Testing for Performance
Performance tests are often extended versions of functionality tests. In fact, it is almost always worthwhile to include some basic functionality testing within performance tests to ensure that you are not testing the performance of broken code.
While there is definitely overlap between performance and functionality tests, they have different goals. Performance tests seek to measure end-to-end performance metrics for representative use cases. Picking a reasonable set of usage scenarios is not always easy; ideally, tests should reflect how the objects being tested are actually used in your application.
In some cases an appropriate test scenario is obvious. Bounded buffers are nearly always used in producer-consumer designs, so it is sensible to measure the throughput of producers feeding data to consumers. We can easily extend PutTakeTest to become a performance test for this scenario.
A common secondary goal of performance testing is to select sizings empirically for various boundsnumbers of threads, buffer capacities, and so on. While these values might turn out to be sensitive enough to platform characteristics (such as processor type or even processor stepping level, number of CPUs, or memory size) to require dynamic configuration, it is equally common that reasonable choices for these values work well across a wide range of systems.
12.2.1. Extending PutTakeTest to Add Timing
The primary extension we have to make to PutTakeTest is to measure the time taken for a run. Rather than attempting to measure the time for a single operation, we get a more accurate measure by timing the entire run and dividing by the number of operations to get a per-operation time. We are already using a CyclicBarrier to start and stop the worker threads, so we can extend this by using a barrier action that measures the start and end time, as shown in Listing 12.11.
We can modify the initialization of the barrier to use this barrier action by using the constructor for CyclicBarrier that accepts a barrier action:
Listing 12.11. Barrier-based Timer.
this.timer = new BarrierTimer();
this.barrier = new CyclicBarrier(npairs * 2 + 1, timer);
public class BarrierTimer implements Runnable {
private boolean started;
private long startTime, endTime;
public synchronized void run() {
long t = System.nanoTime();
if (!started) {
started = true;
startTime = t;
} else
endTime = t;
}
public synchronized void clear() {
started = false;
}
public synchronized long getTime() {
return endTime - startTime;
}
}
|
The modified test method using the barrier-based timer is shown in Listing 12.12.
We can learn several things from running TimedPutTakeTest. One is the throughput of the producer-consumer handoff operation for various combinations of parameters; another is how the bounded buffer scales with different numbers of threads; a third is how we might select the bound size. Answering these questions requires running the test for various combinations of parameters, so we'll need amain test driver, shown in Listing 12.13.
Figure 12.1 shows some sample results on a 4-way machine, using buffer capacities of 1, 10, 100, and 1000. We see immediately that a buffer size of one causes very poor throughput; this is because each thread can make only a tiny bit of progress before blocking and waiting for another thread. Increasing buffer size to ten helps dramatically, but increases past ten offer diminishing returns.
Figure 12.1. TimedPutTakeTest with Various Buffer Capacities.
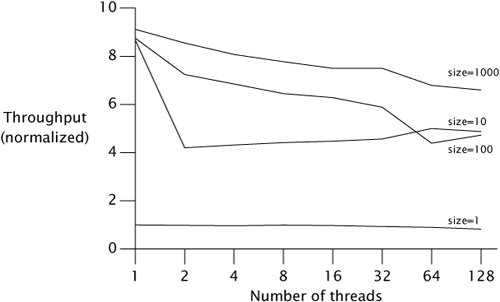
It may be somewhat puzzling at first that adding a lot more threads degrades performance only slightly. The reason is hard to see from the data, but easy to see on a CPU performance meter such as perfbar while the test is running: even with many threads, not much computation is going on, and most of it is spent blocking and unblocking threads. So there is plenty of CPU slack for more threads to do the same thing without hurting performance very much.
However, be careful about concluding from this data that you can always add more threads to a producer-consumer program that uses a bounded buffer. This test is fairly artificial in how it simulates the application; the producers do almost no work to generate the item placed on the queue, and the consumers do almost no work with the item retrieved. If the worker threads in a real producer-consumer application do some nontrivial work to produce and consume items (as is generally the case), then this slack would disappear and the effects of having too many threads could be very noticeable. The primary purpose of this test is to measure what constraints the producer-consumer handoff via the bounded buffer imposes on overall throughput.
Listing 12.12. Testing with a Barrier-based Timer.
public void test() {
try {
timer.clear();
for (int i = 0; i < nPairs; i++) {
pool.execute(new Producer());
pool.execute(new Consumer());
}
barrier.await();
barrier.await();
long nsPerItem = timer.getTime() / (nPairs* (long)nTrials);
System.out.print("Throughput: " + nsPerItem + " ns/item");
assertEquals(putSum.get(), takeSum.get());
} catch (Exception e) {
throw new RuntimeException(e);
}
}
|
Listing 12.13. Driver Programfor TimedPutTakeTest.
public static void main(String[] args) throws Exception {
int tpt = 100000; // trials per thread
for (int cap = 1; cap <= 1000; cap*= 10) {
System.out.println("Capacity: " + cap);
for (int pairs = 1; pairs <= 128; pairs*= 2) {
TimedPutTakeTest t =
new TimedPutTakeTest(cap, pairs, tpt);
System.out.print("Pairs: " + pairs + " ");
t.test();
System.out.print(" ");
Thread.sleep(1000);
t.test();
System.out.println();
Thread.sleep(1000);
}
}
pool.shutdown();
}
|
12.2.2. Comparing Multiple Algorithms
While BoundedBuffer is a fairly solid implementation that performs reasonably well, it turns out to be no match for either ArrayBlockingQueue or LinkedBlockingQueue (which explains why this buffer algorithm wasn't selected for inclusion in the class library). The java.util.concurrent algorithms have been selected and tuned, in part using tests just like those described here, to be as efficient as we know how to make them, while still offering a wide range of functionality.[6] The main reason BoundedBuffer fares poorly is that put and take each have multiple operations that could encouter contentionacquire a semaphore, acquire a lock, release a semaphore. Other implementation approaches have fewer points at which they might contend with another thread.
[6] You might be able to outperform them if you both are a concurrency expert and can give up some of the provided functionality.
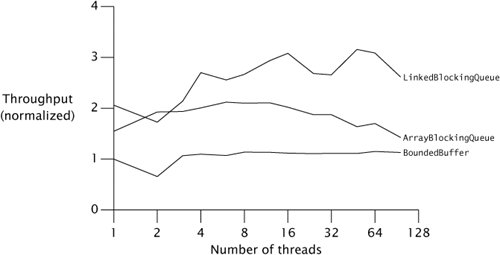
Figure 12.2 shows comparative throughput on a dual hyperthreaded machine for all three classes with 256-element buffers, using a variant of TimedPutTakeTest. This test suggests that LinkedBlockingQueue scales better than ArrayBlockingQueue. This may seem odd at first: a linked queue must allocate a link node object for each insertion, and hence seems to be doing more work than the array-based queue. However, even though it has more allocation and GC overhead, a linked queue allows more concurrent access by puts and takes than an array-based queue because the best linked queue algorithms allow the head and tail to be updated independently. Because allocation is usually threadlocal, algorithms that can reduce contention by doing more allocation usually scale better. (This is another instance in which intuition based on traditional performance tuning runs counter to what is needed for scalability.)
Figure 12.2. Comparing Blocking Queue Implementations.
12.2.3. Measuring Responsiveness
So far we have focused on measuring throughput, which is usually the most important performance metric for concurrent programs. But sometimes it is more important to know how long an individual action might take to complete, and in this case we want to measure the variance of service time. Sometimes it makes sense to allow a longer average service time if it lets us obtain a smaller variance; predictability is a valuable performance characteristic too. Measuring variance allows us to estimate the answers to quality-of-service questions like "What percentage of operations will succeed in under 100 milliseconds?"
Histograms of task completion times are normally the best way to visualize variance in service time. Variances are only slightly more difficult to measure than averagesyou need to keep track of per-task completion times in addition to aggregate completion time. Since timer granularity can be a factor in measuring individual task time (an individual task may take less than or close to the smallest "timer tick", which would distort measurements of task duration), to avoid measurement artifacts we can measure the run time of small batches of put and take operations instead.
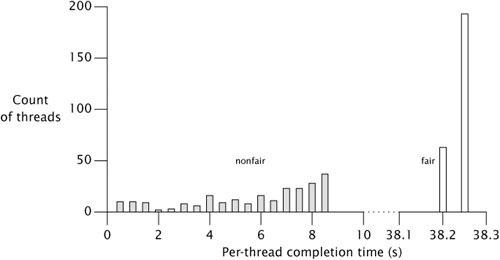
Figure 12.3 shows the per-task completion times of a variant of TimedPutTakeTest using a buffer size of 1000 in which each of 256 concurrent tasks iterates only 1000 items for nonfair (shaded bars) and fair semaphores (open bars). (Section 13.3 explains fair versus nonfair queueing for locks and semaphores.) Completion times for nonfair semaphores range from 104 to 8,714 ms, a factor of over eighty. It is possible to reduce this range by forcing more fairness in concurrency control; this is easy to do in BoundedBuffer by initializing the semaphores to fair mode. As Figure 12.3 shows, this succeeds in greatly reducing the variance (now ranging only from 38,194 to 38,207 ms), but unfortunately also greatly reduces the throughput. (A longer-running test with more typical kinds of tasks would probably show an even larger throughput reduction.)
Figure 12.3. Completion Time Histogram for TimedPutTakeTest with Default (Nonfair) and Fair Semaphores.
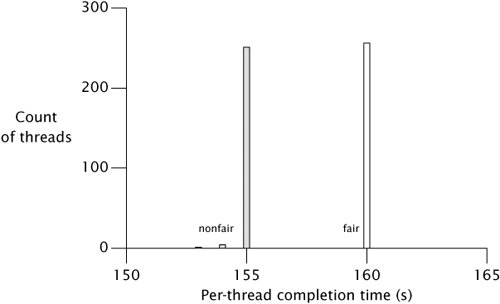
We saw before that very small buffer sizes cause heavy context switching and poor throughput even in nonfair mode, because nearly every operation involves a context switch. As an indication that the cost of fairness results primarily from blocking threads, we can rerun this test with a buffer size of one and see that nonfair semaphores now perform comparably to fair semaphores. Figure 12.4 shows that fairness doesn't make the average much worse or the variance much better in this case.
Figure 12.4. Completion Time Histogram for TimedPutTakeTest with Single-item Buffers.
So, unless threads are continually blocking anyway because of tight synchronization requirements, nonfair semaphores provide much better throughput and fair semaphores provides lower variance. Because the results are so dramatically different, Semaphore forces its clients to decide which of the two factors to optimize for.
Introduction
- Introduction
- A (Very) Brief History of Concurrency
- Benefits of Threads
- Risks of Threads
- Threads are Everywhere
Part I: Fundamentals
Thread Safety
- Thread Safety
- What is Thread Safety?
- Atomicity
- Locking
- Guarding State with Locks
- Liveness and Performance
Sharing Objects
Composing Objects
- Composing Objects
- Designing a Thread-safe Class
- Instance Confinement
- Delegating Thread Safety
- Adding Functionality to Existing Thread-safe Classes
- Documenting Synchronization Policies
Building Blocks
- Building Blocks
- Synchronized Collections
- Concurrent Collections
- Blocking Queues and the Producer-consumer Pattern
- Blocking and Interruptible Methods
- Synchronizers
- Building an Efficient, Scalable Result Cache
- Summary of Part I
Part II: Structuring Concurrent Applications
Task Execution
- Task Execution
- Executing Tasks in Threads
- The Executor Framework
- Finding Exploitable Parallelism
- Summary
Cancellation and Shutdown
- Cancellation and Shutdown
- Task Cancellation
- Stopping a Thread-based Service
- Handling Abnormal Thread Termination
- JVM Shutdown
- Summary
Applying Thread Pools
- Applying Thread Pools
- Implicit Couplings Between Tasks and Execution Policies
- Sizing Thread Pools
- Configuring ThreadPoolExecutor
- Extending ThreadPoolExecutor
- Parallelizing Recursive Algorithms
- Summary
GUI Applications
- GUI Applications
- Why are GUIs Single-threaded?
- Short-running GUI Tasks
- Long-running GUI Tasks
- Shared Data Models
- Other Forms of Single-threaded Subsystems
- Summary
Part III: Liveness, Performance, and Testing
Avoiding Liveness Hazards
Performance and Scalability
- Performance and Scalability
- Thinking about Performance
- Amdahls Law
- Costs Introduced by Threads
- Reducing Lock Contention
- Example: Comparing Map Performance
- Reducing Context Switch Overhead
- Summary
Testing Concurrent Programs
- Testing Concurrent Programs
- Testing for Correctness
- Testing for Performance
- Avoiding Performance Testing Pitfalls
- Complementary Testing Approaches
- Summary
Part IV: Advanced Topics
Explicit Locks
- Explicit Locks
- Lock and ReentrantLock
- Performance Considerations
- Fairness
- Choosing Between Synchronized and ReentrantLock
- Read-write Locks
- Summary
Building Custom Synchronizers
- Building Custom Synchronizers
- Managing State Dependence
- Using Condition Queues
- Explicit Condition Objects
- Anatomy of a Synchronizer
- AbstractQueuedSynchronizer
- AQS in Java.util.concurrent Synchronizer Classes
- Summary
Atomic Variables and Nonblocking Synchronization
- Atomic Variables and Nonblocking Synchronization
- Disadvantages of Locking
- Hardware Support for Concurrency
- Atomic Variable Classes
- Nonblocking Algorithms
- Summary
The Java Memory Model
EAN: 2147483647
Pages: 141
