3.1 Memory Allocation
| In our test application's image class described in Section 2.3.1 on page 12, we use the operators new and delete to allocate and free storage for our image pixels in apImage::init() and apImage::cleanup() . Our test application employs this simple memory management scheme to demonstrate that it can be trivial to come up with a working solution. This simple mechanism, however, is very inefficient and breaks down quickly as you try to extend it. Managing memory is critical for a fully functional image framework. Therefore, before we delve into adding functionality, we will design an object that performs and manages memory allocation. 3.1.1 Why a Memory Allocation Object Is NeededImages require a great deal of memory storage to hold the pixel data. It is very inefficient to copy these images, in terms of both memory storage and time, as the images are manipulated and processed . You can easily run out of memory if there are a large number of images. In addition, the heap could become fragmented if there isn't a large enough block of memory left after all of the allocations . You really have to think about the purpose of an image before duplicating it. Duplication of image data should only happen when there is a good reason to retain a copy of the image (for example, you want to keep the original image and the filtered image result).
We use this example as a simple way of showing how much memory and time a seemingly trivial operation can require. Note that some compilers can eliminate the temporary (a+b) storage allocation by employing a technique called return value optimization [Meyers96]. 3.1.2 Memory Allocation Object RequirementsInstead of designing an object that works only for images, we create a generic object that is useful for any application requiring allocation and management of heap memory. We had to overcome the desire to produce the perfect object, because we do not have an unlimited budget or time. Commercial software is fluid; it is more important that we design it such that it can be adapted , modified, and extended in the future. The design we are presenting here is actually the third iteration. Here's the list of requirements for our generic memory allocation object:
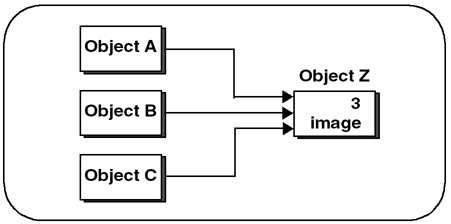
The STL is always a good resource for solutions. You can imagine where std::vector , std::list , or even std::string could be used to manage memory. Each has its advantages, but none of these template classes offer reference counting. And even if reference counting were not an issue, there are performance issues to worry about. Each of these template objects provides fast random access to our pixel data, but they are also optimized for insertion and deletion of data, which is something we do not need. Why Reference Counting Is EssentialOur solution is to create a generic object that uses reference counting to share and automatically delete memory when finished. Reference counting allows different objects to share the same information. Figure 3.3 shows three objects sharing image data from the same block of memory. Figure 3.3. Objects Sharing Memory In Figure 3.3, the object containing the image data, Object Z , also contains the reference count, 3 , which indicates how many objects are sharing the data. Objects A , B , and C all share the same image data. Consider the following: apImage image2 = image1 If reference counting is used in this example, image2 will share the same storage as image1 . If image1 and image2 point to identical memory, a little bookkeeping is necessary to make sure this shared storage is valid while either image is in scope. That's where reference counting comes in. Here's how it works in a nutshell . A memory allocation object allocates storage for an image. When subsequent images need to share that storage, the memory allocation object increments a variable, called a reference count, to keep track of the images sharing the storage; then it returns a pointer to the memory allocation object. When one of those images is deleted, the reference count is decremented. When the reference count decrements to zero, the memory used for storage is deleted. Let's look at an example using our memory allocation object, apAlloc<> . apAlloc<int> array1 (100); int i; for (i=0; i<100; i++) array1[i] = i; apAlloc<int> array2 = array1; for (i=0; i<100; i++) array1[i] = i*2; Once the apAlloc<> object is constructed , it is used much like any pointer. In this example, we create and populate an object array1 with data. After assigning this object to array2 , the code modifies the contents of array1 . array2 now contains the same contents as array1 . Reference counting is not a new invention, and there are many in-depth discussions on the subject. See [Meyers96] and [Stroustrup00]. 3.1.3 A Primer on TemplatesThe memory allocator objects use templates. The syntax can be confusing and tedious if you aren't used to it. Compilers are very finicky when it comes to handling templates, so the syntax becomes extremely important. Therefore, we provide a quick review of template syntax using a cookbook format. For a more detailed discussion, see [Stroustrup00] or [Vandevoorde03]. Converting a Class to TemplatesConsider this simple image class that we want to convert to a template class: class apImageTest { public: apImageTest (int width, int height, char* pixels); char* getPixel (int x, int y); void setPixel (int x, int y, char* pixel); private: char* pixels_; int width_, height_; }; The conversion is as easy as substituting a type name T for references to char as shown: template<class T> class apImageTest { public: apImageTest (int width, int height, T* pixels); T* getPixel (int x, int y); void setPixel (int x, int y, T* pixel); private: T* pixels_; int width_, height_; }; To use this object, you would replace references of apImageTest with apImageTest<char> .
Type Argument NamesAny placeholder name can be used to represent the template arguments. We use a single letter (usually T ), but you can use more descriptive names if you want. Consider the following: template<class Pixel> class apImageTest; Pixel is much more descriptive than T and may make your code more readable. There is no requirement to capitalize the first letter of the name, but we recommend doing so to avoid confusing argument names and variables . If you write a lot of template classes you will probably find that single-letter names are easier to use. Our final apImage<> class will have two arguments, T and S, that mean nothing out of context; however, when you are looking at the code, the parameters quickly take on meaning. class Versus typenameThe word class is used to define an argument name, but this argument does not have to be a class. In our apImageTest example shown earlier, we wrote apImageTest<char> , which expands the first line of the class declaration to: template<class char> class apImageTest; Although char is not a class, the compiler does not literally assume that the argument name T must be a class. You are also free to use the name typename instead of class when referring to templates. These are all valid examples of the same definition: template<class T> class apImageTest; template<typename T> class apImageTest; template<class Pixel> class apImageTest; template<typename Pixel> class apImageTest; Is there ever a case where class is not valid? Yes, because there can be parsing ambiguities when dependent types are used. See [Meyers01]. Late-model compilers that have kept current with the C++ Standard, such as gcc v3.1, will generate warning messages if typename is missing from these situations. For example, using gcc v3.1, the following line of code: apImage<T1>::row_iterator i1 = src1.row_begin(); produces a warning: warning: 'typename apImage<T1>::row_iterator' is implicitly a typename warning: implicit typename is deprecated, please see the documentation for details The compiler determines that row_iterator is a type rather than an instance of a variable or object, but warns of the ambiguity. To eliminate this warning, you must explicitly add typename , as shown: typename apImage<T1>::row_iterator i1 = src1.row_begin(); Another case where typename is an issue is in template specialization, because the use of typename is forbidden. [Vandevoorde03] points out that the C++ standardization committee is considering relaxing some of the typename rules. For example, you might think that the previous example could be converted as follows: typename apImage<apRGB>::row_iterator i1 = src1.row_begin(); where apRGB is the specialization. However, this generates an error: In function '...': using 'typename' outside of template To resolve the error, you must remove typename , as shown: apImage<apRGB>::row_iterator i1 = src1.row_begin(); There is a growing movement to use typename instead of class because of the confusion some new programmers encounter when using templates. If you do not have a clear preference, we recommend that you use typename . The most important thing is that you are consistent in your choice. Default Template ArgumentsYou can supply default template arguments much like you can with any function argument. These default arguments can even contain other template arguments, making them extremely powerful. For example, our apAlloc<> class that we design in Section 3.1.5 on page 31 is defined as: template<class T, class A = apAllocator_<T> > class apAlloc As we will see in that section, anyone who does not mind memory being allocated on the heap can ignore the second argument, and the apAllocator_<> object will be used to allocate memory. Most clients can think of apAlloc<> as having only a single parameter, and be blissfully ignorant of the details. The syntax we used by adding a space between the two ' > ' characters is significant. Defining the line as:
will produce an error or warning. The error message that the compiler produces in this case is extremely cryptic, and can take many iterations to locate and fix. Basically, the compiler is interpreting >> as operator>> . It is best to avoid this potential trap by adding a space between the two > characters. Inline Versus Non-Inline Template Definitions Many template developers put the implementation inside the class definition to save a lot of typing. For example, we could have given the getPixel() function in our apImageTest<> object an inline definition in the header file this way: template<class T> class apImageTest { public: ... T* getPixel (int x, int y) { return pixels_[y*width_ + x];} // No error detection ... }; We can also define getPixel() after the class definition (non-inline) in the header file: template <class T> T* apImageTest<T>::getPixel (int x, int y) { return pixels_[y*width_ + x];} Now you know why many developers specify the implementation inside the definition ”it is much less typing. For more complex definitions, however, you may want to define the implementation after the definition for clarity, or even in a separate file. If the template file is large and included everywhere, putting the implementation in a separate file can speed compilation. The choice is yours. The copy constructor makes a particularly interesting example of complex syntax: template<class T> apImageTest<T>::apImageTest (const apImageTest& src) {...} It is hard to get the syntax correct on an example like this one. The error messages generated by compilers in this case are not particularly helpful, so we recommend that you refer to a C++ reference book. See [Stroustrup00] or [Vandevoorde03]. Template SpecializationTemplates define the behavior for all types (type T in our examples). But what happens if the definition for a generic type is slow and inefficient? Specialization is a method where additional member function definitions can be defined for specific types. Consider an image class, apImage<T> . The parameter T can be anything, including some seldom used types like double or even std::string . But what if 90 percent of the images in your application are of a specific type, such as unsigned char ? An inefficient algorithm is fine for a generic parameter, but we would certainly like the opportunity to tell the compiler what to do if the type is unsigned char . To define a specialization, you first need the generic definition. It is good to write this first anyway to flesh out what each member function does. If you choose to write only the specialization, you should define the generic version to throw an error so that you will know if you ever call it unintentionally. Once the generic version is defined, the specialization for unsigned char can be defined as shown: template<> class apImageTest<unsigned char> { public: apImageTest (int width, int height, unsigned char* pixels); unsigned char* getPixel (int x, int y); void setPixel (int x, int y, unsigned char* pixel); private: unsigned char* pixels_; int width_, height_; }; We can now proceed with defining each specialized member function. Is it possible to define a specialization for just a single member function? The answer is yes. Consider a very generic implementation for our apImageTest<> constructor: template<class T> apImageTest<T>::apImageTest (int width, int height, T* pixels) : width_ (width), height_ (height), pixels_ (0) { pixels_ = new T [width_ * height_]; T* p = pixels_; for (int y=0; y<height; y++) { for (int x=0; x<width; x++) *p++ = *pixels++; // use assignment to copy pixels } } This definition is careful to use assignment to copy each pixel from the given array to the one controlled by the class. Now, let us define a specialization when T is an unsigned char : apImageTest<unsigned char>::apImageTest (int width, int height, unsigned char* pixels) : width_ (width), height_ (height), pixels_ (0) { pixels_ = new unsigned char [width_ * height_]; memcpy (pixels_, pixels, width_ * height_); } We can safely use memcpy() to initialize our pixel data. You can see that the syntax for specialization is different if you are defining the complete specialization, or just a single member function. Function TemplatesC++ allows the use of templates to extend beyond objects to also include simple function definitions. Finally we have the ability to get rid of most macros. For example, we can replace the macro min() : #ifndef min #define min(a,b) (((a) < (b)) ? (a) : (b)) #endif with a function template min() : template<class T> const T& min (const T& a, const T& b) { return (a<b) ? a : b;} We can even define function template specializations: template<> const char& min<char> (const char& a, const char& b) { return (a<b) ? a : b;} In this example, the specialization is unnecessary, but it does show the special syntax you will need to use for specialization. Function templates can also have multiple template parameters, but don't be surprised if the compiler sometimes selects a function you don't expect. Here is an example of a function that we used in an early iteration of our image framework: template<class T1, class T2, class T3> void add2 (const T1& s1, const T2& s2, T3& d1) { d1 = s1 + s2;} We needed such a function inside our image processing functions to control the behavior in overflow and underflow conditions. Specialized versions of this function test for overflow and clamp the output value at the maximum value for that data type, while other versions test for underflow and clamp the output value at the minimum value. The generic definition shown above just adds two source values and produces an output. You must be careful with these mixed-type function templates. It is entirely possible that the compiler will not be able to determine which version to call. We could not use the above definition of add2<> with recent C++ compilers, such as Microsoft Visual Studio, because our numerous overrides make it ambiguous, according to the latest C++ standard, as to which version of add2<> to call. So, our solution is to define non-template versions for all our expected data types, such as: void add2 (int s1, int s2, int& d1); If you plan on using mixed-type function templates, you should definitely create prototypes and compile and run them with the compilers you expect to use. There are still many older compilers that will compile the code correctly, but the code does not comply with the latest C++ standards. As compilers gain this compliance, you will need to implement solutions that conform to these standards. Explicit Template InstantiationC++ allows you to explicitly instantiate one or more template arguments. We can rewrite our add2() example to return the result, rather than pass it as a reference, as follows: template<class R, class T1, class T2> R add2 (const T1& s1, const T2& s2) { return static_cast<R> (s1 + s2);} There is no way for the compiler to decide what the return type is without the type being specified explicitly. Whenever you use this form of add2() , you must explicitly specify the destination type for the compiler, as follows: add2<double>(1.1, 2.2); add2<int>(1.1, 2.2); We will use explicit template instantiation later in the book to specify the data type for intermediate image processing calculations. For more information on explicit instantiation or other template issues, see [Vandevoorde03]. 3.1.4 Notations Used in Class DiagramsTable 3.1 shows a simple set of notations we use throughout the book to make the relationships clear in class diagrams. See [Lakos96]. Table 3.1. Notations Used in Class Diagrams
3.1.5 Memory Allocator Object's Class HierarchyThe class hierarchy for the memory allocator object is shown in Figure 3.4. Figure 3.4. Memory Allocator Object Class Diagram It consists of a base class, a derived class, and then the object class, which uses the derived class as one of its arguments. All three classes use templates. Note that we have appended an underscore character, _ , to some class names to indicate that they are internal classes used in the API, but never called directly by its clients. apAllocatorBase_<> is a base class that manages memory and contains all of the required functionality, except for the actual allocation and deallocation of memory. Its constructor basically initializes the object variables. apAllocator_<> is derived from apAllocatorBase_<> . apAllocator_<> manages the allocation and deallocation of memory from the heap. You can use apAllocator_<> as a model for deriving the classes from apAllocatorBase_<> that use other allocation schemes. apAlloc<> is a simple interface that the application uses to manage memory. apAlloc<> uses an apAllocator_<> object as one of its parameters to determine how to manage memory. By default, apAlloc<> allocates memory off the heap, because this is what our apAllocator_<> object does. However, if the application requires a different memory management scheme, a new derived allocator object can be easily created and passed to apAlloc<> . apAllocatorBase_<> ClassThe apAllocatorBase_<> base class contains the raw pointers and methods to access memory. It provides both access to the raw storage pointer, and access to the reference count pointing to shared storage, while also defining a reference counting mechanism. apAllocatorBase_<> takes a single template parameter that specifies the unit of memory to be allocated. The full base class definition is shown here. template<class T> class apAllocatorBase_ { public: apAllocatorBase_ (unsigned int n, unsigned int align) : pRaw_ (0), pData_ (0), ref_ (0), size_ (n), align_ (align) {} // Derived classes alloc memory; store details in base class virtual ~apAllocatorBase_ () {} // Derived classes will deallocate memory operator T* () { return pData_;} operator const T* () const { return pData_;} // Conversion to pointer of allocated memory type unsigned int size () const { return size_;} // Number of elements unsigned int ref () const { return ref_;} // Number of references unsigned int align () const { return align_;} // Alignment void addRef () { ref_++; } void subRef () { --ref_; if (ref_ == 0) delete this; } // Increment or decrement the reference count protected: virtual void allocate () = 0; virtual void deallocate () = 0; // Used to allocate/deallocate memory. T* alignPointer (void* raw); // Align the specified pointer to match our alignment apAllocatorBase_ (const apAllocatorBase_& src); apAllocatorBase_& operator= (const apAllocatorBase_& src); // No copy or assignment allowed. char* pRaw_; // Raw allocated pointer T* pData_; // Aligned pointer to our memory unsigned int size_; // Number of elements allocated unsigned int ref_; // Reference count unsigned int align_; // Memory alignment (modulus) }; You'll notice that the constructor in apAllocatorBase_ doesn't do anything other than initialize the object variables. We would have liked to have had the base class handle allocation and deallocation too, but doing so would have locked derived classes into heap allocation. This isn't obvious, until you consider how objects are constructed, as we will see in the next example.
We found it cleaner to define a base class, apAllocatorBase_<> , and later derive the object apAllocator_<> from it. The derived object handles the actual allocation and deallocation. This makes creating custom memory management schemes very simple. apAlloc<> simply takes an apAllocator_<> object of the appropriate type and uses that memory management scheme. We made apAllocatorBase_<> an abstract class by doing the following: virtual void allocate () = 0; virtual void deallocate () = 0; apAllocatorBase_<> never calls these functions directly, but by adding them we provide an obvious clue as to what functions need to be implemented in the derived class. Let's take a look at the non-obvious accessor functions in apAllocatorBase_<> : operator T* () { return pData_;} operator const T* () const { return pData_;} We define two different types of T* conversion operators, one that is const and one that isn't. This is a hint to the compiler on how to convert from apAlloc<> to a T* without having to explicitly specify it. See Section 8.2.2 on page 283. It isn't always the right choice to define these conversion operators. We chose to use operator T* because apAlloc<> is fairly simple and is little more than a wrapper around a memory pointer. By simple, we mean that there is little confusion if the compiler were to use operator T* to convert the object reference to a pointer.
Next we'll look at the functions that manage our reference count. void addRef () { ref_++;} void subRef () { if (--ref_ == 0) delete this;} These methods are defined in the base class for convenience but are only used in the derived class. Whenever an apAllocatorBase_<> object is constructed or copied , addRef() is called to increment our reference count variable. Likewise, whenever an object is deleted or otherwise detached from the object, subRef() is called. When the reference count becomes zero, the object is deleted. Note that later we will modify the definitions for addRef() and subRef() to handle multi-threaded synchronization issues. Memory alignment is important because some applications might want more control over the pointer returned after memory is allocated. Most applications prefer to leave memory alignment to the compiler, letting it return whatever address it wants. We provide memory alignment capability in apAllocatorBase_<> so that derived classes can allocate memory on a specific boundary. On some platforms, this technique can be used to optimize performance. This is especially useful for imaging applications, because image processing algorithms can be optimized for particular memory alignments. When a derived class allocates memory, it stores a pointer to that memory in pRaw_ , which is defined as a char* . Once the memory is aligned, the char* is cast to type T* and stored in pData_ , which serves as a pointer to the aligned memory. alignPointer() is defined in apAllocatorBase_<> to force a pointer to have a certain alignment. The implementation presented here is acceptable for single-threaded applications and is sufficient for our current needs. Later it will be extended to handle multi-threaded applications. Here is the final version of this implementation: T* alignPointer (void* raw) { T* p = reinterpret_cast<T*>( (reinterpret_cast<uintptr_t>(raw) + align_ - 1) & ~(align_ - 1)); return p; } Here is how we arrived at this implementation: in order to perform the alignment arithmetic, we need to change the data type to some type of numeric value. The following statement accomplishes this by casting our raw pointer to a uintptr_t (a type large enough to hold a pointer): reinterpret_cast<uintptr_t>(raw) By subsequently casting the raw pointer to an uintptr_t , we're able to do the actual alignment arithmetic, as follows: (reinterpret_cast<uintptr_t>(raw) + align_ - 1) & ~(align_ - 1); Basically, we want to round up the address, if necessary, so that the address is of the desired alignment. The only way to guarantee a certain alignment is to allocate more bytes than necessary (in our case, we must allocate (align_-1) additional bytes). alignPointer() works for any alignment that is a power of two. For example, if align_ has the value of 4 (4-byte alignment), then the code would operate as follows: (reinterpret_cast<uintptr_t>(raw) + 3) & ~3); It now becomes clear that we are trying to round the address up to the next multiple of 4. If the address is already aligned on this boundary, this operation does not change the memory address; it merely wastes 3 bytes of memory. The only thing left is to cast this pointer back to the desired type. We use reinterpret_cast<> to accomplish this, since we must force a cast between pointer and integer data types. Conversely, this example uses old C-style casting:
This is still legal, but it doesn't make it obvious what our casts are doing. Note that for systems that do not define the symbol uintptr_t , you can usually define your own as: typedef int uintptr_t;
The only thing we haven't discussed from apAllocatorBase_<> is the copy constructor and assignment operator: apAllocatorBase_ (const apAllocatorBase_& src); apAllocatorBase_& operator= (const apAllocatorBase_& src); // No copy or assignment is allowed. We include a copy constructor and assignment operator, but don't provide an implementation for them. This causes the compiler to generate an error if either of these functions is ever called. This is intentional. These functions are not necessary, and worse , will cause our reference counting to break if the default versions were to run. Once an apAllocatorBase_<> object or derived object is created, we only reference them using pointers. apAllocator_<> ClassThe apAllocator_<> class, which is derived from apAllocatorBase_<> , handles heap-based allocation and deallocation. Its definition is shown here template<class T> class apAllocator_ : public apAllocatorBase_<T> { public: explicit apAllocator_ (unsigned int n, unsigned int align = 0) : apAllocatorBase_<T> (n, align) { allocate (); addRef (); } virtual ~apAllocator_ () { deallocate();} private: virtual void allocate () ; // Allocate our memory for size_ elements of type T with the // alignment specified by align_. 0 and 1 specify no alignment, // 2 = word alignment, 4 = 4-byte alignment, ... This must // be a power of 2. virtual void deallocate (); apAllocator_ (const apAllocator_& src); apAllocator_& operator= (const apAllocator_& src); // No copy or assignment is allowed. }; Constructor and DestructorThe apAllocator_<> constructor handles memory allocation, memory alignment, and setting the initial reference count value. The destructor deletes the memory when the object is destroyed . The implementation of the constructor is: public: explicit apAllocator_ (unsigned int n, unsigned int align = 0) : apAllocatorBase_<T> (n, align) { allocate (); addRef (); } virtual ~apAllocator_ () { deallocate();} ... private: apAllocator_ (const apAllocator_& src); apAllocator_& operator= (const apAllocator_& src); // No copy or assignment is allowed. The apAllocator_<> constructor takes two arguments, a size parameter and an alignment parameter. Although the alignment parameter is an unsigned int , it can only take certain values. A value of 0 or 1 indicates alignment on a byte boundary; in other words, no special alignment is needed. A value of 2 means that memory must be aligned on a word (i.e., 2-byte) boundary. A value of 4 means that memory must be aligned on a 4-byte boundary.
The constructor also calls addRef() directly. This means that the client code does not have to explicitly touch the reference count when an apAllocator_<> object is created. The reference count is set to 1 when the object is constructed. What would happen if the client does call addRef() ? This would break the reference counting scheme because the reference count would be 2 instead of 1. When the object is no longer used and the final instance of apAllocator_<> calls subRef() , the reference count would be decremented to 1 instead of to 0. We would end up with an object in heap memory that would never be freed. Similarly, if we decided to leave out the call to addRef() in the constructor and force the client to call it explicitly, it could also lead to problems. If the client forgets to call addRef() , the reference count stays at zero. Our strategy is to make it very clear through the comments embedded in the code about what is responsible for updating the reference count. We use the explicit keyword in the constructor. This keyword prevents the compiler from using the constructor to perform an implicit conversion from type unsigned int to type apAllocator_<> . The explicit keyword can only be used with constructors that take a single argument, and our constructor has two arguments. Or does it? Since most users do not care about memory alignment, the second constructor argument has a default value of 0 for alignment (i.e., perform no alignment). So, this constructor can look as if it has only a single argument (i.e., apAllocator_<char> alloc (5); ).
AllocationThe constructor calls the allocate() function to perform the actual memory allocation. The full implementation of this function is as follows: protected: virtual void allocate () { if (size_ == 0) { // Eliminate possibility of null pointers by allocating 1 item. pData_ = new T [1]; pRaw_ = 0; return; } if (align_ < 2) { // Let the compiler worry about any alignment pData_ = new T [size_]; pRaw_ = 0; } else { // Allocate additional bytes to guarantee alignment. // Then align and cast to our desired data type. pRaw_ = new char [sizeof(T) * size_ + (align_ - 1)]; pData_ = alignPointer (pRaw_); } } Our allocate() function has three cases it considers.
DeallocationOur deallocate() function must cope with the pRaw_ and pData_ pointers. Whenever we bypass performing our own memory alignment, the pRaw_ variable will always be null. This is all our function needs to know to delete the appropriate pointer. The deallocate() definition is as follows: virtual void deallocate () { // Decide which pointer we delete if (pRaw_) delete [] pRaw_; else delete [] pData_; pRaw_ = 0; pData_ = 0; } At the end of the deallocate() function, we set both the pRaw_ and pData_ variables to their initial state ( ). Some developers will skip this step, because deallocate() is only called by the destructor, so in an attempt to be clever, a possible bug is introduced. Sometime in the future, the deallocate() function may also be used in other places, such as during an assignment operation. In this case, the values of pRaw_ and pData_ will appear to point to valid memory.
apAlloc<> ClassapAlloc<> is our memory allocation object. This is the object that applications will use directly to allocate and manage memory. The definition is shown here. template<class T, class A = apAllocator_<T> > class apAlloc { public: static apAlloc& gNull (); // We return this object for any null allocations // It actually allocates 1 byte to make all the member // functions valid. apAlloc (); // Null allocation. Returns pointer to gNull() memory explicit apAlloc (unsigned int size, unsigned int align=0); ~apAlloc (); // Allocate the specified bytes, with the correct alignment. // 0 and 1 specify no alignment. 2 = word alignment, // 4 = 4-byte alignment. Must be a power of 2. apAlloc (const apAlloc& src); apAlloc& operator= (const apAlloc& src); // We need our own copy constructor and assignment operator. unsigned int size () const { return pMem_->size ();} unsigned int ref () const { return pMem_->ref ();} bool isNull () const { return (pMem_ == gNull().pMem_);} const T* data () const { return *pMem_;} T* data () { return *pMem_;} // Access to the beginning of our memory region. Use sparingly const T& operator[] (unsigned int index) const; T& operator[] (unsigned int index); // Access a specific element. Throws the STL range_error if // index is invalid. virtual A* clone (); // Duplicate the memory in the underlying apAllocator. void duplicate (); // Breaks any reference counting and forces this object to // have its own copy. protected: A* pMem_; // Pointer to our allocated memory static apAlloc* sNull_; // Our null object }; The syntax may look a little imposing because apAlloc<> has two template parameters: template<class T, class A> class apAlloc
Parameter T specifies the unit of allocation. If we had only a single parameter, the meaning of it would be identical to the meaning for other STL types. For example, vector<int> v; apAlloc<int> a; describe instances of a template whose unit of storage is an int . Parameter A specifies how and where memory is allocated. It refers to another template object whose job is to allocate and delete memory, manage reference counting, and allow access to the underlying data. If we have an application that requires memory to be allocated differently, say a private memory heap, we would derive a specific apAllocator_<> object to do just that. In our case, the second parameter, A , uses the default implementation apAllocator_<> to allocate memory from the heap. This allows us to write such statements as: apAlloc<int> a1; // Null allocation apAlloc<int> a2 (100); // 100 elements apAlloc<int> a3 (100, 4); // 100 elements, 4-byte align The null allocation, an allocation with no specified size, is of special interest because of how we implement it. We saw that the apAllocator_<> object supported null allocations by allocating one element. It is possible that many (even hundreds) of null apAlloc<> objects may be in existence. This wastes heap memory and causes heap fragmentation. Our solution is to only ever have a single null object for each apAlloc<> instance. We do this in a manner similar to constructing a Singleton object. Singleton objects are typically used to create only a single instance of a given class. See [Gamma95] for a comprehensive description of the Singleton design pattern. We use a pointer, sNull_ , and a gNull() method to accomplish this: template<class T, class A> apAlloc<T,A>* apAlloc<T, A>::sNull_ = 0; This statement creates our sNull_ pointer and sets it to null. The only way to access this pointer is through the gNull() method, whose implementation is shown here. template<class T, class A> apAlloc<T,A>& apAlloc<T, A>::gNull () { if (!sNull_) sNull_ = new apAlloc (0); return *sNull_; } The first time gNull() is called, sNull_ is zero, so the single instance is allocated by calling apAlloc() . For this and subsequent calls, gNull() returns a reference to this object. A null apAlloc<> object is created by passing zero to the apAlloc<> constructor. This is a special case. When zero is passed to the apAllocator_<> object to do the allocation, a single element is actually created so that we never have to worry about null pointers. In this case, all null allocations refer to the same object. Note that this behavior differs from the C++ standard, which specifies that each null object is unique. gNull() can be used directly, but its main use is to support the null constructor. template<class T, class A> apAlloc<T, A>::apAlloc () : pMem_ (0) { pMem_ = gNull().pMem_; pMem_->addRef (); } apAlloc<> contains a pointer to our allocator object, pMem_ . The constructor copies the pointer and tells the pMem_ object to increase its reference count. The result is that any code that constructs a null apAlloc<> object will actually point to the same gNull() object. So, why didn't we just write the constructor as: *this = gNull(); This statement assigns our object to use the same memory as that used by gNull() . We will discuss the copy constructor and assignment operator in a moment. The problem is that we are inside our constructor and the assignment assumes that the object is already constructed. On the surface it may look like a valid thing to do, but the assignment operator needs to access the object pointed to by pMem_ , and this pointer is null. Assignment Operator and Copy ConstructorThe assignment operator and copy constructor are similar, so we will only look at the assignment operator here: template<class T, class A> apAlloc<T, A>& apAlloc<T, A>:: operator= (const apAlloc& src) { // Make sure we don't copy ourself! if (pMem_ == src.pMem_) return *this; // Remove reference from existing object. addRef() and subRef() // do not throw so we don't have to worry about catching an error pMem_->subRef (); // Remove reference from existing object pMem_ = src.pMem_; pMem_->addRef (); // Add reference to our new object return *this; } First, we must detach from whatever memory allocation we were using by calling subRef() on our allocated object. If this was the only object using the apAllocator_<> object, it would be deleted at this time. Next, we point to the same pMem_ object that our src object is using, and increase its reference count. Because we never have to allocate new memory and copy the data, these operations are very fast. Memory AccessAccessing memory is handled in two different ways. We provide both const and non- const versions of each to satisfy the needs of our clients. To access the pointer at the beginning of memory, we use: T* data () { return *pMem_;} When we discussed the apAllocatorBase_<> object, we talked about when it is appropriate to use operator T* and when a function like data() should instead be used. In apAllocatorBase_<> , we chose to use the operator syntax so that *pMem_ will return a pointer to the start of our memory. In this apAlloc<> object, we use the data() method to grant access to memory, because we want clients to explicitly state their intention . operator[] prevents the user from accessing invalid data, as shown: template<class T, class A> T& apAlloc<T, A>::operator[] (unsigned int index) { if (index >= size()) throw std::range_error ("Index out of range"); return *(data() + index); } Instead of creating a new exception type to throw, we reuse the range_error exception defined by the STL. Object DuplicationThe duplicate() method gives us the ability to duplicate an object, while letting both objects have separate copies of the underlying data. Suppose we have the following code: apAlloc<int> alloc1(10); apAlloc<int> alloc2 = alloc1; Right now, these two objects point to the same underlying data. But what if we want to force them to use separate copies? This is the purpose of duplicate() , whose implementation is shown here: template<class T, class A> void apAlloc<T, A>::duplicate () { if (ref() == 1) return; // No need to duplicate A* copy = clone (); pMem_->subRef (); // Remove reference from existing object pMem_ = copy; // Replace it with our duplicated data } Notice that this is very similar to our assignment operator, except that we use our clone() method to duplicate the actual memory. Instead of putting the copy functionality inside duplicate() , we place it inside clone() to allow clients to specify a custom clone() method for classes derived from apAlloc<> . This version of clone() does a shallow copy (meaning a bit-wise copy) on the underlying data: template<class T, class A> A* apAlloc<T, A>::clone () { A* copy = new A (pMem_->size(), pMem_->align()); // Shallow copy T* src = *pMem_; T* dst = *copy; std::copy (src, &(src[pMem_->size()]), dst); return copy; } Under most conditions, a shallow copy is appropriate. We run into problems if T is a complex object or structure that includes pointers that cannot be copied by means of a shallow copy. Our image class is not affected by this issue because our images are constructed from basic types. Instead of using memcpy() to duplicate the data, we are using std::copy to demonstrate how it performs the same function. |

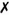 template<class T, class A = apAllocator_<T>>
template<class T, class A = apAllocator_<T>> 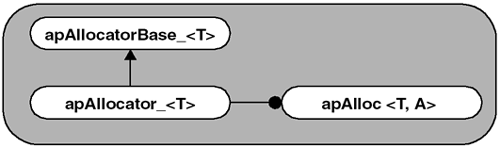
EAN: 2147483647
Pages: 59