Section 3.3. Language and Representation
3.3. Language and RepresentationWords intended to represent concepts: that is the questionable foundation upon which information retrieval is built. Words in the content. Words in the query. Even collections of images and software and physical objects rely on words in the form of metadata for representation and retrieval. And words are imprecise, ambiguous, indeterminate, vague, opaque; you get the picture. Our language bubbles with synonyms, homonyms, acronyms, and even contronyms (words with contradictory meanings in different contexts such as sanction, cleave, and bi-weekly). And this is before we even talk about the epic numbers of spelling errors committed on a daily basis. In The Mother Tongue, author Bill Bryson shares a wealth of colorful facts about language, including:
Interestingly, when this ambiguity of language is subjected to statistical analysis, familiar patterns indicative of power laws , shown in Figure 3-3, emerge. First observed by the Italian economist Vilfredo Pareto in the early 1900s, power laws result in many small events coexisting with a few large events. Later summed up as Pareto's Principle or the 80/20 Rule, power laws have since been applied to a wide variety of phenomenon including wealth disparity (80% of money is earned by 20% of the population), scientific publishing (a small number of journals contribute the vast percentage of scientific output), and web site popularity (80% of links on the Web point to only 15% of web pages).[*]
Figure 3-3. Bell curves and power laws (image adapted from Barabasi, p.71)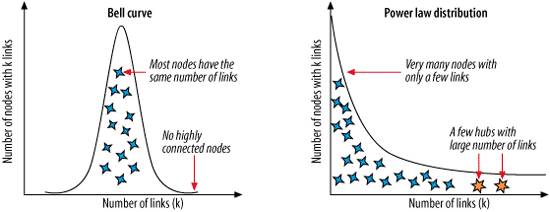 Bell curves and not power laws are the norm in nature. If human height followed a power law distribution, most of us would be really short, but at least one of us would be over 8,000 feet tall.[*] Power laws only show up in complex networks that exhibit self-organization and emergent behavior. Language happens to be one of these networks, and the implications for retrieval are significant.
The most famous study of power laws in the English language was conducted by Harvard linguistics professor George Kingsley Zipf in the early 1900s. By analyzing large texts, Zipf found that a few words occur very often and many words occur very rarely. The two most frequent words can account for 10% of occurrences, the top six for 20%, and the top 50 for 50%. Zipf postulated this occurred as a result of competition between forces for unification (general words with many meanings) and diversification (specific words with precise meaning). In the context of retrieval, we might interpret these as the forces of description and discrimination.[
The upshot of all this analysis is that while recall fails fastest, precision also drops precipitously as full-text retrieval systems grow larger. In the "computing" example that follows, the larger system returns too many results with too many meanings. Without asking the user to add keywords, use Boolean operators, or specify context, there's no way for the system to know which meaning the user intends. This problem is further amplified by the fact that when we enter "computing" as a keyword, we're generally looking for documents about computing and not just documents that contain the word computing. Though relevance ranking algorithms can factor in the location and frequency of word occurrence, there is no way for software to accurately determine aboutness.
That's where metadata enters the picture. Metadata tags applied by humans can indicate aboutness thereby improving precision. This is one of Google's secrets for success. Google's PageRank algorithm recognizes inbound links constructed by humans to be an excellent indicator of aboutness. Google loves metadata. Controlled vocabularies (organized lists of approved words and phrases) for populating metadata fields can further improve precision through their discriminatory power. And the specification of equivalence, hierarchical, and associative relationships can enhance recall by linking synonyms, acronyms, misspellings, and broader, narrower, and related terms, as shown in Figure 3-4. Controlled vocabularies help retrieval systems to manage the challenges of ambiguity and meaning inherent in language. And they become increasingly valuable as systems grow larger. Unfortunately, centralized manual tagging efforts also become prohibitively expensive and time-consuming for most large-scale applications. So they often can't be used where they're needed the most. For all these reasons, information retrieval is an uphill battle. Sometimes we do make progress. Google's multi-algorithmic approach that combines full text, metadata, and popularity measures is the most striking example in recent years. But don't hold your breath for similar break throughs. Despite the hype surrounding artificial intelligence, Bayesian pat- Figure 3-4. A thesaurus is a special type of controlled vocabulary that specifies equivalence, hierarchical, and associative relationships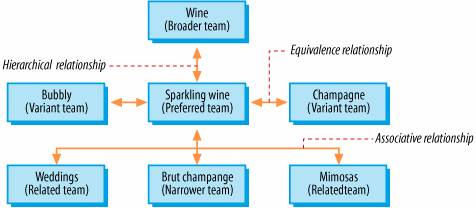 tern matching, and information visualization, computers aren't even close to extracting or understanding or visually representing meaning. For as long as humans use language to communicate, information retrieval will be remain a messy, imperfect business. But before you despair about the sorry state of information retrieval and its implications for search on your web site or intranet, take a deep breath and sit down. Because it gets worse. Much, much worse. Remember Calvin Mooers and his pesky law about the pain of having information? Well, he was onto something far more formidable and irksome than the ambiguity in language. Calvin Mooers was onto the people problem. |
 ] The force of description dictates that the intellectual content of documents should be described as completely as possible. The force of discrimination dictates that documents should be distinguished from other documents in the system. Full text is biased towards description. Unique identifiers such as ISBNs (and Zip Codes) offer perfect discrimination but no descriptive value. Metadata fields (e.g., title, author, publisher) and controlled vocabularies (e.g., subject, category, format, audience) hold the middle ground.
] The force of description dictates that the intellectual content of documents should be described as completely as possible. The force of discrimination dictates that documents should be distinguished from other documents in the system. Full text is biased towards description. Unique identifiers such as ISBNs (and Zip Codes) offer perfect discrimination but no descriptive value. Metadata fields (e.g., title, author, publisher) and controlled vocabularies (e.g., subject, category, format, audience) hold the middle ground.EAN: 2147483647
Pages: 87