Integrity Constraints
Some people refer to integrity constraints as business rules. However, business rules is a much broader concept; it includes all of the constraints on the system rather than just the constraints concerning the integrity of the data. In particular, system security—that is, the definition of which users can do what and under what circumstances they can do it—is part of system administration, not data integrity. But certainly security is a business requirement and will constitute one or more business rules. We'll look at database security issues in Chapter 8 when we discuss system administration.
Data integrity is implemented at several levels of granularity. Domain, transition, and entity constraints define the rules for maintaining the integrity of the individual relations. Referential integrity constraints ensure that necessary relationships between relations are maintained. Database integrity constraints govern the database as a whole, and transaction integrity constraints control the way data is manipulated either within a single database or between multiple databases.
Domain Integrity
As we discussed in Chapter 1, a domain is the set of all possible values for a given attribute. A domain integrity constraint—usually just called a domain constraint—is a rule that defines these legal values. It might, of course, be necessary to define more than one domain constraint to describe a domain completely.
A domain isn't the same thing as a data type, and defining domains in terms of physical data types can backfire. The danger is that you will unnecessarily constrain the values—for example, by choosing an integer because you think it will be big enough rather than because 255 is the largest permitted value for the domain.
That being said, however, data types can be a convenient shorthand in the data model, and for this reason choosing a logical data type is often the first step in determining the domain constraints in a system. By logical data type, I mean "date," "string," or "image," nothing more specific than that. Dates are probably the best example of the benefits of this approach. I recommend against defining the domain TransactionDate as DateTime, which is a physical representation. However, defining it as "a date" allows you to concentrate on it being "a date between the commencement of business and the present date, inclusive" and ignore all those rather tedious rules about leap years.
Having chosen a logical data type, it might be appropriate to define the scale and precision of a numeric type, or the maximum length of string values. This is very close to specifying a physical data type, but you should still be working at the logical level. Obviously, you will not be hit by lightning if your particular shorthand for "a string value of no more than 30 characters" is char(30). But the more abstract you keep the description in the data model, the more room you'll have to maneuver later and the less likely you'll be to impose accidental constraints on the system.
The next aspect of domain integrity to consider is whether a domain is permitted to contain unknown or nonexistent values. The handling of these values is contentious, and we'll be discussing them repeatedly as we examine various aspects of database system design. For now, it's necessary to understand only that there is a difference between an unknown value and a nonexistent value, and that it is often (although not always) possible to specify whether either or both of these is permitted for the domain.
The first point here, that "unknown" and "nonexistent" are different, doesn't present too many problems at the logical level. (And please remember, always, that a data model is a logical construct.) My father does not have a middle name; I do not know my next-door neighbor's. These are quite different issues. Some implementation issues need not yet concern us, but the logical distinction is quite straightforward.
The second point is that, having determined whether a domain is allowed to include unknown or nonexistent values, you'll need to decide whether either of these values can be accepted by the system. To return to our TransactionDate example, it's certainly possible for the date of a transaction to be unknown, but if it occurred at all it occurred at some fixed point in time and therefore cannot be nonexistent. In other words, there must be a transaction date; we just might not know it.
Now, obviously, we can be ignorant of anything, so any value can be unknown. That's not a useful distinction. What we're actually defining here is not so much whether a value can be unknown as whether an unknown value should be stored. It might be that it's not worth storing data unless the value is known, or it might be that we can't identify an entity without knowing its value. In either case, you would prevent a record containing an unknown value in the specified field from being added to the database.
This decision can't always be made at the domain level, but it's always worth considering since doing so can make the job a little easier down the line. To some extent, your decision depends on how generic your domains are. As an example, say that you have defined a Name domain and declared the attributes GivenName, MiddleName, Surname, and CompanyName against it. You might just as well have defined these attributes as separate domains, but there are some advantages to using the more general domain definition since doing so allows you to capture the overlapping rules (and in this case, there are probably a lot of them) in a single place. However, in this case you won't be able to determine whether empty or unknown values are acceptable at the domain level; you will have to define these properties at the entity level.
The final aspect of domain integrity is that you'll want to define the set of values represented by a domain as specifically as possible. Our TransactionDate domain, for example, isn't just the set of all dates; it's the set of dates from the day the company began trading until the current date. It might be further restricted to eliminate Sundays, public holidays, and any other days on which the company does not trade.
Sometimes you'll be able to simply list the domain values. The domain of Weekends is completely described by the set {"Saturday", "Sunday"}. Sometimes it will be easier to list one or more rules for determining membership, as we did for TransactionDate. Both techniques are perfectly acceptable, although a specific design methodology might dictate a particular method of documenting constraints. The important thing is that the constraints be captured as carefully and completely as possible.
Transition Integrity
Transition integrity constraints define the states through which a tuple can validly pass. The State-Transition diagram in Figure 4-1, for example, shows the states through which an order can pass.
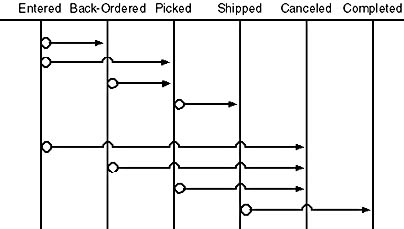
Figure 4-1. This diagram shows the states through which an order can pass.
You would use transitional integrity constraints, for instance, to ensure that the status of a given order never changed from "Entered" to "Completed" without passing through the interim states, or to prevent a canceled order from changing status at all.
The status of an entity is usually controlled by a single attribute. In this case, transition integrity can be considered a special type of domain integrity. Sometimes, however, the valid transitions are controlled by multiple attributes or even multiple relations. Because transition constraints can exist at any level of granularity, it's useful to consider them a separate type of constraint during preparation of the data model.
For example, the status of a customer might only be permitted to change from "Normal" to "Preferred" if the customer's credit limit is above a specified value and he or she has been doing business with the company for at least a year. The credit limit requirement would most likely be controlled by an attribute of the Customers relation, but the length of time the customer has been doing business with the company might not be explicitly stored anywhere. It might be necessary to calculate the value based on the oldest record for the customer in the Orders relation.
Entity Integrity
Entity constraints ensure the integrity of the entities being modeled by the system. At the simplest level, the existence of a primary key is an entity constraint that enforces the rule "every entity must be uniquely identifiable."
In a sense, this is the entity integrity constraint; all others are technically entity-level integrity constraints. The constraints defined at the entity level can govern a single attribute, multiple attributes, or the relation as a whole.
The integrity of an individual attribute is modeled first and foremost by defining the attribute against a specific domain. An attribute within a relation inherits the integrity constraints defined for its domain. At the entity level, these inherited constraints can properly be made more rigorous but not relaxed. Another way of thinking about this is that the entity constraint can specify a subset of the domain constraints but not a superset. For example, an OrderDate attribute defined against the TransactionDate domain might specify that the date must be in the current year, whereas the TransactionDate domain allows any date between the date business commenced and the current date. An entity constraint should not, however, allow OrderDate to contain dates in the future, since the attribute's domain prohibits these.
Similarly, a CompanyName attribute defined against the Name domain might prohibit empty values, even though the Name domain permits them. Again, this is a narrower, more rigorous definition of permissible values than that specified in the domain.
NOTE
Designers often specify the validity of empty and unknown values at the entity level rather than the domain level. In fact, some designers would argue that these constraints apply only at the entity level. There is some justification for this position, but I recommend making the domain definition as complete as possible. Certainly, considering empty and unknown values at the domain level does no harm and can make the process of specification (and implementation) simpler.
In addition to narrowing the range of values for a single attribute, entity constraints can also effect multiple attributes. A requirement that ShippingDate be on or after OrderDate is an example of such a constraint. Entity constraints can't reference other relations, however. It wouldn't be appropriate, for example, to define an entity constraint that sets a customer DiscountRate (an attribute of the Customer relation) based on the customer's TotalSales (which is based on multiple records in the OrderItems relation). Constraints that depend on multiple relations are database-level constraints; we'll discuss them later in this chapter.
Be careful of multiple-attribute constraints; they might indicate that your data model isn't fully normalized. If you are restricting or calculating the value of one attribute based on another, you're probably OK. An entity constraint that says "Status is not allowed to be 'Preferred' unless the Customer record is at least one year old" would be fine. But if the value of one attribute determines the value of another—for example, "If the customer record is older than one year, then Status = 'Preferred'"—then you have a functional dependency and you're in violation of third normal form.
Referential Integrity
In Chapter 3, we looked at the decomposition of relations to minimize redundancy and at foreign keys to implement the links between relations. If these links are ever broken, the system will be unreliable at best and unusable at worst. Referential integrity constraints maintain and protect these links.
There is really only one referential integrity constraint: foreign keys cannot become orphans. In other words, no record in the foreign table can contain a foreign key that doesn't match a record in the primary table. Tuples that contain foreign keys that don't have a corresponding candidate key in the primary relation are called orphan entities. There are three ways orphan entities can be created:
- A tuple is added to the foreign table with a key that does not match a candidate key in the primary table.
- The candidate key in the primary table is changed.
- The referenced record in the primary table is deleted.
All three of these cases must be handled if the integrity of a relationship is to be maintained. The first case, the addition of an unmatched foreign key, is usually simply prohibited. But note that unknown and nonexistent values don't count. If the relationship is declared as optional, any number of unknown and nonexistent values can be entered without compromising referential integrity.
The second cause of orphaned entities—changing the candidate key value in the referenced table—shouldn't occur very often. In fact, I would strongly recommend that changes to candidate keys be prohibited altogether wherever possible. (This would be an entity constraint, by the way: "Candidate keys are not allowed to change.") But if your model does allow candidate keys to be changed, you must ensure that these changes are made in the foreign keys as well. This is known as a cascading update. Both Microsoft Jet and Microsoft SQL Server provide mechanisms for easily implementing cascading updates.
The final cause of orphan foreign keys is the deletion of the tuple containing the primary entity. If one deletes a Customer record, for example, what becomes of that customer's orders? As with candidate key changes, you can simply prohibit the deletion of tuples in the primary relation if they are referenced in a foreign relation. This is certainly the cleanest solution if it is a reasonable restriction for your system. For when it's not, both the Jet database engine and SQL Server provide a simple means of cascading the operation, known as a cascading delete.
But in this case, you also have a third option that's a little harder to implement. At any rate, it can't be implemented automatically. You might want to reassign the dependent records. This isn't often appropriate, but it is sometimes necessary. Say, for example, that CustomerA purchases CustomerB. It might make sense to delete CustomerB and reassign all of CustomerB's orders to CustomerA.
A special kind of referential integrity constraint is the maximum cardinality issue discussed in Chapter 3. In the data model, rules such as "Managers are allowed to have a maximum of five individuals reporting to them" are defined as referential constraints.
Database Integrity
The most general form of integrity constraint is the database constraint. Database constraints reference more than one relation: "A Customer is not allowed to have a status of 'Preferred' unless he or she has made a purchase in the last 12 months." The majority of database constraints take this form.
It's always a good idea to define integrity constraints as completely as possible, and database integrity is no exception. You must be careful, however, not to confuse a database constraint with the specification of a work process. A work process is something that is done with the database, such as adding an order, whereas an integrity constraint is a rule about the contents of the database. The rules that define the tasks that are performed using the database are work process constraints, not database constraints. Work processes, as we'll see in Chapter 8, can have a major impact on the data model, but they shouldn't be made a part of it.
It isn't always clear whether a given business rule is an integrity constraint or a work process (or something else entirely). The difference might not be desperately important. All else being equal, implement the rule where it's most convenient to do so. If it's a straightforward process to express a rule as a database constraint, do so. If that gets tricky (as it often can, even when the rule is clearly an integrity constraint), move it to the front-end processing, where it can be implemented procedurally.
On the other hand, if the rule is extremely volatile and subject to frequent change, it will probably be easier to maintain if it's part of the database schema, where a single change will effect (but hopefully not break) all the systems referencing it.
Transaction Integrity
The final form of database integrity is transaction integrity. Transaction integrity constraints govern the ways in which the database can be manipulated. Unlike other constraints, transaction constraints are procedural and thus are not part of the data model per se.
Transactions are closely related to work processes. The concepts are, in fact, orthogonal, inasmuch as a given work process might consist of one or more transactions and vice versa. It isn't quite correct, but it's useful to think of a work process as an abstract construct ("add an order") and a transaction as a physical one ("update the OrderDetail table").
A transaction is usually defined as a "logical unit of work," which I've always found to be a particularly unhelpful bit of rhetoric. Essentially, a transaction is a group of actions, all of which (or none of which) must be completed. The database must comply with all of the defined integrity constraints before the transaction commences and after it's completed, but might be temporarily in violation of one or more constraints during the transaction.
The classic example of a transaction is the transfer of money from one bank account to another. If funds are debited from Account A but the system fails to credit them to Account B, money has been lost. Clearly, if the second command fails, the first must be undone. In database parlance, it must be "rolled back."
Transactions can involve multiple records, multiple relations, and even multiple databases. To be precise, all operations against a database are transactions. Even updating a single existing record is a transaction. Fortunately, these low-level transactions are performed transparently by the database engine, and you can generally ignore this level of detail.
Both the Jet database engine and SQL Server provide a means of maintaining transactional integrity by way of the BEGIN TRANSACTION, COMMIT TRANSACTION, and ROLLBACK TRANSACTION statements. As might be expected, SQL Server's implementation is more robust and better able to recover from hardware failure as well as certain kinds of software failure. However, these are implementation issues and are outside the scope of this book. What is important from a design point of view is to capture and specify transaction dependencies, those infamous "logical units of work."
EAN: 2147483647
Pages: 124