7.5 Transaction logs
|
| < Day Day Up > |
|
Transaction logs are very important and are fundamental to the proper operation of an Exchange server. The way Exchange commits transactions to the database on an asynchronous basis means that it is entirely possible for users to read and write messages entirely in memory. You can receive and read a message without ever going near the database. This is the major implication of the write-ahead logging model used by Exchange, and it is something that every administrator needs to understand.
Messages do not appear in the databases until they have been committed, so until commitment the only place the data exists is in memory and the transaction logs. A system failure renders the memory cache and version useless, and the transaction logs then form the only repository that ESE can use to recover data. It is important to underline and understand this situation. Too many Exchange servers have experienced disk failures in the past, only for the system administrator to find out that the data had been lost because it was not adequately protected in the transaction logs.
Every time the Store service starts up, ESE automatically checks the databases to see whether they are consistent. A flag in the database header is set to "consistent" or "inconsistent," depending on whether the database was shut down cleanly and ESE managed to flush all the data in the cache to disk. The flag is always set to "inconsistent" when a database is active, implying that data exists in the transaction logs that has not yet been committed into the database. If you are unsure whether a database is consistent, you can run the ESEUTIL utility with the /MH flag to check the database header.
Any trace of inconsistency prompts ESE to refer to the transaction logs to identify any outstanding transactions that need to be committed to the database. This operation is referred to as a "soft recovery," or the need to locate and play back missing transactions from the logs. ESE interleaves transactions from all of the databases in a storage group within a transaction log set, so it needs to accomplish some sophisticated and complex processing to locate and then recover transactions. However, ESE masks the complexity from the administrator. You will not, for instance, find any event log messages to tell you that ESE recovered 15 messages from a log for one database and 17 for another.
The only way you can be sure that the Store is fully consistent is to perform a controlled shutdown of the Information Store service. When a shutdown occurs, the Store ensures that there are no transactions still outstanding and commits all the pages in the cache to disk. Taking a full online backup creates a similar effect insofar as the backup represents the database at a particular point in time (when the backup finished). However, it is important to note that you need the combination of transaction logs and database files from the backup tape in order to be able to restart the database and be sure that no data is lost.
7.5.1 Managing transaction logs
Exchange deals with the set of transaction logs as if they formed one large logical log, divided into a set of generations for convenience. To make the transactions easier to manage, ESE divides the logical log into a set of 5-MB log files, referring to each as a "generation." A single large message with one or multiple attachments can span several log files. For example, a message with a 6-MB PowerPoint attachment might force ESE to write the message content and the first 2 MB of the attachment into the current transaction log, and then switch to a new log to write the last 4 MB of the attachment. Each log file has an internal generation number to allow ESE to know the order to access the logs in the event that it needs to replay transactions. The current transaction log is always the highest generation. These generation numbers allow ESE to begin replaying a transaction that starts in one log file and continue through as many logs as necessary until it reaches the end of the transaction.
On a very busy server, millions of transactions might flow through the log files daily, and it is common to see hundreds of log files created during the working day. Apart from normal messaging activity, log file creation also comes about when you import large amounts of data into the Store, perhaps by using the ExMerge tool to move mailboxes from another server, or when you run the Migration wizard to import mailbox data from another email system.
Transaction logs are "tied" to their storage group in two ways. First, ESE writes a unique identifier (the "signature") into each log file as it creates the log. The log identifier must match the signature of the storage group before ESE can use the log contents to recover transactions. Second, ESE records the database directory path in the logs, so ESE knows where it should find the logs when the time comes for recovery. Identifiers and other interesting information can be found by running the database maintenance utility with the /ML switch to dump the header information from a transaction log.
Earlier versions of Exchange number log files sequentially using a file naming scheme of EDBxxxxx.LOG, where xxxxx is a hexadecimal number from 0 to f. Since Exchange now supports multiple storage groups, ESE uses a naming convention of the storage group prefix followed by the hex number. When it creates a new storage group, ESE allocates the separate prefix, and you can view the log prefix through the storage group properties (Figure 7.7). You cannot allocate your own prefix to a storage group. The default (first) storage group uses "E00," the second "E01," the third "E02," and so on. The current transaction log for the first storage group is always E00.LOG, and the current transaction log for the second storage group is E01.LOG. The recovery storage group introduced in Exchange 2003 uses a special "R" prefix for its logs. Figure 7.8 illustrates a typical set of transaction logs.
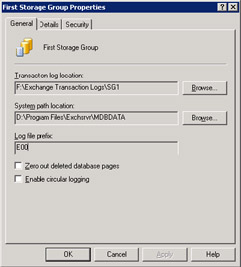
Figure 7.7: Viewing the storage group prefix.
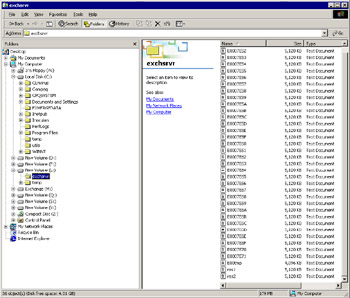
Figure 7.8: A set of transaction logs.
Giving each storage group a separate prefix allows you to keep log files from multiple storage groups in a single directory without running the risk that ESE might overwrite a log from one storage group with transactions from another. However, it is best practice to isolate transaction log sets away from each other by placing each set in a separate directory. Large servers that host many thousands of mailboxes split across three or more storage groups should allocate separate drives to each transaction log set to avoid creating an I/O bottleneck.
7.5.2 Creating new generations of transaction logs
If circular logging is enabled (not recommended for production servers), it means that ESE uses a set of four or five log files to hold transactions (more will be created if required by server load), so the Store switches in old logs to become the current log as transactions are committed to the Store. Otherwise, with circular logging disabled, when ESE fills the current transaction log, it must create a new log. ESE performs the following steps to create a new log file and switch out the existing log file.
First, ESE advances the checkpoint in the checkpoint file to indicate that the transactions in the oldest log have been committed into the database. If they have not, ESE cannot overwrite the oldest log and must therefore proceed to create a new log and continue to write transactions to that file. At this point, you can delete all of the log files that contain transactions older than the checkpoint to return space to the file system.
Up to Exchange 2000 SP2, the potential for a slight delay in processing existed before the new transaction log became available. Microsoft addressed this issue through asynchronous log creation, which means that ESE creates a temporary log file and keeps it available to swap in to become the current transaction log immediately after it fills the current transaction log. The change makes little difference on the majority of systems, but it does speed up log processing on heavily loaded servers. The name of the temporary log file is <storage group prefix>tmp.log—for example, E00tmp.log.
It is best practice never to use circular logging on production mailbox servers, so ESE maintains a complete set of log files between full backups. This scheme requires more disk space, but it is infinitely more secure in terms of data retention. When circular logging is disabled, ESE attempts to create E00TMP.LOG immediately. If the file creation fails, it means that space is not available on the disk where the transaction logs are located.
At this point, E00TMP.LOG should be available. ESE then initializes the log header with the generation number, database signature, and timestamp information before proceeding to rename the current transaction log from Eprefix.LOG (e.g., E00.LOG) to Eprefixgeneration.LOG (e.g., E0007E71.LOG). ESE then renames E00TMP to Eprefix.LOG so that it becomes the current transaction log. ESE does not attempt to write data to the transaction log while these operations are proceeding, so once the new transaction log is available, it proceeds to flush waiting transactions to disk. Switching E00TMP.LOG to become the current transaction log happens very quickly.
Apart from the temporary file, which begins at zero bytes and gradually grows, every transaction log is 5 MB.[2] If you see that a log is anything other than 5 MB (5,242,880 bytes), it is a good indication that the log is corrupt. In this case, you should check the event log for errors, take an offline backup, and then stop and restart the Information Store service. These actions should erase all the log files that contain fully committed transactions and bring the database into a consistent state. In addition, check whether the event log contains any indications that the disk holding the log files is experiencing hardware problems.
Transaction log turnover on mailbox servers varies with user activity, but it is a good rule of thumb to expect servers under heavy workload (i.e., users who are very active) to create one transaction log per user daily. User behavior also influences transaction log turnover. Clearly, if people use email to circulate messages with large attachments instead of using file shares, the number of transaction logs increases to hold the attachments. Thus, a mail- box server supporting 2,000 users who create and send 50 messages a day, 50 percent of which contain attachments, might generate 2,000 transaction logs, or approximately 10 GB of data, amounting to new messages, calendar appointments, moving messages from the Inbox to other folders, system messages, and deletes. This does not mean that the Store databases will grow by this amount, because the single-instance storage model is a very efficient way to capture and store data; ESE will reuse deleted pages in the database to store new messages.
Other servers (such as those hosting a lot of public folders) that engage in heavy replication activity turn over transaction log files quickly, as can those that handle large incoming NNTP news feeds. Bridgehead servers and NNTP servers are both candidates to use circular logging if they do not host mailboxes.
Replication is the process by which servers update each other about the contents of public folders. Servers can be very "chatty" if allowed to be so. For example, servers will send each other frequent details of the public folder hierarchy, just to make sure that everyone knows where all the different public folders are located. Servers circulate snapshot information in special messages, in exactly the same manner as interpersonnel mail. You can cut down on the number of messages generated by replication by limiting replication to occur at particular times of the day rather than whenever Exchange feels the need. Scheduling in this manner also reduces traffic through whatever connectors you use to link servers together, thus preventing any potential delays for interpersonnel mail that might otherwise creep in.
7.5.3 Reserved logs
Each storage group uses two special log files (RES1.LOG and RES2.LOG) to reserve 10 MB of space in case no free space is available on the disk where the transaction logs are located. In this situation, ESE uses the space occupied by the special logs to create a new current transaction log and capture any outstanding transactions before shutting down the Information Store service. In effect, ESE renames the special logs so that RES1.LOG becomes the current transaction log. If more than 5 MB of outstanding transactions exist (possible on very large systems), ESE uses RES2.LOG also. No facility exists to write more than 10 MB of data. On large or heavily trafficked servers, such as those that host thousands of users or act as central switches for distributed organizations, it is quite common to see hundreds of log files created daily. This means that administrators must take care in selecting a location for the log files. This is a very good reason why you should monitor free space on all disks that hold transaction logs. Best practice allocates a separate disk for transaction logs to avoid this problem.
7.5.4 Locating transaction logs
The \MDBDATA directory under the Exchange root is the default location for both the transaction logs and the databases in the default storage group. You can choose to place either the transaction logs or individual databases to other locations when a new storage group or database is created, or this can be done afterward. Changing the location of the transaction logs will force Exchange to dismount and remount all of the databases in the storage group (and update the configuration data in the AD), and you should take a backup immediately after you move databases, since the move nullifies any previous transaction logs because the location information in the log headers is now invalid. Changing the location of a database will only stop operations to that database, but, once again, you should take a backup, since all of the databases in a storage group share the transaction logs, so you want to put everything into a consistent state. Naturally, you should only attempt to move databases or transaction logs when the system is at its quietest so as not to impact users and your uptime statistics.
ESE automatically purges transaction log files whenever you take full or incremental online backups. Cleaning up log files in this manner is logical. After a successful backup, you have a consistent version of the databases on the backup medium, and the database on disk contains all the transactions to the point that the backup started. The backup also contains the log files that exist at the start of the backup, so there is no longer any need to retain these log files. Since log files can take up quite a bit of disk space, the automatic deletion is welcome, but if you want to be cautious, you can always take a separate backup of the log files before you commence the database backup.
On an Exchange server that is also a DC or GC, you have at least two sets of transaction logs: one for each storage group and one for the AD. This is similar to the situation that exists in Exchange 5.5, which maintains separate sets of transaction logs for the Store and DS. Obviously, because Exchange 5.5 and Exchange 2000/2003 use different versions of ESE, you cannot apply Exchange 5.5 transaction logs to an Exchange 2000/2003 database, or vice versa. It is normal to expect that Microsoft will upgrade the database engine through versions and even perhaps in service packs, so you should expect that there is no way to roll back transactions after you upgrade a server. For this reason, always take full backups before you begin to upgrade a server, and because paranoid behavior is often good around databases, you should take a full backup immediately after the upgrade is completed.
To relocate the transaction logs to a suitable volume, first create the target directory and then use ESM to select the storage group that they belong to and view its properties. Click on the "browse" button opposite the current log location and navigate to the new location, as shown in Figure 7.9. Press OK to proceed. ESM now asks you to confirm that it should make the change and warns that it must dismount all the databases in the storage group before it can move the logs. Click on the Yes button to confirm the move. ESM then dismounts the Stores, moves the logs to the new location, and then remounts the Stores. You should take a full online backup at this point to ensure that you can recover, should a future problem occur.
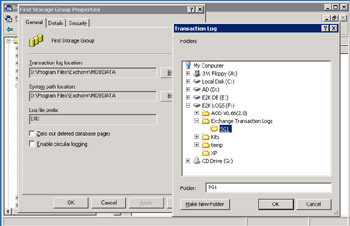
Figure 7.9: Select new location for transaction logs.
7.5.5 Transactions, buffers, and commitment
After a client submits a message, an ESE session that is responsible for the transaction follows a well-defined order to apply the transaction to the Store. First, ESE obtains a timestamp using the internal time (called a "dbtime"—an 8-byte value) maintained by the database in its header. In order to modify a page, ESE must calculate a new db-time based on the current value. Equipped with the timestamp, ESE writes the record into the current transaction log (e.g., the default storage group uses E00.LOG). The first write is into an internal log buffer in memory, and after this operation completes, the session can go ahead and modify the page. Page modifications occur in an in-memory cache of "dirty pages," so ESE may first need to fetch the physical page from the database and page it into memory.
Eventually, ESE flushes the modified pages out of memory and writes them into the database. Note that ESE always writes transactions into the current log file first and has an internal mechanism to ensure that it processes log buffers before their corresponding pages. This implements the write-ahead logging mechanism and ensures data protection. The final entry in the log file extract, shown in Figure 7.10, commits a transaction from session 8. The commit forces ESE to flush the entire set of log records up to and including the commit record for session 8 to disk. ESE performs this process synchronously, so no other operation can proceed for the session until the write to disk is complete. Enabling write-back caching on the disk that holds the transaction logs improves performance by allowing the write to complete in the controller's memory and releasing the synchronous wait. The controller is then responsible to ensure that it actually writes the data to disk.
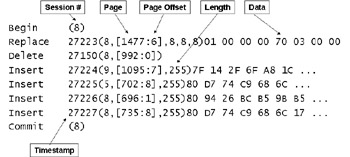
Figure 7.10: Data in a transaction log.
The arrival of a single mail message usually causes ESE to modify many pages, since all of the tables involved (Inbox, message folder table, and so on) are updated. ESE must also update the index for each table, and if the message contains a large attachment, its content will be broken up into several long value chunks, all of which generate log records. The net effect is that delivering a single message results in dozens of log records. Remember that the log records detailing the message delivery are interspersed among the records generated by other sessions. Replaying a transaction is not simply a case of reading and replaying a contiguous chunk of transactions. There is no way to look at the contents of a log file and determine what transactions belong to a single occurrence. Transactions occur at a much lower level than the high-level view contained in the statement that a "new message has arrived." It is, therefore, impossible (in a practical sense) to recover a single transaction from a log file. All you can do is allow Exchange to replay and execute the transactions in exactly the same way as they originally occurred, and that is exactly what happens when the Store executes a "soft" recovery.
7.5.6 Examining a transaction log
You can use any Windows editor to open a transaction log, but it is unlikely that you will be able to interpret much of the contents. Figure 7.11 shows Notepad editing a transaction log. Some of the text in a message header is visible, so you can make sense of the contents, but most of the information is binary and represented by nonprinting characters.
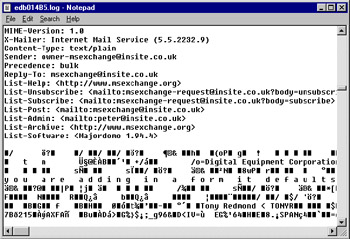
Figure 7.11: Editing a transaction log with Notepad.
The internal contents of a transaction log can be broken down into the header section and data associated with transactions. The header information contains a hard-coded path to the database it is associated with, a timestamp showing the creation time of the log, a unique "signature" from the database, and data relating to the generation the log belongs to. Signature information is important, because it prevents any attempt to replay transactions to the wrong database. Applying transactions from the wrong log file will have disastrous implications for a database! The signature information for a database changes if you need to rebuild or repair the database with the ESE database maintenance utility (ESEUTIL), rendering all the transaction logs invalid. This is the reason why you must take a backup immediately after you rebuild or repair a database.
7.5.7 Dumping a transaction log
You can dump the header of a log file to view this information with the ESEUTIL utility, as follows:
ESEUTIL /ML E0101969.LOG
When we look at the dump of the log, the checkpoint, log generation, timestamp, and signature are reasonably obvious. Other important data includes the name of the database the log belongs to as well as the disk location for the database. In the example shown in Figure 7.12, the log comes from the Store. Exchange maintains a single set of transaction logs for every storage group. The names of all the databases in the group are included in the log. The other information is reasonably esoteric, but the important point is that Exchange understands it and can use the data to replay transactions from the log when required. To explain further, we can examine the contents of the transaction log header shown in Figure 7.12.
Microsoft(R) Exchange Server(TM) Database Utilities Version 6.0|Copyright (C) Microsoft Corporation 1991-2000. All Rights Reserved. Initiating FILE DUMP mode... Base name: e00 Log file: e0007dd5.log lGeneration: 32213 (0x7DD5) Checkpoint: NOT AVAILABLE creation time: 04/10/2002 12:12:04 prev gen time: 04/10/2002 11:28:55 Format LGVersion: (7.3704.5) Engine LGVersion: (7.3704.5) Signature: Create time:07/18/2000 11:36:36 Rand:2804053 Computer: Env SystemPath: F:\EXCHSRVR\mdbdata\ Env LogFilePath: L:\exchsrvr\ Env Log Sec size: 512 Env (CircLog,Session,Opentbl,VerPage,Cursors,LogBufs,LogFile,Buffers) ( off, 252, 37800, 1740, 12600, 128, 10240, 98184) Using Reserved Log File: false Circular Logging Flag (current file): off Circular Logging Flag (past files): off 1 F:\EXCHSRVR\mdbdata\priv1.edb dbtime: 336642779 (0-336642779) objidLast: 164351 Signature: Create time:07/18/2000 11:36:52 Rand:2829026 Computer: MaxDbSize: 0 pages Last Attach: (0x7CB7,1563,1FF) Last Consistent: (0x7CB7,1554,15) 2 S:\MDBDATA\Mailbox Store 2 (DBOEXCVS1).edb dbtime: 100102776 (0-100102776) objidLast: 68693 Signature: Create time:04/17/2001 16:29:15 Rand:1031433187 Computer: MaxDbSize: 0 pages Last Attach: (0x7CB7,1564,CD) Last Consistent: (0x7CB7,155B,C3) 3 S:\MDBDATA\pub1.edb dbtime: 255603408 (0-255603408) objidLast: 137393 Signature: Create time:07/18/2000 11:36:51 Rand:2806806 Computer: MaxDbSize: 0 pages Last Attach: (0x7CB7,1625,110) Last Consistent: (0x7CB7,1562,16A) Last Lgpos: (0x7dd5,27FF,0) Operation completed successfully in 1.31 seconds.
Figure 7.12: Dumping the header of a transaction log.
The most important fields in the transaction log header are:
-
lGeneration: The generation number (can be equated back to the name of the log file). The example log is generation 32,213, so 32,212 previous log files exist. Exchange uses a hexadecimal naming scheme to create file names for the logs, and 7dd5 (hex value for 32,213) is used to create a transaction log name of E0007dd5.LOG. The Store allocates a transaction log prefix to each storage group. The default (first) storage group is always allocated prefix "E0," meaning that all transaction logs for this storage group have file names beginning with the prefix. Thus, we know that this transaction log belongs to the default storage group.
-
Checkpoint: The position of the checkpoint when the transaction log was created. In this case it is "NOT AVAILABLE"; this does not imply a problem, since ESE can retrieve the checkpoint information by examining other logs.
-
Creation time and prev gen time: The date and time when the transaction log was created and the date and time when the previous generation was created. Times that are close together indicate that the Store is under load, since it is creating 5-MB transaction logs at a rapid pace. In this case, almost 44 minutes separates the two logs, so the server is not heavily loaded.
-
Env SystemPath: The location of the checkpoint and TEMP.EDB file for the storage group that owns this transaction log.
-
Env LogFilePath: The location of the transaction logs. You should check that the log files are not in the same location as the databases (there are three databases in the storage group detailed at the bottom of the listing), since this would mean that best practice of separation of logs and databases is not being applied. Always separate transaction logs from their databases.
-
Signature: This data comes from the signature of the databases this transaction log is associated with. All of the databases in a storage group have a signature, and the storage group itself has another signature, which ESE uses to ensure that it only applies valid transactions to a database.
-
Circular logging: Circular logging is disabled for this storage group, so ESE will continue to create transaction logs as it needs and will not reuse logs that contain committed transactions.
-
Database Information: Transaction logs belong to a storage group, not an individual database. The dump lists details of all of the databases in the storage group. In this case, we can see that three databases, two Mailbox Stores, and a Public Store are associated with this transaction log. Therefore, we can expect to see transactions from those databases interleaved in the log.
7.5.8 Data records
The data section of a transaction log contains records of the low-level physical modifications to the databases. Each log contains a sequential list of operations performed on pages in memory. ESE captures details of when a transaction begins, when it is committed, and if it is rolled back for some reason. Each record in the log is of a certain type. Record types include begin (a transaction is starting), replace (some data in a page is being updated), delete (data is removed), insert (data is added), and commit. In addition to interleaved transactions from multiple databases, transactions from multiple sessions are interleaved throughout a transaction log, so the begin record type also identifies the session that performed a transaction. You can think of a session as a thread running within the Store process. The session forms the context within which ESE manages the transaction and all of the associated database modifications. Each session could be tied back to a particular client, but the database has no knowledge of individual clients (MAPI or otherwise), since all it sees are the threads that operate on its contents.
Regretfully, there is no tool provided to interpret a log file. Figure 7.10 illustrates how a set of transactions might appear in a log. In this example, the first transaction in session 8 (or thread 8) is replacing a record in the database. Every physical modification to a database is timestamped. ESE uses timestamps later if it has to replay transactions from a particular point in time. The page number and an offset within the page are also recorded. The length of the data to be replaced is then noted and followed with the actual binary data that is inserted into the page. The next transaction is a record delete. The set of insert transactions demonstrates that transactions from multiple sessions are intermingled within a log. Sessions write data into the log file as they process transactions. Any dump of a log file from even a moderately busy server will record transactions from scores of sessions.
7.5.9 Transaction log I/O
ESE always writes transactions in sequential order and appends the data to the end of the current transaction log. All of the I/O activity is generated by writes, so it is logical to assume that the disk where the logs are located must be capable of supporting a reasonably heavy I/O write load. In comparison, the disks where the Store databases are located experience read and write activity as users access items held in their mailboxes.
On large servers, the I/O activity generated by transaction logs is usually managed by placing the logs on a dedicated drive. This solves two problems. First, the size of the disk (usually 4 GB or greater) means that free space should always be available. If you have managed to accumulate 4 GB of logs (800 individual log files), it means that either your server is under a tremendous load or you haven't taken a full online backup in the recent past. Full online backups remove the transaction logs when they successfully complete. Second, in all but extreme circumstances, a dedicated drive is capable of handling the I/O load generated by transaction logs. I cannot think of a reason why a dedicated drive could become swamped with I/O requests from log activity. In any case, if such a load were ever generated on a server, the I/O activity to the Store is probably going to be of more concern than the log disk.
Of course, having a dedicated drive for log files is a luxury that you might not be able to afford. But the logic applied to justify the drive — reserve enough space for log file growth and keep an eye on I/O activity— should be remembered when you decide where the logs should be stored on your system. For example, it's a bad idea to locate the logs on the same drive as other "hot" files, such as a Windows page file. Also, never place the logs on the same drive as a database. Keeping the logs with their database may seem like a good idea, but it risks everything. If a problem afflicts the disk where the stores are located, the same problem will strike down the transaction logs and you will lose data.
7.5.10 Protecting transaction logs
Apart from the fundamental first step of separating the transaction logs from their databases through placement on different physical volumes, best practice is to deploy the necessary hardware to provide the Store databases with maximum protection against disk failure.
You also need to protect transaction logs, but they certainly do not need RAID 5, since the overhead generated by RAID 5 will slow the write activity to the logs. RAID 0+1 is overkill too. All you need to do is buy two disks for the transaction logs and create a mirror set. You can run the logs on an unprotected drive, but if you do this, you must understand that any problem on that drive may render the logs unreadable. In this situation, if you then have to restore a database for any reason, you will not be able to replay transactions from the logs into the restored database and data will be lost.
As discussed earlier, the default behavior for ESM is to create transaction logs and databases on the same volume. Exchange places the default storage group and its transaction logs on the same volume when you first install a server. You should, therefore, review log placement on a regular basis with an aim of assuring both maximum protection and performance.
I may seem a touch paranoid when I discuss protection for the databases and transaction logs, but I look at it in a different way. Consider how much money it costs to recover data if a drive fails. Now factor in the cost in terms of loss of productivity, the strain on everyone involved, and the sheer lack of professionalism that exists in any situation where you might compromise data integrity. With these points in mind, I think I am right to be paranoid about protecting data!
7.5.11 Transaction log checksum
Every transaction log contains a checksum, which ESE validates to ensure that the log data is consistent and valid. Microsoft introduced the checksum to prevent logical corruption from occurring, since the Store replays transactions into a database during a recovery process. The checksum also prevents administrators from replaying a selective set of logs back into the Store after a restore, something that used to be possible up to Exchange 5.5. Selective replays are a bad idea, because the Store interleaves transactions from all databases in a storage group into a single set of logs, so it is possible to miss parts of a transaction if the Store does not replay the complete set.
ESE uses a type of "sliding window" algorithm called Log Record Checksum (LRCK) to validate checksums for a selected group of records in a log to ensure log integrity. ESE reads and verifies these checksums during backup and recovery operations to ensure that invalid data is not used. If ESE detects invalid data through a checksum failure, it logs a 463 error in the system event log. If ESE fails to read the header of a transaction log and is unable to validate the checksum, it signals error 412, as shown in Figure 7.13. Transaction log failure inevitably leads to data loss, since the only way to recover from this error is to restore the last good backup. All of the transactions since that backup will be lost.
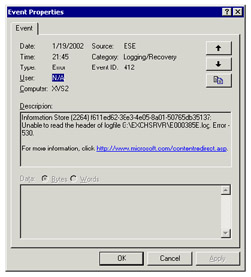
Figure 7.13: Transaction log checksum failure.
7.5.12 Circular logging
Many Exchange servers support relatively small user communities. In the early days of Exchange, when companies migrated from PC LAN email systems such as Microsoft Mail and Lotus cc:Mail, disk resources were scarce, so Microsoft implemented circular logging to prevent the Store from halting because the transaction logs filled all available disk space. Circular logging saves disk space by reusing transaction logs. Instead of gradually accumulating a set of logs that represents the complete set of transactions that have occurred since the last full backup, when you enable circular logging for a storage group, the Store marks a log file for reuse after all of its transactions have been committed to the database. The checkpoint determines when a transaction log is available for reuse. When the Store advances the checkpoint to a point where the transactions in a log have been committed, the log file is no longer required for a recovery operation and can therefore be marked for reuse. You could delete the file, but if the log is left alone, the Store will rename the file and make it the next transaction log when the current log is filled. In normal operation, circular logging uses no more than five or six files, or 25–30 MB.
On first appearance, circular logging sounds like a wonderful idea. The benefits are obvious: a reduced disk space requirement and no need to monitor the disk where the logs are stored to ensure it does not run out of space. The downside is less obvious. Exchange keeps logs to allow you to recover transactions in case you ever have to restore a database from a backup. However, if the Store has reused the logs, it is obvious that it has had to overwrite transaction data in the logs that you can never recover. Thus, if you use circular logging, you should be aware that any time you come to restore an Exchange database, a very large possibility exists that some data will be lost. This is because you can restore the database, but you have lost the ability to roll forward any transactions that have occurred since you took the backup. The transactions in the current set of logs are useless, because a gap exists in the generation of logs created since the last full backup. The Store can only recover transactions if all generations are available during a recovery operation.
You might be able to argue a compelling case to enable circular logging on small systems, such as those that run Exchange with Microsoft Small Business Server. The best rule of thumb is that any production server that supports mailboxes and creates more than five log files a day should never enable circular logging.
Circular logging is a property of a storage group and can be enabled or disabled by accessing the properties of the storage group and setting or clearing the checkbox, as shown in Figure 7.14. The Store will implement the new behavior the next time the databases in the storage group are mounted. Note that Exchange disables circular logging by default.
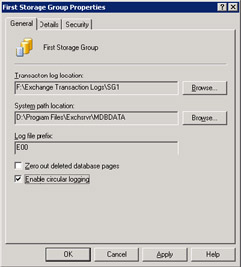
Figure 7.14: Enabling circular logging for a storage group.
7.5.13 Database zeroing
Figure 7.14 also illustrates the interface used to enable database zeroing, another property of a storage group. Zeroing means that the Store writes zeros to replace the data as it deletes deleted pages to prevent any possibility that someone could look through the database and work out what the pages contain. Zeroing adds a small amount of overhead to Store processing and is not enabled by default. Generally, administrators do not bother with zeroing pages unless they are very concerned that a malicious third party could compromise and reuse the data in deleted pages in some way.
[2] . The 5-MB size is used in all versions since Exchange V4.0. The ever-increasing size of messages once prompted me to ask some Exchange engineers why the log file size had not increased further, so that more messages could be stored in each log. The answer was that the overhead incurred to create a new log file was so small that it wasn't worthwhile changing the size now. The Active Directory uses 10-MB log files.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 188
- Article 225 Outside Branch Circuits and Feeders
- Article 422: Appliances
- Article 440: Air Conditioning and Refrigerating Equipment
- Example No. D8 Motor Circuit Conductors, Overload Protection, and Short-Circuit and Ground-Fault Protection
- Example No. D9 Feeder Ampacity Determination for Generator Field Control