Section 6.1. General Filesystem Concepts
6.1. General Filesystem ConceptsWe begin with a description of the concepts behind the Linux filesystem. For many of you, these concepts are familiar because they are tied into Linux usage and the programming of user space applications. If you feel comfortable with general filesystem concepts, skip ahead to Section 6.2, "Linux Virtual Filesystem." 6.1.1. File and FilenamesThe word file is terminology borrowed from the real world. Information was stored in files since before the advent of vacuum tubes. A real-world file is composed of one or more pieces of paper of a predetermined size. These files are generally stored in a cabinet. In Linux, a file is a linear stream of bytes. The significance of these bytes is of no interest to the operating system, but they are of extreme importance to the user, much like the cabinet is indifferent to the contents of its files. The filesystem provides a user interface to data storage and transparently manipulates the physical data from the external drives. A file in Linux has many attributes and characteristics. The attribute most familiar to a user is usually the file's name. The name of a file often indicates the file's content. A filename can have a filename extension, which is an additional name appended to the primary filename with a period. This extension provides an additional manner of distinguishing content to user space applications. For example, all the example files we've looked at so far have a filename extension of .h or .c. User space programs, such as compilers and linkers, use these as indicators that the files are header files or source files, respectively. Although the filename can be important to a user application such as a compiler, the operating system is indifferent to filenames because it deals only with the file as a container of bytes irrespective of its content or purpose. 6.1.2. File TypesLinux supports many file types, including regular files, directories, links, device files, sockets, and pipes. Regular files include binary files and ASCII files. ASCII files are simply lines of text that can be displayed and understood by a user without any need for an interpreter program. Some ASCII files are executable and are called scripts. These files are executed by programs called interpreters. The shell, at its most basic, is an interpreter. Executable binary files are non-ASCII files that seemingly display random data. These files have an internal format that is interpreted by the kernel to run the program. The format is known as an object file format, and each operating system interprets predetermined object file formats. Chapter 9, "Building the Linux Kernel," covers object file formats in more detail. In Linux, files are organized into a hierarchical directory system, such as the one shown in Figure 6.1. A directory contains files and exists to maintain the filesystem structure. The following sections look at directories and the Linux file structure in more detail. Figure 6.1. Filesystem Hierarchy
A link is a file that points to another file, a file pointer. These files simply contain the information necessary to access another file. Device files are representations of I/O devices used to access these hardware devices. Programs that need to access an I/O device can use the same attributes that apply to files to affect the device on which it is acting. Two main types of devices exist: block devices, which transfer data in blocks, and character devices, which transfer data in characters. Chapter 5, "Input/Output," covers the details of I/O devices. Sockets and pipes are forms of Interprocess Communication (IPC). These files support directional data flow between processes. We do not discuss these special files. 6.1.3. Additional File AttributesA file has more attributes than its name, type, and data. The operating system associates additional information with each file, such as permissions for file access. File protection becomes increasingly important in multiuser systems, such as Linux. Users are classified into three categories:
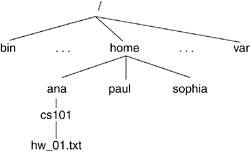
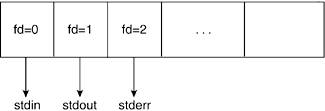
For each of these users, the file allows a particular set of permissions. Although many operations can be applied to a file, Linux summarizes permissions as they apply to three file operations: read, write, and execute. Because each of these three classes is applied to each of the three user categories, a file has nine sets of permissions associated with it. Other attributes include file size, creation timestamp, and last-access timestamp, all of which are displayed by the core utility ls. When we look at the kernel's implementation of files, we see that many other attributes are not visible to the user. 6.1.4. Directories and PathnamesA directory is a file that maintains the hierarchical structure of the filesystem. The directory keeps track of the files it contains, any directories beneath it, and information about itself. In Linux, each user gets his own "home directory," under which he stores his files and creates his own directory tree structure. In Figure 6.1, we see how the directory contributes to the tree structure of the filesystem. With the arrangement of the filesystem into a tree structure, the filename alone is not sufficient to locate the file; we must know where it is located in the tree to find it. A file's pathname describes the location of the file. A file's location can be described with respect to the root of the tree, which is known as the absolute pathname. The absolute pathname starts with the root directory, which is referred to as /. A directory node's name is the directory name followed by a /, such as bin/. Thus, a file's absolute pathname is expressed as a collection of all the directory nodes one traverses in the tree until one reaches the file. In Figure 6.1, the absolute pathname of the file called hw1.txt is /home/ana/cs101/hw1.txt. Another way of representing a file is with a relative pathname. This depends on the working directory of the process associated with the file. The working directory, or current directory, is a directory associated with the execution of a process. Hence, if /home/ana/ is the working directory for our process, we can refer to the file as cs101/hw1.txt. In Linux, directories contain files that perform varying tasks during the operation of the operating system. For example, shareable files are stored under /usr and /opt whereas unshareable files are stored under /etc/ and /boot. In the same manner, non-static files, those whose contents are changed by system programs, are stored under the vcertain directories under /var. Refer to http://www.pathname.com/fhs for more information on the filesystem hierarchy standard. In Linux, each directory has two entries associated with it: . (pronounced "dot") and .. (pronounced "dot dot"). The . entry denotes the current directory and .. denotes the parent directory. For the root directory, . and .. denote the current directory. (In other words, the root directory is its own parent.) This notation plays into relative pathnames in the following manner. In our previous example, the working directory was /home/ana and the relative pathname of our file was csw101/hw1.txt. The relative pathname of a hw1.txt file in paul's directory from within our working directory is ../paul/cs101/hw1.txt because we first have to go up a level. 6.1.5. File OperationsFile operations include all operations that the system allows on the files. Generally, files can be created and destroyed, opened and closed, read and written. Additionally, files can also be renamed and its attributes can be changed. The filesystem provides system calls as interfaces to these operations, and these are in turn placed in wrapper functions that are made accessible to user space applications by way of linkable libraries. We explore some of these operations as we traverse through the implementation of the Linux filesystem. 6.1.6. File DescriptorsA file descriptor is an int datatype that the system uses to identify an open file. The open() system call returns a file descriptor that can later be used on all future operations to be visited upon that file by that process. In a later section, we see what the file descriptor stands for in kernel terms. Each process holds an array of file descriptors. When we discuss the kernel structures that support the filesystem, we see how this information is maintained in an array. It is by convention that the first element of the array (file descriptor 0) is associated with the process' standard input, the second (file descriptor 1) with standard output, and the third (file descriptor 2) with standard error. This allows applications to open a file on standard input, output, or error. Figure 6.2 illustrates the file descriptor array pertaining to a process. Figure 6.2. File Descriptor Array
File descriptors are assigned on a "lowest available index" basis. Thus, if a process is to open multiple files, the assigned file descriptors will be incrementally higher unless a previously opened file is closed before the new one. We see how the open and close system calls manipulate file descriptors to ensure this. Hence, within a process' lifetime, it might open two different files that will have the same file descriptor if one is closed before the other is opened. Conversely and separately, two different file descriptors can point to the same file. 6.1.7. Disk Blocks, Partitions, and ImplementationTo understand the concerns of filesystem implementation, we need to understand some basic concepts about hard disks. Hard disks magnetically record data. A hard disk contains multiple rotating disks on which data is recorded. A head, which is mounted on a mechanical arm that moves over the surface of the disk, reads and writes the data by moving along the radius of the disks, much like the needle of a turntable. The disks themselves rotate much like LP's on a turntable. Each disk is broken up into concentric rings called tracks. Tracks are numbered starting from the outside to the inside of the disk. Groups of the same numbered tracks (across the disks) are called cylinders. Each track is in turn broken up into (usually) 512K byte sectors. Cylinders, tracks, and heads make up the geometry of a hard drive. A blank disk must first be formatted before the filesystem is made. Formatting creates tracks, blocks, and partitions in a disk. A partition is a logical disk and is how the operating system allocates or uses the geometry of the hard drive. The partitions provide a way of dividing a single hard disk to look as though there were multiple disks. This allows different filesystems to reside in a common disk. Each partition is split up into tracks and blocks. The creation of tracks and blocks in a disk is done by way of programs such as fdformat[1] whereas the creation of logical partitions is done by programs such as fdisk. Both of these precede creation of the actual filesystem.
The Linux file tree can provide access to more than one filesystem. This means that if you have a disk with multiple partitions, each of which has a filesystem, it is possible to view all these filesystems from one logical namespace. This is done by attaching each filesystem to the main Linux filesystem tree by using the mount command. We say that a filesystem is mounted to refer to the fact that the device filesystem is attached and accessible from the main tree. Filesystems are mounted onto directories.[2] The directory onto which a filesystem is mounted is referred to as the mount point.
One of the main difficulties in filesystem implementation is in determining how the operating system will keep track of the sequence of bytes that make up a file. As previously mentioned, the disk partition space is split into chunks of space called blocks. The size of a block varies by implementation. The management of blocks determines the speed of file access and the level of fragmentation[3] and therefore wasted space. For example, if we have a block size of 1,024 bytes and a file size of 1,567 bytes, the file spans two blocks. The operating system keeps track of the blocks that belong to a particular file by keeping the information in a structure called an index node (inode).
6.1.8. PerformanceThere are various ways in which the filesystem improves system performance. One way is by maintaining internal infrastructure in the kernel that quickly accesses an inode that corresponds to a given pathname. We see how the kernel does this when we explain filesystem implementation. The page cache is another method in which the filesystem improves performance. The page cache is an in-memory collection of pages. It is designed to cache many different types of pages, originating from disk files, memory-mapped files, or any other page object the kernel can access. This caching mechanism greatly reduces disk accesses and thus improves system performance. This chapter shows how the page cache interacts with disk accesses in the course of file manipulation. |
EAN: N/A
Pages: 134