The Internal View: Assembly Physical Structure
As you will be aware from your basic .NET programming, assemblies are the basic unit of code deployment. Microsoft likes to tell us that they form the logical security and version boundary for code, which is basically techno-speak for the same thing. You will also be aware that an assembly can contain a number of files (with the exception of dynamic assemblies, which we'll examine in Chapter *, and which exist in memory only):
-
A portable executable (PE) file containing the prime module (this file must be present)
-
Any number of optional PE files that contain other modules
-
Any number of optional resource files that contain data and can be in any format
We will examine resource files later in the chapter. For now, we will concentrate on files that contain code - the PE files - and take a high-level look at the structure of these files and what kind of information they contain. I'm not going to go into too much detail - and don't worry, I'm not going to start looking at the low-level binary details of the files (well, not much anyway). However, I do want to give you some background information so you understand what information is contained in an assembly file.
The actual low-level binary format of the files is documented (if you can call it that) by a couple of C header files on your system, which define C structures that exactly match up to the binary information in the PE files. You'll only really need this information if you're writing applications that do some sophisticated low-level processing of assemblies. But if you do, you should look in Windows.h for the structures of the PE headers, etc., and in CorHdr.h in the .NET Framework SDK for the structure of the CLR headers and code. In addition, many of the constants used for such things as flags are defined in the .NET Partition documents.
PE Files
The portable executable file is not something that is new to .NET. PE files have been around ever since 32-bit programming first emerged on the Windows platform with the release of NT 3.1. The statement that a file is a PE file means that it contains certain specified items in an agreed standard format.
A PE file does not only contain code: the file also contains information to indicate to Windows whether the code it contains represents a Windows form or a console application, or some other kind of application (such as a device driver). Furthermore, there may be pre-initialized data structures associated with the application. Other code may need to be brought in from libraries - a PE file needs to indicate which libraries, and it will also need to supply information about any functions it exposes to the outside world and the addresses in the file where they are located (these are technically known as its exports. All DLLs obviously have exports, and some .EXE files may do so too, for example to expose callback functions). Thus all in all, a PE file needs to supply a lot of data as well as code. The same principles hold true for other operating systems, although details of the data structures will be different. This means each operating system needs some agreed format for how data should be laid out in an executable file - what items are located where, so that the operating system knows where to look for them (strictly speaking, the format depends on the loader rather than the operating system, although in practice, formats are associated with operating systems). To that extent, the assembly format, with its manifests and metadata, hasn't introduced any fundamentally new principles - it's just added to the information already present.
On Windows, the agreed format is the PE format. There are, however, other formats around, such as Elf which is generally used on Unix.
The PE format uses indirection extensively - there are a few header fields at a fixed location early in the file, and these headers contain pointers indicating where other structures in the file are located. These structures in turn contain pointers, and so on until you get to the actual data and executable instructions that will be executed. One benefit of PE files is performance. They have been designed in such a way that they can be loaded into memory to a large extent as-is. There are a few modifications that need to be made to the copy of the file in memory (which we'll explain soon), but these are relatively small. For this reason, you'll also commonly hear PE files referred to as image files, or images, reflecting the idea that they can be thought of as file-based images of what sits in memory when the code actually runs.
The PE file format replaced several earlier formats for executable files on 16-bit Windows, and now essentially every executable, DLL, or static library file that runs on your system is a PE file. The "portable" in its name refers to the fact that this file is designed to run on any 32-bit version of Windows running on an x86-based processor. That's the remarkable feature that is quite often forgotten these days: the same files will execute on Windows 9x or on Windows NT/2000/XP, despite the fact that these are completely different operating systems with different underlying core code.
You may also see the PE file format referred to as the PE/COFF format. COFF stands for Common Object File Format, and COFF files, also known as object files, are produced as an intermediate stage in generating PE files from source code by compilers for languages such as C++. The C++ compiler works by first compiling each source code file as an isolated unit then matching up all the type definitions, etc. from the various source files - a process known as linking. The intermediate files are COFF files. COFF files contain executable code but are not ready to be executed because the data and code that is intended for one PE file is still spread across several files (typically one COFF file for each source code file). In order to ease the work required by the linker, Microsoft defined a common format for both PE and COFF files. This does mean, however, that there are a few fields in the PE/COFF format that are only relevant to COFF files, and which are therefore zeroed in PE files, and vice versa. Because of the indirection used in the PE/COFF file format though, the number of affected bytes in the file is very small.
At a very basic level, the PE file looks a bit like this. Note that what I'm presenting here is the basic PE format: the information here is processed by the Windows OS loader, so there's no data directed at the CLR - that part comes later.
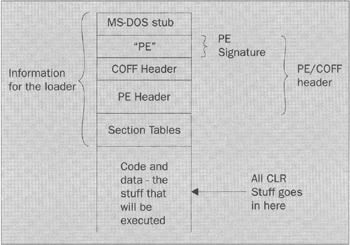
The diagram shows that the file contains a number of header structures, followed by the actual code and data. The initial structures - marked in the diagram as Information for the loader - are the stuff that the loader reads when Windows loads the file in order to determine - basically what to do with the file.
The MS-DOS stub is what will be executed if the program gets run under MS-DOS mode. For most PE files, and all assemblies, this is just a piece of code that displays a message telling you the file cannot be executed in MS-DOS mode. For a modern, GUI-based Windows file that's about all you can do. However, if the file is loaded by Windows, Windows knows not to just jump in and start executing the file from here. Instead, Windows goes straight to the following headers and starts processing them. For .NET assemblies, the ECMA standards for the CLI specify the actual values of the bytes to be placed in the MS-DOS stub, so all assemblies are identical in this regard.
The first item that Windows will process is the PE signature, which simply contains the two ANSI characters "PE". This simply tells Windows that this is really is a PE file, as opposed to a file in some other format.
Next comes the COFF header. Most of this data is not relevant for assemblies, and the COFF header occupies just 20 bytes anyway.
Things start to get interesting with the PE header. This contains some quite important information, including the lowest possible version number of the operating system that this file is intended to run on. The loader will abort loading the file if this version number is greater than that for the operating system actually running. The PE header also includes the Subsystem flag, which indicates whether the file should be run under Windows or the command prompt, or whether it is, for example, a device driver that has no user interface. Also embedded in the PE header is a structure known as the data directory table. This contains details of where to locate various tables of specific data in the PE file (two DWORDs respectively containing the size and a pointer to the start of each table). There are a number of tables here - some of the more interesting ones include:
-
Import table - this details unmanaged symbols, etc. that need to be imported from other files.
-
Export table - this indicates the unmanaged symbols that this file makes available to other files.
-
Resource table - contains details of unmanaged resources.
-
Thread Local Storage (TLS) table - this indicates details of data that is stored natively in thread local storage (note that this is separate from the parallel thread-local-storage facilities implemented by the CLR).
-
The Relocation Table - we'll explain this table soon. Roughly speaking, it lists the locations of words in the file that may need to be modified when the file is loaded into memory.
Notice that although these tables do contain information of relevance to an application, most of them are nevertheless geared towards unmanaged stuff. These tables don't, for example, contain any information about managed types imported or exported. And this really reflects the status of .NET. Perhaps one day, .NET will be a fully integrated part of Windows, but for the time being, .NET is in reality little more than an application that sits on top of Windows, acting as a layer between your managed code and Windows. The stuff we are looking at so far is standard PE header file contents, which Windows itself is expecting to process. Only when Windows has done its work in loading the file can control be handed over to the .NET Framework to execute the file.
The relocation table is quite interesting, as it gives some insight into how the file is actually loaded. So far we've been loosely talking about pointers to items in the file. Pointers used by the loader are generally stored as file offsets - in other words the number of bytes from the start of the file an item is located. (Actually, it's more complicated than this because the file gets loaded in sections that don't necessarily follow directly on from each other address-wise, due to constraints imposed by the disk operating system and the paging system. Corrections have to be made for this, but to keep things simple, we'll ignore that complication in the following discussion.) For example, if the file were always loaded at address zero in virtual memory, then calculating virtual memory addresses would be easy. Address 232 in the physical file for example would correspond to address 232 in the loaded image (ignoring file sections as just mentioned). But of course this never happens. When the file is loaded, its contents get placed at some address in the process's virtual address space, and that address is never zero. Executables are usually placed at location 0x400000 for example. This means that these offsets won't give the correct address of items used when the program is running. That's not really relevant for things like pointers to the import table as that information is only used while the file is being loaded.
What happens is that some default address is assumed for where the file is likely to be loaded - this assumed address is indicated in the PE header. Those addresses that are inside the executable code in the PE file that will be read when the program is running (such as pointers to pre-initialized memory) are stored in the file on the assumption that this address will be correct. However, if the file ends up getting loaded at a different location, then these addresses will need to be changed (this will happen to a DLL for example if another DLL has already been loaded at the preferred address). That's the purpose of the relocation table - it contains a list of which words in the file will need to be changed if the file gets loaded at the "wrong" address. Suppose your code contains an instruction to load some data, which has been hard-coded into the PE file X bytes from the start of the file. If the file is expected to be loaded at location Y, the instruction will have been coded up to say "load the data at virtual address X+Y". If, however, the file actually gets loaded at address Z, then Z-Y will have to be added to this address - the instruction must be changed to say "load the data at virtual address X+Z". Note that the target of branch instructions in x86 native executables is always given relative to the location of the branch instruction, just as in the IL br.* commands, so branch targets don't need to be relocated.
Finally, there is the actual data and code in the PE file. And that's where the CLR-specific data comes in. Once all the stuff that Windows consumes is out of the way, this is followed by stuff that the CLR can read and use to figure out the assembly structure and contents. And that's what we'll examine next.
PE Extensions for the CLR
We have come a long way into the file without really coming across much in the way of CLR-specific stuff. And there are really two reasons for that. One is backwards compatibility. There is much in PE files that Windows 95/98/ME/NT4/2K is expecting to see there. And short of .NET shipping with brand new loaders for unmanaged code, there's no realistic way Microsoft can muck around with that data. The other reason, as we've mentioned, is to do with the way that .NET really sits on top of Windows just like any other application.
File Structure
Since the code in an assembly or .NET module conforms to the PE file format, it shares the same header information as unmanaged executables and DLLs. However, beyond the PE header, the data structures are very different from an unmanaged file and contain information specific to the .NET Framework. Here is a fairly simplified impression of what the files look like:

As you can see, the structure of a module file is very similar to that of the prime module file. The sole difference is the inclusion of the assembly manifest in the prime module file. The manifest is what makes a file into an assembly. It contains the information that is needed to identify all the other files in the assembly, as well as the information that is needed by other external code (in other assemblies) in order to access the types in this assembly. Another way of looking at it is that a module file contains metadata that describes the types in that module. An assembly (prime module) file, however, contains the metadata that describes the types in its own module, as well as a manifest which details the other files that are part of the assembly and which types those modules make available to outside code (in other words, have public, family, or familyorassem visibility). By storing a copy of this information in the prime module, it means that other code that accesses this assembly only needs to open the one file in order to determine what types it can use, no matter which module actually implements those types, which improves performance. Obviously, if the external code actually needs to invoke code in one of the other modules, that's when the relevant file(s) will be opened.
But we're jumping ahead of ourselves. To go through the various items of CLR data in a more systematic way, the regions of the file contain the following:
-
The CLR header lists the version of the CLR that the assembly was built with and designed to work with. Among other things, it also indicates the managed entry point (if this is an executable assembly) and the addresses of other items of data, including the strong name signature (if present) and the table of the vtfixups that are used to indicate addresses for managed methods that are exported as unmanaged code.
-
The Manifest contains details of all files that make up this assembly, along with a copy of any metadata from other modules that are externally visible. The manifest is also important because it contains details of the identity of this assembly - the name, version, etc., as well as a hash of the combined contents of all the files in the assembly, from which file integrity can be verified. Basically, the manifest contains all the information needed to identify and describe this assembly to the outside world.
-
The Metadata is the data that defines all the types used in a given module. To a first approximation, it contains the information that is given in IL directives (as opposed to IL opcodes). It details the types defined in the module, as well as the member methods and fields of each type. For each method, it will also indicate the start point and length of the IL instruction stream for that method within the file (a consequence of this is that there is no need to embed any method header information within the instruction stream itself - that data can be found in the metadata). The metadata will also contain any string constants and details of which types and methods in other modules or assemblies are required by the code in this module.
-
The IL Code shouldn't need any explaining. It is quite simply the stream of IL instructions that make up the actual code to be JIT-compiled in the assembly.
How the CLR is Invoked
We've just reviewed the main items of data in the assembly that need to be processed by the CLR. But there's a problem. The PE file is loaded by Windows, not by the CLR. So how does the CLR get involved? The answer depends on what version of Windows you are running. For Windows 2000 and earlier versions of Windows, Windows simply loads the file as normal, quite unaware that it is a managed file, and locates an (unmanaged) entry point, which will be specified in one of the fields in the PE/COFF headers. Once Windows has satisfied itself that it has loaded and initialized the file correctly, it has the appropriate thread of execution start running at this unmanaged entry point. However, in all managed assemblies, the code that is placed here is little more than a call into the library mscoree.dll (the EE presumably stands for "Execution Engine"). This DLL is responsible for loading and hosting the CLR. Once the thread of execution is inside mscoree.dll, that's it. The CLR is now in charge, and will start reading through the manifest, metadata, and IL code in your file, and processing it, starting with wherever the 'real' managed entry point is. A rather intriguing consequence of this is that all the IL code, which you and I think of as "code", actually has the status of "data" as far as Windows is concerned. Windows never directly executes this code, obviously - instead it's read and processed by the (native) code inside mscoree.dll. Note also that these few unmanaged instructions at the start have no effect on the verifiability of your code, and the assembly doesn't need permission to execute unmanaged code in order to run this code - for the simple reason that at the point in time when this code is being executed, the CLR hasn't even been started. Clearly, until that initial call into mscoree.dll is made, there can be no verification or other .NET security checks!
In the case of assemblies generated by the C++ compiler, the startup procedure is somewhat complicated by the fact that the C++ compiler adds its own unmanaged Main() method, which is responsible for tasks such as initializing the C runtime library. The result is a curious hopping from unmanaged code into mscoree.dll (though at this point still executing unmanaged code to initialize the .NET environment) then back into unmanaged code in the assembly - and finally back into mscoree.dll where the code that starts JIT-compiling your managed entry point will start running.
If your assembly is running on Windows XP, the same principles hold, except that the initial unmanaged stub in the assembly is not executed. That's because Windows XP was developed at about the same time as .NET, which means Microsoft was able to modify the PE file loader in Windows XP to explicitly check to see if this is a managed PE file, and if so to call the startup code in mscoree.dll directly. The check is made by examining a field in the PE header called IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR. It happens that this field is not used and is always zero in unmanaged PE files. Microsoft has defined this field to be non-zero in managed assemblies - and the rest should be obvious. The benefit of this is that no managed code needs to be executed and the CLR's code access security mechanism is active from the start. This allows administrators to lock down a system more effectively, and prevents any viruses that may infect the unmanaged entry point from executing.
Verifying File Integrity
We won't worry too much about the details of how file integrity is verified here, since we cover that topic in Chapter 13. However, for completeness we'll remind ourselves of the basic idea. A hash of the entire assembly is computed and stored in the manifest. You can think of the hash as being a bit like those old cyclic redundancy checks, but a lot more sophisticated. The hash is some number that is calculated by applying some mathematical formula to the data in the files that make up the assembly. The important point is that every single byte in every file in the assembly is used in computing the hash - so if any corruption to even one byte happens, then it's virtually certain that the hash computed from the corrupted file won't match the one that the uncorrupted file would have produced. So checking the value of this hash should for all practical purposes guarantee file integrity against random corruption. In addition, in assemblies that have a strong name, the hash is signed (encoded) using the assembly's private key, which is known only to the company that supposedly coded up the assembly. Since no one else can encrypt the hash with that key, a successful decryption and matching of the hash proves that the file was produced by the correct company, and so hasn't been deliberately tampered with.
The IL Instruction Stream
When we looked at IL assembly in 2, we got quite a good idea of what the CLR can actually do with your program and how the IL language works. However, because we were dealing with assembly language, we didn't get much idea at all of how the genuine IL binary data is stored in an assembly. That's what we'll examine here. In the process, we'll also see some of the other ways that the assembly has been designed with performance in mind.
Don't confuse IL assembly (the textual IL source code) with assemblies (the binary files)! You might wonder whatever possessed Microsoft to call the unit of managed code storage an assembly, when (ironically) the one IL-related thing it does not contain is IL assembly!
Let's consider this IL assembly code sequence:
ldstr "Hello, World!" call [mscorlib]void System.Console::WriteLine(string)
In the IL source file, all the items needed to understand this code are presented inline - including that "Hello, World! " string. However, that's not how it works in the assembly. Once assembled into opcodes, the above lines look more like this:
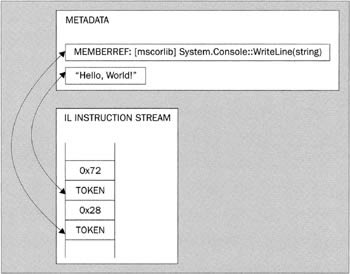
Understanding this diagram will probably be easier if I mention that 0x72 happens to be the opcode for ldstr, while 0x28 is the opcode for call. (Actually, it'd probably be more correct to say that ldstr is the mnemonic for 0x72 and so on, but you get the picture.)
The two opcodes are each followed by a token. As mentioned in Chapter 1, these tokens are essentially four-byte numbers that index into some table into the metadata. The diagram illustrates the use of two such tables: the string "Hello, World! " is contained in a table of strings, while the method Console.WriteLine() is contained in a table of what are known as MemberRefs - references to methods in other assemblies. In fact, the MemberRef entry itself basically consists of a number of tokens to such items as a TypeRef (which will identify the Console type) and a SignatureRef (which indicates the signature of a method).
There are a couple of reasons why it's done this way:
-
Space - it's quite likely that the Console.WriteLine() method is going to be called from more than one location. If details of this method had to be repeated, that would bloat the assembly.
-
Performance - if the JIT compiler is to process the IL instructions quickly then it's important that it knows exactly how many bytes are going to be taken up with each instruction. If an instruction had to be followed by a MethodRef or by a string, there would be the complicating factor of sorting out exactly how many bytes are occupied by the argument to the instruction. But since the ldstr and call instructions are followed by four-byte tokens, the JIT compiler immediately knows just from inspecting the opcode how many bytes will follow as an argument and how to interpret those bytes.
-
Metadata - one of the principles of assemblies is that the assembly is self-describing. That means not only that the information about the types used in the assembly is readily available, but also information about types referenced, and so on. By placing the MethodDef in the metadata, this principle is ensured.
It's apparent from the design of the IL instruction stream and the metadata that Microsoft was very concerned about performance - the indirect indexing method using tokens provides one example of this. Another example is the way that the opcodes are designed. The majority of opcodes consume one byte; this means that examining that one byte of data is sufficient to tell the JIT compiler what the instruction is and how many bytes of argument follow. However, the infrequently used instructions are two bytes in length. For these instructions, the first byte is always 0xFE, so the JIT compiler knows that if it reads a byte and sees this value, then it needs to read the next byte to determine what the instruction is. Conversely, having all the rarely used instructions have the same first byte reduces the number of values that that first opcode byte needs to be tested for, making it faster to process the more common instructions. It also means we are allowing for future expansion if IL were to contain more than 256 instructions. However, keeping all the commonly used instructions as one byte each keeps assembly file size down to a minimum, reducing load time and - more significantly - reducing download time if the assembly is to be downloaded.
Metadata Tables
So far we've seen an example that illustrated the tables of strings and of MemberRefs. There are actually quite a few standard tables in the metadata - more than 40 of them in fact, all stored in a highly compressed format, and having such names as MethodDef, TypeDef, TypeRef, MethodPtr, AssemblyRef, etc. The last three letters of each name give a clue about where entries in the table refer. Def means that it's a table of items that are defined in this assembly - which clearly means the metadata will need to supply the complete definitions. Ref indicates that it is a reference to something that is fully defined in another assembly - which means that the data in this assembly needs only to contain enough information to identify where the full definition can be found. However, the data in this assembly does contain sufficient information, such as the signatures of methods, to allow the JIT compiler to perform basic type and verifiability checking without actually having to load the other assembly. A name ending in Ptr indicates some reference to another item in this assembly. Ptr items aren't found in well-organized assemblies - they exist to sort out the problems that can occur if types are (for example) referenced before being fully defined - their function is analogous to forward declarations in C++. Write your IL code carefully and you won't get any Ptr items in your assembly.
Full details of the various tokens are listed in Partition II. However, just so you are familiar with some of the terms in use, some of the more important tables in the metadata are listed here:
| Table Name | Meaning | ||
|---|---|---|---|
| Def type | Ref type | Ptr Type | Defines or identifies.. |
| MethodDef | MethodPtr | A method | |
| TypeDef | TypeRef | A type - class, struct, enum, etc. | |
| AssemblyDef | AssemblyRef | The current assembly, or a referenced assembly | |
| ParamDef | ParamPtr | A parameter to a method | |
| FieldDef | FieldPtr | A fields in a type |
For the actual tokens used in arguments in the IL instruction stream, certain high-value bits in each argument indicate which table the token refers to, the remaining bits indicating the index in the table. For example, if the highest order byte in a token is 0x06 then the JIT compiler knows it's a MethodDef, while 0x0A indicates a MemberRef. Since we're not going into the binary details in this book, we won't worry about which bit means what, but again the information is available in the Partition II document if you need it. Note that in many cases these high order bits are redundant. For example, the token that follows the ldstr opcode can only ever refer to a string, while that following call or callvirt can only refer to either a MethodDef or a MemberRef.
Version Robustness
We'll finish off our discussion of the file structure of executable modules with an observation about version robustness. You'll no doubt be familiar with the point that assemblies do away with DLL-hell because they allow assemblies with different versions to exist side by side. There's actually another way that assemblies help to ensure version robustness, which is quite clever, and falls naturally out of the way metadata works, but is nevertheless not so commonly publicized. Think about what happens if you bring out a new version of a DLL assembly, in which you've added some new fields and methods to a type. You ship this assembly, and various existing applications for whatever reason, shift to use the new version of your assembly. Now in the old unmanaged DLL days, adding fields could kill application compatibility straight away unless you took care to add them at the end of the class definition. That's because existing fields would otherwise probably be moved to new offsets within the data structures so any client code that accessed fields as offsets against the address of an instance of a type would break dramatically. However, that can't happen in managed code because assemblies will refer to types and fields, etc. in other assemblies (in MemberRefs and TypeRefs) by name. That means that the locations of fields are resolved at run time by the .NET loader and the JIT compiler, so it doesn't matter if the layout of a class changes - the correct fields will always be accessed (provided of course you don't write unsafe code that uses pointer arithmetic to calculate field locations).
Resources and Resource Files
Finally, we need to consider the remaining type of file that can be part of an assembly: the resource file, which contains managed resources (and which should be distinguished from unmanaged resources, which are also available to assemblies just as they are to unmanaged PE files).
A resource simply means any data - other of course than the executable code and metadata - that forms part of an assembly. This means that .NET resources can include for example, strings, bitmaps, icons, etc. - in fact, any binary or textual data that is required by an assembly. A resource can even contain simple numeric types. An important reason for using resources is the issue of localization - the ability of an application to call up different sets of resources (notably strings) according to the language it is running in. The idea is that porting an application should not require any changes in the actual code for the program - all language dependencies should be confined to the resources, so all that is needed is to load up a different set of resources at run time. We'll save examining the question of how the .NET resource model supports localization until later in the chapter. For now, we'll focus on the principles of how resources can be included in an assembly.
Linking or Embedding
In fact, there are two situations that we need to consider, and only one of these involves a separate resource file:
-
Resources can be embedded in a PE file.
-
Resource files can be linked to an assembly as separate files.
The case for which a resource file is linked as a separate file is conceptually the easiest case to understand, although in programmatic terms it is the least powerful model. The resource file can be literally any file - for example, a text file or a bitmap file. There are no restrictions on the file format. However, the lack of restrictions on the file format means that there can be very little in-built .NET support for processing such resources. Linking a resource file will typically be done using the /linkresource option of the assembly linker utility, al.exe.
All that happens when linking a file is that details of the file name are placed in the assembly manifest and the hash of the assembly contents is of course calculated to incorporate the linked file. However, the linked file itself is not modified. In practical terms, basically what you have is a separate file shipped with your assembly, but with the hash used as an extra check that the contents of this file have not been corrupted. The easiest way to load the data in such a file at run time is still to treat it as if it were an independent file; for example by calling Bitmap.Loadlmage(<filename>) for a bitmap, or using the StreamReader class for a text file. If you have files such as bitmaps or text files that you wish to ship with your code and are not modified at run time, then linking them to the assembly in this way is probably a good idea simply because of the extra file integrity check you will get.
Embedding a resource inside an assembly PE file has a disadvantage that the resource will automatically be loaded along with the code in that file - so there is less flexibility in terms of being able to delay loading the data until that data is actually required. However, the advantage you gain is a much more powerful programming model. The .NET Framework provides for a standard format in which resources can be embedded. This format is supported by various classes in the System.Resources namespace, notably ResourceManager, which is able to read the data embedded in an assembly.
In high-level terms, the format for a resource embedded in an assembly might look something like this:
| Type: String | Name: Greeting | Value: "Hello, World" |
| Type: Boolean | Name: DrivesOnLeftSideOfRoad | Value: True |
| Type: Bitmap | Name: NationalFlag | Value: <Binary data> |
The key point to note is that this format includes details of the type of object that each lump of data represents. You can probably guess what this means. Taking the above data as an example, you tell the resource manager to read the resource called Greeting from the table, and you get back a string that contains the value "Hello World". You tell the resource manager to read the resource called "NationalFlag", and you get a bitmap back. The code looks a bit like this in C#:
// thisAssetnbly is a reference to the current executing assembly ResourceManager resMan = new ResourceManager("MyFirstResourceSet", thisAssembly); string greetingText = (string)resMan.GetObject("Greeting"); Bitmap diagram = (Bitmap)resMan.GetObject("NationalFlag");
I'm sure you can figure out for yourself the potential for embedding objects in your assembly that is encapsulated by this programming model.
By the way, for the particular case of strings, the ResourceManager class offers a simpler way of getting at the data:
string greetingText = resMan.GetString("Greeting") ; The actual format of the data in the assembly is compact and fairly natural. The header information that identifies the resource is followed by the names of the items in the resource and their data types, stored as strings. Then the actual values follow as binary blobs, which can in many cases be loaded directly into memory to represent the object values.
There is also the case in which simple data, such as individual strings or blobs, are embedded in the assembly using the ldstr command or the .data directive in IL. We're not considering that situation here - here we are looking at the case where items are stored in the format that is supported by the .NET resource infrastructure.
Managed versus Unmanaged Resources
It's important to understand that managed resources are not the same as unmanaged resources. The model used for resources in the .NET Framework is considerably enhanced compared to the facilities offered by Windows for unmanaged resources. Before the days of .NET, support for resources was available through various API functions, which were concerned with specific types of data including:
-
Bitmaps
-
Menus
-
String tables
-
Accelerator tables
-
Icons
-
Cursors
For example, if you wished to use a bitmap, you could either have the bitmap stored in a separate file, or you could embed it as a resource in the PE file itself. In both cases you would use the API function LoadImage() to actually load the bitmap and create a handle by which your code could reference the bitmap. The parameters passed to LoadImage() would indicate whether the bitmap was to be obtained from a file or as a resource.
Whereas unmanaged resources are embedded in the PE file in a manner that is known and recognized by Windows, managed resources are described in the assembly metadata and are therefore recognized only by the CLR. As far as Windows is concerned, the managed resources are just another block of opaque data in the PE file. A side effect of this is that it's perfectly legitimate to embed both managed and unmanaged resources in the same assembly. An obvious example of this is that if you want a custom icon to be associated with your application and displayed by Windows Explorer, you'd need to embed it as an unmanaged resource since Windows Explorer at present is unable to read managed resources. The use of unmanaged resources is supported by the main MS compilers (see for example the /win32res flag in C# and the /win32resource flag in VB), though there is little specific built-in support in VS.NET, other than within unmanaged C++ projects.
Once you've got used to the flexibility provided by managed resources, it is probably fairly unlikely that you will want use unmanaged resources anyway, apart from legacy compatibility reasons - simply because the managed resource model is so much more powerful:
-
If you want to store resources in separate files, then maintaining them as linked managed resource files means you get the automatic file integrity checking for free. For unmanaged resources, there is no support for this - if you want to use this technique, you just have to supply the file separately as a completely independent file.
-
If you want to embed resources in the assembly PE file, then the format for managed resources allows you to embed and instantiate a large number of types from managed resources - and to use a very simple but powerful programming model to instantiate that data as the appropriate managed types.
-
If the CLR gets ported to other platforms, then this opens up the possibility of platform-independent resources.
We also ought to add localization to the above list. Windows does offer support for localization of unmanaged resources, but as we'll see soon the localization model offered by the .NET Framework for managed resources that are embedded into a PE file really does make localizing applications incredibly simple in concept (although the implementation details can still get a bit hairy).
As you can probably imagine, there is a fairly sophisticated API to support generation of managed resources. This API comes partly from classes in the System.Resources namespace (of which ResourceManager is only one of a number of classes), and partly from some command-line utilities (which are for the most part implemented internally using these same classes!), as well as some intrinsic support for managed resources in Visual Studio .NET. We'll see a lot more about managed resources later in the chapter.
EAN: 2147483647
Pages: 124