Section 3.2. Information Retrieval
3.2. Information RetrievalWhen Calvin Mooers coined the term "information retrieval" in 1948, Hollerith (IBM) punch cards were the state of the art. First invented in 1896 by Henry P. Stamford, these edge-notched punch cards enabled people to search insurance records and library collections by metadata. Each notch constituted a descriptor (also known as an index term or metadata tag). In early versions, the user would thread a 16 inch needle through a stack of cards. The relevant notched cards would drop from the collection. A subsequent search of this result set enabled further narrowing (the Boolean AND). Non-relevant cards retrieved by this process were called "false drops," a term we still use today. To those of us living in the age of Google, the world of punch cards seems distant and quaint. In fact, things have happened so fast in recent years, even 1993 seems like a lifetime ago. Back then, I was learning "online searching" at the University of Michigan's School of Information and Library Studies. We searched through databases via dumb terminals connected to the Dialog company's mainframe. Results were output to a dot matrix printer. And Dialog charged by the minute. This made searching quite stressful. Mistakes were costly in time and money. So, we'd spend an hour or more in the library beforehand, consulting printed thesauri for descriptors, considering how to combine Boolean operators most efficiently, and plotting our overall search strategy. A computer's time was more precious than a human's, so we sweated every keyword. Meanwhile, NCSA was developing the first graphical, multimedia interface to the World Wide Web, released as the Mosaic web browser in 1993. This killer application launched the Internet revolution that transformed our relationship with information systems. A browser for every desktop. A web site for every company. Billions of pages searchable via Google. For free. And hundreds of millions of untrained users searching for digital cameras, scientific papers, uncensored news, and photos of Britney Spears. The technology and context for retrieval changed radically. And yet, the central challenges and principles of information retrieval, forged in the decades between punch cards and web browsers, remain valid and important. And because they derive from the fundamental nature of language and meaning, they are unlikely to change anytime soon. At the heart of these challenges and principles lies the concept of relevance. Simply put, relevant results are those which are interesting and useful to users. Precision and recall, our most basic measures of effectiveness, are built upon this common-sense definition, as shown in Figure 3-2. Precision measures how well a system retrieves only the relevant documents. Recall measures how well a system retrieves all the relevant documents. The relative importance of these metrics varies based on the type of search. For the sample search in which a few good documents are sufficient, precision outweighs recall. Most Google searchers, for example, want a few good results fast without sifting through false drops. Precision is even more important for the known-item or existence search in which a specific document (or web site) is desired. In fact, this type of search has more in Figure 3-2. Definitions of precision and recall common with data retrieval than information retrievalbecause there is a single, correct answer. But for the exhaustive search when all or nearly all relevant documents are desired, recall is the key metric. Lawyers and researchers are willing to sacrifice precision in the interest of finding the smoking gun or the data that makes a difference. Of course, recall is tricky to measure because it requires a count of the total number of relevant documents in a collection: not so hard with a few hundred punch cards but pretty tough with several billion web pages. This brings us to the subject of scale. In information retrieval, size matters, and we only learned recently how much. Through the 1960s and 70s, when the first full-text search systems were developed, experiments using IBM's Storage and Information Retrieval System (STAIRS) showed both precision and recall to run as high as 75 to 80%. This made IBM very happy and fueled predictions about the end of metadata. Why spend time and money having humans apply index terms when automatic full-text retrieval worked as well or better? Fire your librarians. Buy IBM. The future is automated. Unfortunately, there was a fatal flaw in the experiments. They were conducted on small collections of a few hundred documents, and the assumption that these results applied to large collections was mistaken. In the 1980s, researchers David C. Blair and M.E. Maron evaluated a large, operational full-text litigation support system containing roughly 40,000 documents with 350,000 pages of text.[*] The lawyers using this system regarded 75% recall as essential to defense of the case, and believed the system met that standard. But Blair and Maron showed that while precision remained high (around 80%), recall averaged a miserable 20%. The system was retrieving only 1 of 5 relevant documents. And this was with trained searchers! This exceptionally large and rigorous study exposed a fundamental challenge: recall falls dramatically as the collection increases in size.[
|
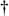 ] And since the holdings of many web sites, intranets, and digital collections far exceeds 40,000 documents, these findings are clearly relevant today. Size matters. Big time. But why? And what happens in larger collections of 400,000 or 4,000,000 documents? Does precision remain high? Does recall drop further? For those answers, we must turn to the complex adaptive network we call language.
] And since the holdings of many web sites, intranets, and digital collections far exceeds 40,000 documents, these findings are clearly relevant today. Size matters. Big time. But why? And what happens in larger collections of 400,000 or 4,000,000 documents? Does precision remain high? Does recall drop further? For those answers, we must turn to the complex adaptive network we call language. ] Due to the need for researchers to manually evaluate the relevance of large numbers of documents, this study cost (adjusted for inflation) over a million dollars. Needless to say, few retrieval experiments of this scale have been conducted since.
] Due to the need for researchers to manually evaluate the relevance of large numbers of documents, this study cost (adjusted for inflation) over a million dollars. Needless to say, few retrieval experiments of this scale have been conducted since.EAN: 2147483647
Pages: 87