7.3 EDB database structure
|
| < Day Day Up > |
|
From Exchange 2000 onward, the Store uses two types of database: the EDB and the STM (a database set). The EDB is the traditional database and is organized into a set of 4-KB pages, numbered in sequence. Microsoft also refers to the EDB as a "property database," because its original function was to hold MAPI properties for messages and other items. Exchange holds message content and attachments as MAPI properties, although there is a limit to the amount of content that a particular property can hold, so the Store often uses extensions to hold large amounts of data. Exchange only needed a MAPI database as long as it only supported MAPI clients, but once Internet clients appeared some change was necessary to support the way they retrieve data. Exchange 5.0 and 5.5 handle Internet clients as if they were modified MAPI clients, but this is an inefficient mechanism, because it forces the Store to convert streamed data to MAPI always.
Microsoft then introduced the STM, or streaming database, in Exchange 2000 to handle the native MIME content generated by POP3 and IMAP4 clients. Every EDB database has a matching STM, and the Store manages the interaction between the EDB and STM databases invisible to clients. Whenever possible, the Store maintains content in its original format and only converts it when necessary, avoiding permanent conversion if not needed. For example, if an older MAPI client that cannot support MIME reads a message held in the STM, the Store converts the content to MAPI. If the client then decides to amend the content, the Store writes the MAPI content into the EDB and updates pointers so that if the user retrieves the message again, using whatever client, he or she gets the MAPI content. Because you can use different clients to access your mailbox, a mailbox can contain both MAPI and MIME content, and, again, the Store makes sure it hides this complexity from view. Sometimes conversions happen when you do not expect them. For example, if you use AD Users and Computers (or the Exchange 2003 version of ESM) to move a mailbox from one server to another or from one database to another on the same server, any MIME content in the mailbox transfers automatically into MAPI. The net effect is that the size of the EDB file can grow alarmingly if you move many mailboxes, and the time taken to perform the moves is sometimes longer than you might expect.
7.3.1 EDB page structure
The first two pages in an EDB are the database header. The remaining pages hold data, so the third physical page is logical database page 1, the fourth is logical database page 2, and so on. The Enterprise Edition of Exchange allows a single ESE database to store up to 232 pages, meaning that the maximum possible size for a single database is 16 TB (the standard edition restricts databases to 16 GB). Of course, this limit is largely theoretical, since no administrator would allow a database to grow so large because the database would be difficult to back up, not to mention restore, unless snapshot technology were used. The largest operational Exchange database has grown 20-fold from 10 GB in 1996 to over 250 GB today; a similar increase would drive the largest database to 4 TB by 2005. However, the partitioning of the Store across multiple databases should restrict databases to more manageable sizes for the near future.
Each page has a 40-byte header, which includes the page number, a count of free bytes available in the page, and a checksum. As we will see later on, the checksum plays an extremely important role in the way that ESE ensures data integrity. The page header for data pages also holds information about the adjacent pages on either side, which helps ESE to navigate through pages quickly and is a characteristic of the B+tree implementation. While there is an extra overhead in calculating the adjacent page numbers, they allow for faster sequential reads through data.
7.3.2 Within the trees
ESE organizes database pages into balanced trees. Balance tree technology is not new, nor is it particular to Exchange.[1] Balanced trees allow fast access to data on disk and reduce the number of I/Os the engine requires to find a specific piece of information. Data in balanced trees is sorted in whatever way is required by an application. ESE uses a variant called B+tree (B-plus-tree), which provides a higher degree of efficiency by minimizing the extent of the database's internal hierarchy. In turn, limits are also set on how wide the branches within the database can grow and how many levels deep they go.
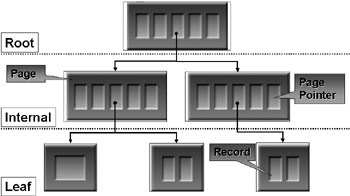
Figure 7.2: The B-tree structure within an ESE database.
Pages can hold data or act as pointers to other pages, and both page types are intermingled within the database. ESE is able to cache pages in memory to improve performance and reduce disk I/O. The Exchange buffer manager, one of the Store components, using a well-known public domain algorithm called Least Recently Used Reference Count (LRU-K), manages the pages in memory. In other words, ESE flushes pages from the cache if it calculates that they have not recently been used, while pages that have been referenced are retained whenever possible.
To find anything in the tree you start at the root page and navigate down to the leaf level (see Figure 7.2). The internal pages (not at the leaf level) only contain pointers to leaf pages. An individual page can contain between 200 and 300 pointers to leaf pages. Because ESE compresses the pointers into a reasonably small number of pages, the height of the tree that ESE must navigate is never very large. Inside ESE, there is normally never more than four levels to navigate. Put another way, no more than four LRU-K I/Os are required to get to the data you require, and each I/O can be eliminated if the relevant page is in cache. Most heavily trafficked pages will be in the cache. Records are stored at the leaf level. The actual record depends on what type of tree you access.
ESE uses three major types of B+trees: index, data, and long value trees. Indexes provide different sort orders on the data held in data trees. They allow secondary index keys to map the primary index at a small additional cost. Sorting is performed using MAPI properties. Unlike other databases, ESE has the capability to add or delete new indexes dynamically.
7.3.3 Database tables and fields
ESE organizes mailbox and public folder data into tables, which are then made up of records and then columns (fields). The maximum size of a record is approximately 4,050 bytes (the 4-KB page minus the header overhead). Thus, a record equates to a page. Apart from a few exceptions, ESE only assigns space to a column if data is available. You do not have a situation where a large number of columns are blank, because some message attributes have not been completed by a user. The header information for most messages fits into the space within a page, but, obviously, there are going to be times when records need to grow past a 4-KB boundary. For example, if you send a message whose body text is larger than 4 KB, it cannot be stored in the data page allocated to the MAPI PR_BODY property. The same is true when dealing with attachments larger than 4 KB, since attachments are also stored in another MAPI property. ESE solves the problem with long value trees. Each table can have a long value tree, which is created on an as-needed basis. If a piece of data is too big to fit into the data tree, it is broken up into a series of 4-KB chunks stored in the long value tree. Each chunk is assigned a table-wide identifier within the long value tree. When required, data can be located very efficiently in the long value tree through a combination of the identifier and offset within the tree.
By comparison, the AD organizes information into 8-K pages. You can understand the difference by the fact that the AD might have to store hundreds of attributes about a user or other object, so the average size of an object is probably going to be greater than 4 KB. If the AD used 4-KB pages, it would result in many page splits, which would not make the internal structures very efficient.
Strictly speaking, the internal structure of the EDB is not a relational database, but that model is the closest you would come to when making comparisons between Exchange and other databases. Much of the interaction is carried out on a hierarchical basis, as users navigate within the folders and subfolders inside mailboxes, but the access to individual items within a folder depends on many relationships maintained inside the database. Many different types of tables are defined for use inside the Store, but the majority of these tables are used internally and are not very interesting to users or system administrators. The ISINTEG utility provides an insight into the number of tables, but not their use, when you run the utility in verbose mode.
Internally, ESE does not represent a table by one tree. Instead, each table is a collection of trees. The system catalog stores the information about the trees that collectively make up a table. The trees set in a table includes the root pages, information about the columns that make up the table, and the indexes used by the table. Views are secondary indexes for folders. Users can generate views at a whim by clicking on one of the field headings when browsing a folder through a MAPI client (POP3 or IMAP clients do not support views). When this happens, a new view is created (e.g., sort by author name) and added to the table. A slight delay may be encountered when a view is first built, but afterward the view is available as part of the table, and switching views happens very quickly. Views are aged out after seven days and discarded at that point if they are no longer in use. This approach prevents the Store from being cluttered with old and obsolete views, which may have been used only once.
ESE uses a special table called the system catalog to track its internal operations. Because the system catalog is so vital to ESE, the Store keeps two copies, called MSysObjects and MSysObjectsShadow. The repair process carried out when you run ESEUTIL with the /P qualifier is able to access the backup copy of the system catalog and fix problems should they occur in the original system catalog.
Data trees store the actual records where the Store holds information such as message and attachment content. These pages do not form a very complex structure. After all, there are only so many steps you can take to organize data within a repository. It is worth noting here that arranging data in 4-KB pages is satisfactory if the data remains small. Once the size of messages goes past 4 KB, ESE must split the content across multiple pages; there is no guarantee that all the pages are stored contiguously in the database. There is an additional processing overhead required to assemble message content from multiple pages, and the overhead grows in line with message size. This is one of the major influences behind the decision to split storage between the EDB databases and the streaming file.
7.3.4 Tables in a Mailbox Store
Despite its hierarchical nature, navigation within a mailbox depends on relationships between different tables within a Mailbox Store. The most important of these tables are as follows:
-
The mailbox table: One row holds properties for each mailbox on a server.
-
The folders table: One row exists for each folder in every mailbox.
-
The message table: One row holds content for every message.
-
The attachments table: One row holds content for every attachment.
-
A set of message/folder tables: A separate table exists for every folder.
Public Folder Stores and the AD also organize their data into tables and rows. Everyone is familiar with mailboxes, and Mailbox Stores get most use on any server, so it is the most appropriate example to use for illustrative purposes. This discussion is based on the interaction that occurs within a single database. The Store manages the retrieval of data from multiple databases, if these are involved in transactions.
Pointers link one table to another within the Store. This interaction forms the basis of single-instance storage and delivers a unified view of Store contents to clients. The processing that takes place when a client opens a mailbox, and then opens and reads a message, illustrates how pointers tie the tables together.
Let's examine what happens when an Outlook client opens a mailbox. Sample data is used to illustrate the explanation, and the data has been simplified for clarity.
The Store supports nested folders. In other words, folders can contain subfolders. Clients construct a tree view of folders by reading data from the Folders table. Each folder has a unique identifier, and the Store recognizes subfolders by the existence of a parent folder ID, which also serves to link subfolders back to the parent folder. The sample data in Table 7.1 shows that the "Articles" and "Newsflash" folders are both subfolders of the "Magazine" folder. Clients use the count of new items to decide when to bold folder names as a visual sign to users that they should review the contents of the folder.
| Folder ID | Folder Name | Folder Owner | Count of Items | Count of New Items | Parent Folder ID |
|---|---|---|---|---|---|
| 10445872 | Inbox | TonyR | 195 | 10 | 0 |
| 10427756 | Magazine | TonyR | 15 | 0 | 0 |
| 10427558 | Articles | TonyR | 29 | 1 | 10427756 |
| 10475586 | Newsflash | TonyR | 5 | 0 | 10427756 |
| 10479514 | Deleted Items | TonyR | 85 | 0 | 0 |
| 10475866 | Inbox | BillR | 100 | 15 | 0 |
| 10557660 | Deleted Items | BillR | 16 | 0 | 0 |
A separate table holds header information (all of which are MAPI properties) for each folder. Maintaining header information in a separate table allows each folder to have its own sort order. The alternative is to request data from a much larger table, albeit sorted and indexed. The scheme used by Exchange minimizes the data transmitted between client and server when clients wish to display information about a folder. For example, when an Outlook client builds the folder list, it proceeds to display header information from the currently selected folder (usually the Inbox) in the righthand pane in its main window. Fetching data similar to that shown in Table 7.2 from the appropriate message/folder table performs this operation.
| From | Subject | Received | Size | Priority | Attachment Flag | MTS-ID |
|---|---|---|---|---|---|---|
| Don Vickers | Florida holidays | 01-Sep-2003 | 4 KB | Normal | No | 42955955 |
| Larry LeMan | Clustering Exchange | 29-Sep-2003 | 3 KB | High | Yes | 48538505 |
| Ken Ewert | Titanium Baby! | 30-Sep-2003 | 948 bytes | Low | No | 42552902 |
| Kieran McCorry | Customer trip report | 30-Sep-2003 | 22 KB | Normal | No | 49919495 |
| Administrator | New cafeteria | 01-Oct-2003 | 2 KB | Normal | No | 41848910 |
The MTS-ID (message identifier) links a row in a message/folder table to the actual content of a message. When a user selects an item and double- clicks to read it, the message ID is used to fetch content from the message table, and the combination of header and content information is used to populate the form used to display the complete message.
Table 7.3 illustrates the type of data we might find in the message table. The message body content is stored in Rich Text Format (RTF). If attachments exist for the message, a pointer appears in the attachment pointer field and the client can use this to retrieve the attachment(s). If message content originated from an IMAP client, it may still be stored in the streamed database. However, tables in the EDB database always hold the properties of the message. The Store retrieves content automatically from the streamed database if necessary and provides it to MAPI clients in RTF format. If the MAPI client then alters the content, the Store removes it from the streamed database into the message table.
| Message ID | To | Message Body Content | Use Count | Attachment Pointer |
|---|---|---|---|---|
| 48538505 | Tony Redmond | Exchange supports multiple databases … | 4 | - |
| 49919495 | Tony Redmond | On my recent trip I visited … | 25 | 66456776 |
| 52195995 | Kieran McCorry | Has anyone tried the new fish dish in … | 1 | - |
The use count field is very important. It contains the count of folders that contain a reference to a message. The count decrements over time as users delete their references to messages. When the use count reaches zero, the Store removes the row from the table.
From reading this brief description of some of the tables inside the Mailbox Store, it is obvious that clients retrieve data from a number of tables when they read messages. Clients are not aware of all the work, because the Store masks the entire interaction through the appropriate service provider. Thus, the MAPI service provider assumes the responsibility of fetching the necessary information whenever Outlook reads a message, as illustrated in Figure 7.3.
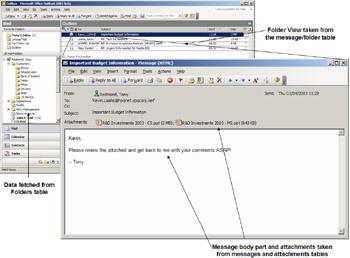
Figure 7.3: How Outlook accesses database tables.
7.3.5 Search Folders
Databases allow you to create many different views of data held in their tables. Search folders (or "smart folders") are Exchange's equivalent of database queries, because they are particular views of data based on underlying tables. Outlook clients have traditionally supported search folders in the "Advanced Find" function, which allows users to search their mailboxes for specific items. However, the resulting search folders are temporary, and, as such, they are volatile because the Store destroys them as soon as the client exits. Outlook 2003 and OWA 2003 now support persistent search folders and incorporate these folders into the standard user interface. Search folders work against Exchange 5.5, 2000, and 2003 servers, but only Exchange 2000 and 2003 allow you to perform a search within a search folder. Clients process items in search folders in exactly the same way as normal folders. In other words, if you delete an item from a search folder, the Store removes it from the underlying table in its "real" folder.
On the surface, search folders seem like a great idea and they are, but they create an additional load for the Store. Active search folders soak up CPU cycles, because the Store has to maintain the temporary search folders. In fact, if you create many search folders in your mailbox, you may slow down the delivery of new messages, because the Store has to check every new message against all the search folders to see whether it has to update the views for any of the temporary folders.
While you can still create search folders from an "Advanced Find" operation, you can also set out to create them from scratch. As you can see in Figure 7.4, you can create search folders based on many different fields, such as messages sent by specific people or to selected distribution groups, message size or age, or messages with flags set. For example, I have a search folder to identify messages that I send to my direct reports, while Outlook 2003 comes with predefined search folders for unread messages (extracted from any folder), large messages (anything larger than 100 KB), and those that are flagged for follow up. The rich OWA client for Exchange 2003 also supports search folders. Apart from identifying the queries for the Store to build folder contents, search folders also register themselves for notification when new items appear in the underlying folders. Thus, if a new message arrives with a large attachment, the Store knows that it must notify the "Large Messages" search folder so that it can update its content.
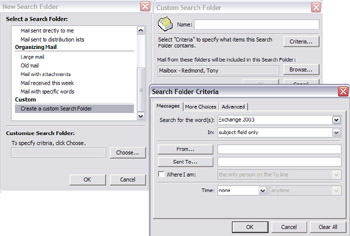
Figure 7.4: Creating search folders.
It is worth noting that search folders exist in the Store and in client-side OSTs. If you create a new search folder on the server, the synchronization process copies the folder to the OST, but the new folder replica is in an "inactive" state, and it remains the responsibility of the "owning" store to populate the search folder. In other words, the synchronization process only moves the query part of a search folder from server to offline store; it does not replicate the results of the query. Therefore, you have to click on the search folder when connected to the server to force the Store to refresh the folder contents, and you have to do the same thing to force Outlook to refresh a client-side search folder when you work offline.
Table 7.4 lists the registry values that you can use to control some aspects of search folder behavior for Outlook 2003. Create the SearchNo- CreateDefaults value at:
HKCU\Software\Microsoft\Office\11.0\Outlook\Options\Setup
while the others are created at:
HKCU\Software\Microsoft\Office\11.0\Outlook\Options\General
| Value | Meaning |
|---|---|
| SearchMaxNumberOnline | Controls maximum number of online search folders. Set to 0 to suppress user interface and stop users from accessing search folders. |
| SearchOnlineKeepAliveDays | Controls the lifetime of online (Store) search folders. If the user does not click on the folder in this time, the Store deactivates the folder (disables notifications) and clears its content. If you set the value to 0, it means that the Store clears the folder contents as soon as the user moves to another folder, which forces repopulation every time a user accesses the folder, thus creating a heavy load for the server. |
| SearchOfflineKeepAliveDays | Controls lifetime of offline (OST) search folders. |
| SearchNoCreateDefaults | Controls whether Outlook creates the three OOTB search folders (such as "Large Messages"). Set the value to 1 to suppress creation. |
Search folders exist in two states: inactive and active. An inactive folder is one that has no notifications registered, so the Store does not maintain its contents. Active folders have notifications registered, so the Store maintains the views for the folder by watching for new items that enter the mailbox and deciding whether they match the underlying folder query. If so, the Store adds the new items to the folder. Users activate search folders by clicking on them. This action registers the notifications and executes the search query against the complete mailbox to populate the folder view. This is the most intensive processing that a search folder imposes on the Store. When you review the search folders in a mailbox, you can recognize the inactive folders easily because Outlook italicizes their names. For example, in Figure 7.5, the "Sent to HPCI CTO DR" folder is inactive, while the other folders are active. In addition, the Store observes normal convention of marking search folders with unread items in bold. If you click on a folder and select "Properties," you can tell Outlook to display the total number of unread items or the total number of items in the folder. Note that OWA only supports access to active online search folders and has no user interface to support the creation of new search folders. Naturally, OWA has no access to offline search folders.
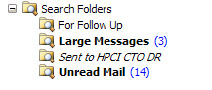
Figure 7.5: Search folders.
By default, a search folder has a lifetime of two months after creation. If the folder is not used, the Store will send a request to the client to ask it to remove the folder to avoid the possibility that old and outdated views continue to absorb performance. However, it is possible for a client to log on once, create a set of search folders, log off, and never reconnect. In this case, the search folders remain active forever, because the Store's request to remove the folder goes into a blank void. There is no way for an administrator to disable search folders, so the only way to minimize their potential impact on performance is to use clients that do not support the feature.
7.3.6 The checkpoint file
ESE maintains a checkpoint file for each storage group. During normal operation, ESE writes transactions in the in-memory queue into databases when system load allows. The checkpoint file (E00.CHK for the default storage group) keeps track of the last committed buffer through a pointer. ESE uses the checkpoint file during "soft" recoveries to determine the point at which to begin replaying transactions. However, if ESE cannot access the checkpoint file, or it does not exist, ESE can examine the transaction log set to determine the replay point.
Exchange adds a further safeguard through a new header in a database that records the generations of log files that are required to make the database consistent, should a recovery operation be necessary. Recovery will stop with a -543 error if a required transaction log file is not available.
You can "force" ESE to flush transactions out of memory and write them to the database by stopping the Store service. This happens when you shut down a system gracefully. If you force Exchange to stop abruptly, such as in the case of a power outage, it is likely that some outstanding transactions remain that the Store has not committed to the physical database. We can gain some insight into the purpose served by the checkpoint file by dumping it with the ESEUTIL utility. Use the ESEUTIL /MK switch for this purpose, which generates a listing similar to that shown in Figure 7.6.
Microsoft(R) Exchange Server(TM) Database Utilities Version 6.0 Copyright (C) Microsoft Corporation 1991-2000. All Rights Reserved. Initiating FILE DUMP mode... Checkpoint file: e00.chk LastFullBackupCheckpoint: (0x0,0,0) Checkpoint: (0x7DD6,2012,B2) FullBackup: (0x7DBF,8,16) FullBackup time: 04/09/2002 20:30:24 IncBackup: (0x0,0,0) IncBackup time: 00/00/1900 00:00:00 Signature: Create time:07/18/2000 11:36:36 Rand:2804053 Computer: Env (CircLog,Session,Opentbl,VerPage,Cursors,LogBufs,LogFile,Buffers) ( off, 252, 37800, 1740, 12600, 128, 10240, 98184) Operation completed successfully in 1.31 seconds.
Figure 7.6: Header dump from a checkpoint file.
The most important field is "Checkpoint," which contains a hex value (0x7DD6) indicating the transaction log generation where the checkpoint is currently positioned. The other values in this field (2012, B2) are internal offsets that only have meaning to the database. The backup fields hold information about the date and time that the last full (April 9, 2002, at 20:30) and incremental backups were started, and the "00/00/1900" date indicates that an incremental backup has never been performed for this storage group. The checkpoint indicates that transaction logs up to generation 7DBF were included in the last full backup. If you compare the signature in the checkpoint file against the storage group signature, you can see that they are identical, so you know that this checkpoint file belongs to that storage group.
During a soft recovery operation, ESE uses the data in the checkpoint file to determine which transactions to replay by comparing the timestamp in the checkpoint file against the transactions in the log files. If the transactions in the logs are newer than the timestamp in the checkpoint file, ESE replays them and writes the transactions into the Store. ESE discards any transactions that do not end in a commit operation, because they are incomplete. Note that replayed transactions do not just include new messages and attachments; they can also include deletions and updates. If ESE has to replay a large number of transactions when a system powers up, the Store update can take a few minutes to complete.
While it is convenient to have the checkpoint file available before beginning a recovery operation, it is not a prerequisite. If ESE finds that the checkpoint file is not available, the logs in the transaction logs directory are scanned (starting at the lowest available generation) to determine the point at which transactions had been committed to the database. Removing the checkpoint file before a recovery operation is not a good thing to do, because it eliminates a safeguard that ensures it recovers the right transactions.
7.3.7 Page checksum
Along with its number, each page holds a checksum in its header. Every time the Store writes a page from memory to disk, it first calculates the checksum, using a very simple algorithm based on the stream of bits in the page, and then writes it into the page header before the page is committed to disk. Calculating the checksum imposes no great overhead on the system. Later, when the Store reads the page from disk, the checksum is recalculated using the same algorithm to ensure that the data in the page has not been changed since it was written. If the calculated checksum does not match the checksum stored in the page header, the page is suspect and a problem may have occurred. In reality, the only way that the checksums can be different is if the page were not written correctly to disk or had not been read correctly from disk. ESE attempts to get around the second issue by rereading the page up to 16 times before concluding that a problem actually exists, but it is obviously much harder to fix a page that the Store never writes properly to disk.
Note that it is the responsibility of the Windows file system and hardware to write data to disk. Exchange simply hands the data to Windows and requests the write. Everything that happens from that point is under the control of first Windows (to pass the write to the hardware) and then the device drivers for the controller and disk hardware (to perform the write). The majority of database problems encountered with Exchange are due to poor quality or poorly maintained hardware. For example, the potential for further problems to occur obviously exists if administrators do not apply firmware updates to either controller or disks to address known bugs.
Some commentators have identified write-back caching as an area that can generate errors for Exchange databases. While it is true that some controllers incorrectly signal the file system that data has been successfully committed before the data is actually written to disk, high-end controllers manage the process by securing data in cache memory that is protected by battery backup. Thus, even if the controller fails, the database can be updated with outstanding transactions through the cached data. You should never use write-back caching with Exchange if unprotected controllers are used. Exchange cannot predict that a problem will occur; it can only report that a problem exists and that it is due to a failure that occurred sometime in the past.
[1] . The concept of B-trees was first described in a paper entitled "Transaction Processing: Concepts and Techniques" by Bayer and McCreight in 1972.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 188