USER-ORIENTED, CONCEPT-BASED APPROACH
USER -ORIENTED, CONCEPT-BASED APPROACH
To address the various issues of personalized multilingual web content mining, a user-oriented, concept-based approach for multilingual web content mining is proposed. This is achieved by constructing a multilingual concept space as the linguistic knowledge base. The concept space encodes all multilingual concept- term relationships from parallel corpus using a selforganizing map. Given this concept space, concept-based multilingual web document classification is achieved with a multilingual text classifier using a second self-organizing map. By highlighting a user's personal topics of interests on the concept-based document categories, as defined by the multilingual text classifier, explorative browsing and user-oriented concept-focused information filtering are both facilitated on the same browsing space.
In subsequent sections, we first present an overview of the user-oriented, concept-based approach for multilingual web content mining and describe the technical details about the development of the concept space for encoding the multilingual linguistic knowledge. We then develop a concept-based multilingual text classifier for classifying multilingual web documents by concepts. Finally, we generate a user profile using the user's bookmark file to highlight the user's topics of information interest on a personal concept-based document browsing interface.
An Overview
The concept-based approach to multilingual web content mining is due to a notion that, while languages are culture-bound, concepts expressed by these languages are universal (Soergel, 1997). Moreover, the conceptual relationships among terms are inferable from the way that terms are set down in the text. Therefore, the domain-specific multilingual concept-term relationship can be discovered by analyzing relevant multilingual training documents. Using this multilingual concept-term relationship as the multilingual linguistic knowledge, the semantic content of all multilingual web documents can then be detected . Figure 1 shows the framework for this concept-based approach for useroriented multilingual web content mining.
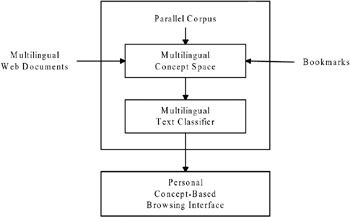
Figure 1: User-Oriented, Concept-Based Approach for Multilingual Web Content Mining
First, a parallel corpus, which is a collection of documents and their translations, is used as training documents for constructing a concept space using a self-organizing map (Kohonen, 1995). The concept space encodes all multilingual concept-term relationships as the linguistic knowledge base for multilingual text classification. With the concept space, a concept-based multilingual text classifier is developed by organizing the training documents on a second self-organizing map.
This text classifier is then used to classify multilingual web documents, using the concept space as the linguistic knowledge base. Multilingual documents describing similar concepts will then be mapped onto a browsing interface as document clusters. To personalize the browsing result, a conceptbased user profile, using the user's bookmark file as the indicator of his information interests, is generated.
Finally, each user's personal topics of interest are highlighted on the browsing interface, mapping the user profile to relevant document clusters. As a result, explorative browsing aimed toward gaining an overview of a certain domain and toward user-oriented concept-focused information filtering is achieved.
Development of a Multilingual Concept Space
From the viewpoint of automatic text processing, the relationships among the meaning of terms are inferable from the way that the terms are set down in the text. Natural language is used to encode and transmit concepts. A sufficiently comprehensive sample of natural language text, such as a wellbalanced corpus, may offer a fairly complete representation of the concepts and the conceptual relationship applicable within specific areas of discourse . Given corpus statistics of term occurrence, the associations among terms become measurable, and sets of semantically/conceptually- related terms are detected.
To construct multilingual, linguistic knowledge base encoding, lexical relationships among multilingual terms, parallel corpora containing sets of documents and their translations in multiple languages are ideal sources of multilingual lexical information. Parallel documents, basically, contain identical concepts expressed by different sets of terms. Therefore, multilingual terms used to describe the same concept tend to occur with very similar inter- and intra-document frequencies across a parallel corpus. An analysis of paired documents has been used to infer the most likely translation of terms between languages in the corpus (see Carbonell et al., 1997; Davis, 1996; Landauer & Littman, 1990). As such, co-occurrence statistics of multilingual terms across a parallel corpus can be used to determine clusters of conceptually-related multilingual terms.
Given a parallel corpus D , consisting of P pairs of parallel documents, meaningful terms from every language covered by the corpus are extracted. They form the set of multilingual terms for constructing the multilingual concept space. Each term is represented by an n -dimensional term vector. Each feature value of the term vector corresponds to the weight of the n th document, indicating the significance of that document in characterizing the meaning of the term. Parallel documents which are translated versions of one another within the corpus are considered as the same feature. To determine the significance of each document in characterizing the contextual content of a term based on the term's occurrences, the following weighting scheme is used. It calculates the feature value w kp of a document d p for p =1, , P in the vector of term t k .
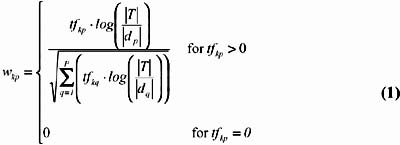
where
tf kp is the occurrence of term t k in document d p ;
log ![]() is the inverse term frequency of document d p ; T is the number of terms in the whole collection, and d p is the number of terms in document d p . The longer the document d p , the smaller the inverse term frequency;
is the inverse term frequency of document d p ; T is the number of terms in the whole collection, and d p is the number of terms in document d p . The longer the document d p , the smaller the inverse term frequency;
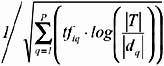 is the normalization factor. With this normalization factor, the feature value relating a document to a term t k is reduced according to the total number of documents in which the term occurs.
is the normalization factor. With this normalization factor, the feature value relating a document to a term t k is reduced according to the total number of documents in which the term occurs.
When the contextual contents of every multilingual term are well represented, they are used as the input into the self-organizing algorithm for constructing the multilingual concept space.
Let x i ˆˆ R N (1 ‰ i ‰ M ) be the term vector of the i th multilingual term, where N is the number of documents in the parallel corpus for a single language (i.e., the total number of documents in the parallel corpus divided by the number of languages supported by the corpus), and where M is the total number of multilingual terms. The self-organizing map algorithm is applied to form a multilingual concept space, using these term vectors as the training input to the map. The map consists of a regular grid of nodes. Each node is associated with an N -dimensional model vector. Let m j = [ m jn 1 ‰ n ‰ N ] (1 ‰ j ‰ G ) be the model vector of the j th node on the map. The algorithm for forming the multilingual concept space is given below.
-
Step 1: Select a training multilingual term vector x i at random.
-
Step 2: Find the winning node s on the map with the vector m s which is closest to x i such that:

-
Step 3: Update the weight of every node in the neighborhood of node s by:
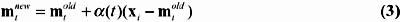
where ± ( t ) the gain term at time t (0 ‰ ± ( t ) ‰ 1) that decreases in time and converges to 0.
-
Step 4: Increase the time stamp t and repeat the training process until it converges.
After the training process is completed, each multilingual term is mapped to the grid node closest to it on the self-organizing map. A multilingual concept space is, thus, formed . This process corresponds to a projection of the multidimensional term vectors onto an orderly two-dimensional concept space, where the proximity of the multilingual terms is preserved as faithfully as possible. Consequently, conceptual similarities among multilingual terms are explicitly revealed by their locations and neighborhood relationships on the map.
To represent the relationship between every language-independent concept and its associated multilingual terms on the concept space, each term vector representing a multilingual term is input once again to find its corresponding winning node on the self-organizing map. All multilingual terms for which a node is the corresponding winning node are associated with the same node. Therefore, a node will be represented by several multilingual terms that are often synonymous. In this way, conceptual-related multilingual terms are organized into term clusters within a common semantic space. The problem of feature incompatibility among multiple languages is, thus, overcome .
Development of a Concept-Based Multilingual Text Classifier
The objective of constructing a concept-based multilingual text classifier is to reveal the conceptual content of arbitrary multilingual web documents by organizing them into concept categories in accordance with their meanings. Sorting document collections by the self-organizing map algorithm depends heavily on the document representation scheme. To form a map that displays relationships among document contents, a suitable method for document indexing must be devised. Contextual contents of documents need to be expressed explicitly in a computationally meaningful way.
In information retrieval, the goal of indexing is to extract a set of features that represents the contents, or the ˜meaning of a document. Among several approaches suggested for document indexing and representation, the vector space model (Salton, 1989) represents documents conveniently as vectors in a multidimensional space, defined by a set of language-specific index terms. Each element of a document vector corresponds to the weight (or occurrence) of one index term. However, in a multilingual environment, the direct application of the vector space model is infeasible due to the feature incompatibility problem. Multilingual index terms characterizing documents of different languages exist in separate vector spaces.
To overcome the problem, a better representation of document contents incorporating information about semantic/conceptual relationships among multilingual index terms is desirable. Toward this end, the multilingual concept space obtained in Section 3 is applied.
On the multilingual concept space, conceptually-related multilingual terms are organized into term clusters. These term clusters, denoting language-independent concepts, are used to index multilingual documents in place of the documents' original language-specific index terms. As such, a concept-based document vector that explicitly expresses the conceptual context of a document, regardless of its language, is obtained. The term-based document vector of the vector space model, which suffers from the feature incompatibility problem, can now be replaced with the language-independent, concept-based document vector. The transformed concept-based document vectors are then organized using the self-organizing map algorithm to produce a concept-based multilingual text classifier.
To do so, each document of the parallel corpus is indexed by mapping its text, term by term, onto the multilingual concept space, whereby statistics of its ˜hits on each multilingual term cluster (i.e., concept) are recorded. This is done by counting the occurrence of each term on the multilingual concept space at the node to which that term is associated. These statistics of term cluster occurrences can be interpreted as a kind of transformed ˜index of the multilingual document. The concept-based multilingual text classifier is formed with the application of the self-organizing map algorithm, using the transformed concept-based document vectors as inputs.
Let y i ˆˆ R G (1 ‰ i ‰ H ) be the concept-based document vector of the i th multilingual document, where G is the number of nodes existing in the multilingual concept space, and where H is the total number of documents in the parallel corpus. In addition, let m j = [ m jn 1 ‰ n ‰ G ] (1 ‰ j ‰ J ) be the G -dimensional model vector of the j th node on the map. The algorithm for forming the conceptbased multilingual text classifier is given below.
-
Step 1: Select a training concept-based document vector y i at random.
-
Step 2: Find the winning node s on the map with the vector m s which is closest to document y i such that:

-
Step 3: Update the weight of every node in the neighborhood of node s by:
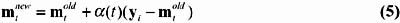
where ± ( t ) is the gain term at time t (0 ‰ ± ( t ) ‰ 1) that decreases in time and converges to 0.
-
Step 4: Increase the time stamp t and repeat the training process until it converges.
After the training process, multilingual documents from the parallel corpus that describe similar concepts are mapped onto the same node, forming document clusters on the self-organizing map. Each node, thus, defines a concept category of a concept-based multilingual text classifier and its corre-sponding browsing interface. The concept-based multilingual text classifier is then used to classify incoming multilingual web documents.
To do so, the text of every multilingual web document is, first, converted into a concept-based document vector using the multilingual concept space as the linguistic knowledge base. This document vector is then input to the multilingual text classifier to find the winning concept category which is closest to it on the self organizing map. Consequently, every multilingual web document is assigned to a concept category on a concept-based browsing interface, based on the conceptual content it exhibits. Based on a predefined network of concepts associating correlated multilingual web documents, the purpose of concept-based explorative browsing in multilingual web content mining is achieved.
Personalization of the Concept-Based Browsing Interface
With the overwhelming amount of information in the multilingual WWW, not every piece of information is of interest to a user. In such circumstances, a user profile, which models the user's information interests, is required to filter out information that the user is not interested in.
Common approaches to user profiling (see Lieberman et al., 1999; Lang, 1995; Mukhopadhyay et al., 1996) build a representation of the user's information interests based on the distribution of terms found in some previously seen documents which the user has found interesting. However, such representation has difficulties in handling situations where a user is interested in more than one topic. In addition, in a multilingual environment, the feature incompatibility problem resulting from the vocabulary mismatch phenomenon across languages makes a language-specific, term-based user profile insufficient to represent the user's information interest that spans multiple languages.
To overcome these problems, we propose a concept-based representation for building user profiles. Using language-independent concepts rather than language-specific terms implies that the resulting user profile is not only more semantically comprehensive but also independent from the language of the documents to be filtered. This is particularly important for multilingual web content mining, where knowledge relevant to a concept in significantly diverse languages has to be identified.
To understand the user's information interests for personalizing multilingual web content mining, the user's preference on the WWW is used. Indicators of these preferences can be obtained from the user's bookmark file. To generate a concept-based user profile from a user's bookmark file, web documents pointed to by the bookmarks are first retrieved. Applying the multilingual concept space as the linguistic knowledge base, each web document is then converted into a concept-based document vector using the procedure described in Section 4. Each concept-based document vector representing a bookmarked web page is input to find its winning node on the multilingual text classifier. All bookmarked multilingual web pages for which a node is the winning node are associated with the same concept category. After mapping all bookmarks' document vectors onto the multilingual text classifier, the concept categories relevant to the user's bookmark file are revealed.
As such, these concept categories can be regarded as the user profile representing a user's information interest in multiple topics. By highlighting these concept categories on the concept-based browsing interface, multilingual web content mining is, thus, personalized. This task of user-oriented conceptfocused information filtering is particularly important for user who wants to keep track of global knowledge that is relevant to his personal domain of interest over the multilingual WWW.
EAN: N/A
Pages: 171