warehouse.
-
Populate a data mart or dimensional model that provides collections of data from across the enterprise.
Each step of the enterprise data model is implemented by multiple jobs in SAS ETL Studio. Each job in each step can be scheduled to run at the time or event that best fits your business needs and network performance requirements.
|
| < Day Day Up > |
|
SAS 9.1.3 ETL Studio: Users Guide
ISBN: 1590476352
EAN: 2147483647
EAN: 2147483647
Year: 2004
Pages: 127
Pages: 127
Authors: SAS Institute