Section 9.1. Toolchain
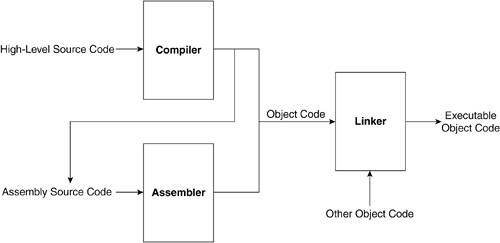
9.1. ToolchainA toolchain is the set of programs necessary to create a Linux kernel image. The concept of the chain is that the output of one tool becomes the input for the next. Our toolchain includes a compiler, an assembler, and a linker. Technically, it needs to also include your text editor, but this section covers the first three tools mentioned. A toolchain is something that is necessary whenever we want to develop software. The necessary tools are also referred to as Software Development Kit (SDK). A compiler is a translation program that takes in a high-level source language and produces a low-level object language. The object code is a series of machine-dependent commands running on the target system. An assembler is a translation program that takes in an assembly language program and produces the same kind of object code as the compiler. The difference here is that there is a one-to-one correspondence between each line of the assembly language and each machine instruction produced whereas every line of high-level code might get translated into many machine instructions. As you have seen, some of the files in the architecture-dependent sections of the Linux source code are in assembly. These get compiled down (into object code) by issuing a call to an assembler. A link editor (or linker) groups executable modules for execution as a unit. Figure 9.1 shows the "chaining" of the toolchain. The linker would be linking the object code of our program with any libraries we are using. Compilers have flags that allow the user the level to which it compiles down. For example, in Figure 9.1, we see that the compiler can directly produce machine code or compile down to assembly source code, which can then be assembled into machine code that the computer can directly execute. Figure 9.1. Toolchain
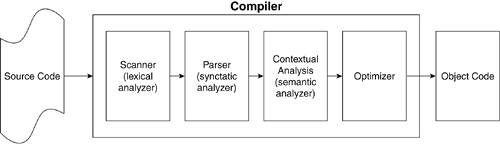
9.1.1. CompilersCommon compilers also have a "chaining" quality internally whereby they execute a series of phases or steps where the output of one phase is the input of the next. Figure 9.2 diagrams these phases. The first step of compiling is the scanner phase, which breaks the high-level program into a series of tokens. Next, the parser phase groups the tokens according to syntactical rules, and the contextual analysis phase further groups them by semantic attributes. An optimizer then tries to increase the efficiency of the parsed tokens and the code generation phase produces the object code. The output of the compiler is a symbol table and relocatable object code. That is, the starting address of each compiled module is 0 and must be relocated to its proper place at link time. Figure 9.2. Compiler Operation
9.1.2. Cross CompilersToolkits usually run natively, which means that the object code they generate runs on the same system on which it is compiled. If you are developing a kernel on an x86 system to load on another (or the same) x86 system, you can get away with using whatever compiler comes with the system. Power Macs and the myriad of x86 boxes all compile code that runs on their respective architectures. But what if we wanted to write code on one platform and run it on another? This is not as odd as it sounds. Consider the embedded market. Embedded systems are usually implemented to have just enough memory and I/O to get the job done. Whether it is controlling an automobile, router, or cell phone, there is rarely any room for a full native development environment on an embedded system (let alone monitor or keyboard). The solution is to have developers use their powerful and relatively inexpensive workstations as host systems to develop code that they can then download and test on the target system. Hence, the term cross compiler! For example, you might be a developer for a PowerPC-embedded system that has a 405 processor in it. Most of your desktop development systems are x86 based. By using gcc, for example, you would do all of your development (both C and assembler) on the desktop and compile with the -mcpu=405 option.[1] This creates object code using 405-specific instructions and addressing. You would then download the executable to the embedded system to run and debug. Granted, this sounds tedious, but with the limited resources of a target embedded system, it saves a great deal of memory.
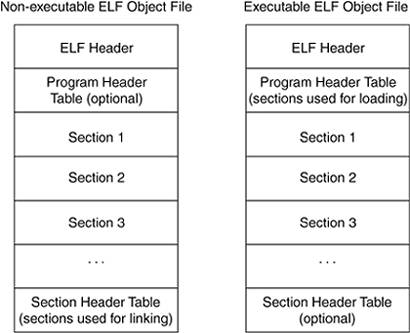
For this particular environment, many tools are on the market to assist in the development and debugging of cross-compiled embedded code. 9.1.3. LinkerWhen we compile a C program ("hello world!," for example), there is far more code than the three or four lines in our .c file. It is the job of the linker to find all these externally referenced modules and "link" them. External modules or libraries originate from the developer, the operating system, or (the home of printf()) the C runtime library. The linker extracts these libraries, fixes up pointers (relocation), and references (symbol resolution) across the modules to create an executable module. Symbols can be global or local. Global symbols can be defined within a module or externally referenced by a module. It is the linker's job to find a definition for each symbol associated with a module. (Note that user space libraries are not available to the kernel programmer.) For common function, the kernel has its own versions available. Static libraries are found and copied at link time, while dynamic libraries or shared libraries can be loaded at runtime and shared across processes. Microsoft and OS/2 call shared libraries dynamic link libraries. Linux provides the system calls dlopen(), dlsym(), and dlclose(), which can be used to load/open a shared library, find a symbol in the library, and then close the shared library. 9.1.4. ELF Object FilesThe format of object files varies from manufacturer to manufacturer. Today, most UNIX systems use the Executable and Linking Format (ELF). Many types of ELF files exist, each of which performs a different function. The main types of ELF files are executable files, relocatable object files, and core files or shared libraries. The ELF format allows object files to be compatible across platforms and architectures. Figure 9.3 illustrates an executable and a non-executable ELF object file. Figure 9.3. Executable and Non-Executable ELF Files
The ELF header is always at offset zero within the ELF file. Everything in the file can be found through the ELF header. Because the ELF header is the only fixed structure in the object file, it must point to and specify the size of the substructures within the file. All the ELF files are broken down into blocks of similar data called sections or segments. The non-executable object file contains sections and a section header table, while the executable object files must contain segments and a program header table. 9.1.4.1. ELF HeaderThe ELF header is kept track of in the Linux structure elf32_hdr (for a 32-bit system, that is; for 64-bit systems, there is the elf64_hdr structure). Let's look at this structure: ----------------------------------------------------------------------- include/linux/elf.h 234 #define EI_NIDENT 16 235 236 typedef struct elf32_hdr{ 237 unsigned char e_ident[EI_NIDENT]; 238 Elf32_Half e_type; 239 Elf32_Half e_machine; 240 Elf32_Word e_version; 241 Elf32_Addr e_entry; /* Entry point */ 242 Elf32_Off e_phoff; 243 Elf32_Off e_shoff; 244 Elf32_Word e_flags; 245 Elf32_Half e_ehsize; 246 Elf32_Half e_phentsize; 247 Elf32_Half e_phnum; 248 Elf32_Half e_shentsize; 249 Elf32_Half e_shnum; 250 Elf32_Half e_shstrndx; 251 } Elf32_Ehdr; ----------------------------------------------------------------------- Line 237The e_ident field holds the 16-byte magic number, which identifies a file as an ELF file. Line 238The e_type field specifies the object file type, such as executable, relocatable, or shared object. Line 239The e_machine field identifies the architecture of the system for which the file is compiled. Line 240The e_version field specifies object file version. Line 241The e_enTRy field holds the starting address of the program. Line 242The e_phoff field holds the program header table offset in bytes. Line 243The e_shoff field holds the offset for the section header table offset in bytes. Line 244The e_flags field holds processor-specific flags. Line 245The e_ehsize field holds the size of the ELF header. Line 246The e_phentsize field holds the size of each entry in the program header table. Line 247The e_phnum field contains the number of entries in the program header. Line 248The e_shentsize field holds the size of each entry in the section header table. Line 249The e_shnum field holds the number of entries in the section header, which indicates the number of sections in the file. Line 250The e_shstrndx field holds the index of the section string within the section header. 9.1.4.2. Section Header TableThe section header table is an array of type Elf32_Shdr. Its offset in the ELF file is given by the e_shoff field in the ELF header. There is one section header table for each section in the file: ----------------------------------------------------------------------- include/linux/elf.h 332 typedef struct { 333 Elf32_Word sh_name; 334 Elf32_Word sh_type; 335 Elf32_Word sh_flags; 336 Elf32_Addr sh_addr; 337 Elf32_Off sh_offset; 338 Elf32_Word sh_size; 339 Elf32_Word sh_link; 340 Elf32_Word sh_info; 341 Elf32_Word sh_addralign; 342 Elf32_Word sh_entsize; 343 } Elf32_Shdr; ----------------------------------------------------------------------- Line 333The sh_name field contains the section name. Line 334The sh_type field contains the section's contents. Line 335The sh_flags field contains information regarding miscellaneous attributes. Line 336The sh_addr field holds the address of the section in memory image. Line 337The sh_offset field holds the offset of the first byte of this section within the ELF file. Line 338The sh_size field contains the section size. Line 339The sh_link field contains the index of the table link, which depends on sh_type. Line 340The sh_info field contains extra information, depending on the value of sh_type. Line 341The sh_addralign field contains the address alignment constraints. Line 342The sh_entsize field contains the entry size of the sections when it holds a fixed-size table. 9.1.4.3. Non-Executable ELF File SectionsThe ELF file is divided into a number of sections, each of which contains information of a specific type. Table 9.1 outlines the types of sections. Some of these sections are only present if certain compiler flags are set at compile time. Recall that ELF32_Ehdr->e_shnum holds the number of sections in the ELF file.
9.1.4.4. Program Header TableThe header table for an executable or shared object file is an array of structures, each describing a segment or other information for execution: ----------------------------------------------------------------------- include/linux/elf.h 276 typedef struct elf32_phdr{ 277 Elf32_Word p_type; 278 Elf32_Off p_offset; 279 Elf32_Addr p_vaddr; 280 Elf32_Addr p_paddr; 281 Elf32_Word p_filesz; 282 Elf32_Word p_memsz; 283 Elf32_Word p_flags; 284 Elf32_Word p_align; 285 } Elf32_Phdr; ----------------------------------------------------------------------- Line 277The p_type field describes the type of segment this is. Line 278The p_offset field holds the offset from the beginning of the file to where the segment begins. Line 279The p_vaddr field holds the segment's virtual address if used. Line 280The p_paddr field holds the segment's physical address if used. Line 281The p_filesz field holds the number of bytes in the file image of the segment. Line 282The p_memsz field holds the number of bytes in the memory image of the segment. Line 283The p_flags field holds the flags depending on p_type. Line 284The p_align field describes how aligned the segment is aligned in memory. The value is in integral powers of 2. Using this information, the system exec() function, along with the linker, works to create a process image of the executable program in memory. This includes the following:
By understanding the object file formats and the available tools, you can better debug compile-time problems (such as unresolved references) and runtime problems by knowing where code is loaded and relocated. |
EAN: N/A
Pages: 134