PARADIGMS FOR E-LEARNING SYSTEMS
Mobile Agent Paradigm
The server-client paradigm is popular in current e-learning applications. Mobile agent is an emerging technology. Because it makes the design, implementation, and maintenance of a distributed system much easier, it is attracting a great deal of interest from both industry and academia. In particular, the mobile agent paradigm has already been used to design applications ranging from distributed information retrieval to network management. Figure 1 shows a typical system based on a mobile agent paradigm.
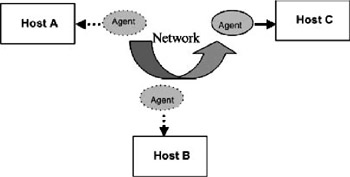
Figure 1: Mobile Agent Paradigm
A mobile agent is an autonomous, intelligent program that can migrate from machine to machine in heterogeneous networks, searching for and interacting with services on the user 's behalf . Typically, agents are autonomous, adaptive, goal-oriented, collaborative, flexible, active, proactive, etc. (Smith & Paranjape, 2000). The mobile agent paradigm is used in distributed computing because improves the performance of the conventional client-server paradigm.
Under mobile agent paradigm, any host in the network is allowed a high degree of flexibility to possess any mixture of service code, resources and CPU time. Its processing capabilities can be combined with local resources. The service code is not tied to a single host, but rather is available throughout the network (Gray & Kotz, 2001).
Information Push and Pull Based on Mobile Agent
With the above features, the mobile agent paradigm is suitable for distributed information retrieval and e-commerce applications.
The rapid evolution of Internet-based services causes information overload on the Web. It has been estimated that the amount of information stored on the Internet doubles every 18 months, and the number of home pages doubles every six months or less (Yang et al., 1998). Therefore, it becomes difficult for the user to locate required information or services on the Internet from the huge amount of information.
Information Push and Pull technology makes easier the delivery of information from service providers to users. Push technology is the process of service provision by a provider in anticipation of its use; Pull technology is the process of searching information in the network.
Ahmad and Mori (2000), from the Tokyo Institute of Technology, proposed Faded Information Field (FIF) architecture. It is based on mobile agent technology to cope with fast-changing information sources and to reduce the information access time of the user.
In FIF, each component, such as user, provider, and node, is considered an autonomous entity. The information is distributed on these nodes, and the amount of information decreases away from the service provider, as shown in Figure 2. The nodes near the Service Center were allocated a larger volume of information, and those farther from central nodes were allocated a smaller volume of information.
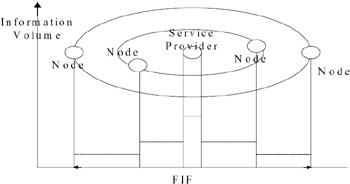
Figure 2: Faded Information Field
In FIF, service providers generate push mobile agents to push information in the neighboring nodes in faded patterns. These agents negotiate with neighboring nodes and allocate information according to situation and importance level. Important information is stored on a higher number of nodes, and less important information is stored in a lower number of nodes. The user looks for information with pull agents. The pull agents navigate through the distributed nodes in FIF autonomously to locate appropriate information.
The algorithm for the design of autonomous information fading takes into consideration the popularity, size and lifetime of the information. A parameter access effort E g (i) is defined to assign a fading level to each information as:
where N i , d i , and S i denote, respectively, the number of times accessed, the lifetime, and the size of the information unit. The information having high access effort is assigned high priority and is stored on all nodes.
Through the cooperation of Push agents and Pull agents in the FIF, the time it takes the user to access needed information is reduced. Since the user does not need to reach the service provider, he can get the required information at the nodes which are close to him. The service provider can avoid the congestion of the access, and the level of reliability is improved.
Keyword Search and Text Mining
The operation of a simple search engine is based on three main components : input of information, indexing information and storing it in a database, and retrieval of information.
Generally speaking, information retrieval from the Internet is done by using keyword matching, which requires user-entered keywords (or their synonyms) to be matched with the indexed keywords. In some cases, the information source may not match the keywords exactly. Even though the meaning matches, keyword matching will not retrieve the particular information file.
Takagi and Tajima (2001), from Meiji University, proposed a method to expand query context dependently using conceptual fuzzy sets. A fuzzy set is defined by enumerating its elements and the degree of membership of each element. It is used to retrieve information not only including the keyword, but also including elements which belong to the same fuzzy sets as the keywords. Keyword expansion should also consider context. The same word may have different meanings in various contexts.
A search engine using conceptual matching instead of keyword matching can effectively retrieve data relating to input keywords when there are no matches with such keywords. First, the search engine indexes the collected web pages, extracts nouns and adjectives, counts the frequency of each word, and stores them into the lexicon. When retrieving information, the user input keywords are collected and, using conceptual fuzzy sets, the meanings of the keywords are represented in other expanded words. The activation value of each word is stored into the lexicon, then matching is executed for each web page. The sum is used as a matching degree in the final evaluations of all words in each web page, and the matched web pages are sorted according to the matching degree. Those web pages with a matching degree exceeding a certain threshold are displayed to the user.
EAN: N/A
Pages: 171