Representing the Legacy Non-XML Grammars in XML
| We'll take a detailed look in the next three chapters at each of the languages we'll use to describe the grammars of our legacy file formats. However, let's look at the overall approach since it will help clarify some of the classes and methods discussed later in this chapter. There are four major areas we want to address here.
Instance Document DesignAs discussed in Chapter 4, the place to start is how we want the instance document to look. The bullet items below outline the major decisions involved. In the next subsection we'll make the same decisions in regard to the file description documents that describe our legacy non-XML formats.
File Description Document DesignGeneral ConsiderationsAs I alluded to previously, in addition to specifying the grammars of our legacy non-XML formats, the file description documents also describe physical characteristics of the input files. For example, we specify record terminators and certain characteristics of the output XML documents such as schema URLs. Again, let's look first at the general choices we need to make about the design of these documents. In the previous section we made decisions about how our instance documents should look. Here we consider how the file description documents should look. We allowed a bit more flexibility in the instance document design than we will here largely due to the variation in legacy file formats. Also, we don't want to impose restrictions where they aren't absolutely required. However, in the case of the file description documents, our processing code is relatively more tightly linked with their document design style. We'll impose a bit more order to make our coding easier.
The other major choice that needs to be made about the general format of the file description documents is how we use Elements and Attributes. This one deserves a bit more discussion than just a bullet point. Reviewing my thought processes and what I ended up doing may help you with similar decisions in the future. My initial inclination was to use only Elements, matching the appearance and processing approach used for the instance documents that correspond to our legacy formats. However, when dealing with the grammars, particularly when considering the grammars of flat files and EDI documents, I wanted to use some Attributes. I felt the grammars would be easier to work with if the nonterminal symbols, such as groups, records, and fields, were represented as Elements. There were a few properties of groups and records that I also needed to represent, but I didn't want to depict those as Elements on a peer level with the Elements representing the grammar symbols. For example, I didn't want a flat file's record identifier tag to be a sibling Element to those representing the fields in the record's grammar. That led to creating a few selected Attributes for such things. Then, as I began to design the code, it became apparent that certain field characteristics, such as column number and data type, might be more easily accessed as Attributes. This was leading me to an inconsistent design in which some parts of the document used only Elements and other parts, in particular the grammar, used only Attributes. In the end I decided to go completely the other way and just use Elements for structure and Attributes to depict all values. Basically, I decided to adopt the approach used in W3C Schema language. I felt consistency was important within the document, that it would make processing the document easier. More importantly, I felt it would be easier for end users of the utilities if I followed a consistent approach for all parts of the document. Major Sections and ElementsThe grammars of our legacy formats are described using the following basic items. The exact Element names may vary depending on the legacy grammar being described.
EDI grammars add another layer, but we'll talk about that in Chapter 9. Schemas for File Description DocumentsGeneral Schema Design ConsiderationsI develop schemas for each of the file description documents and validate the documents against the schemas. Using schema validation enforces some predictability about the documents and makes writing the code to process them a bit easier. As discussed in Chapter 4, several issues must be considered when designing schemas. We'll discuss schema design for application files in the next subsection and in more detail in Chapter 12, but here is a summary of some of the major design decisions regarding the schemas for the file description documents.
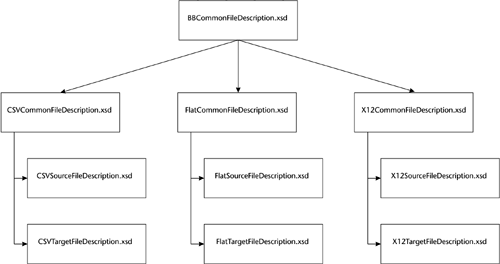
Common Schema for File Description DocumentsThe common schema, BBCommonFileDescription.xsd, defines several types that are reused in the other schemas. In doing so, it uses a few schema features that deserve comment. Since all the data values are conveyed as Attributes of empty Elements, some special things needed to be done. The Primer of the XML Schema Recommendation gives one example of such an empty Element. It defines an anonymous complexType with complexContent but defines no child Elements. It defines only Attributes. This approach works well, except that it derives the complexType by restriction from the anyType data type. This means that in an instance document you may add other Attributes. (It seems that the schema for the W3C XML Schema language takes this approach.) However, I wanted validation to be a bit tighter than that, so I created an EmptyType complexType with no child Elements or Attributes and used it as the restriction base for all types used for Elements. Setting up the DelimiterType for Attributes declaring delimiter values was interesting since there were several choices. The basic requirement for most delimiters, such as column delimiters in a CSV file, was that the user has the ability to declare them as literal characters or as hexadecimal values. The latter is important for EDI files and for future support of EBCDIC-encoded data. My first approach was to declare separate Elements for the character and hex values, but this seemed a bit cumbersome for both the user and for my coding. A second approach suggested that I might just declare the DelimiterType as token with length of one and use the syntax (&#x Hexadecimal number ;) for entering characters to enter the hex values. There are two problems with this approach. The first is that the hex value represented not the actual hexadecimal value in the data stream but the hexadecimal value of the character's "code point" in the ISO/IEC 10646 standard. The concept here is that a number of different characters in different character sets, each having different code points, might all be encoded in a data stream with the same bit pattern. I suspect that most of the potential users of the utilities might be much more familiar with actual encoded hex values than with code points, so this approach didn't seem appropriate. The second problem is that, although I didn't fully investigate this, it appeared to me from the code point ranges listed that it might not be possible to use this syntax to specify control characters encoded with hex values below x20. These control characters are sometimes used as delimiters in EDI syntaxes. This led me to the third approach, which I adopted: to declare the DelimiterType as a union of a token with a length of one and a hexBinary with a length of one. The latter restriction hung me up briefly since the length is not exactly intuitive. The length facet on hexBinary applies to the length of the binary octet that the hexBinary number represents, not the string length of the hexBinary number itself. So, to get a single byte, such as the line feed character, we use a length of one rather than the length of its hexadecimal representation (x0A). It's worth noting, too, that to use delimiters that have special meaning in XML the corresponding predefined entities must be used. For example, use " instead of a literal quotation mark. Defining the RecordTerminatorType was a similar process, except it is a union of a one-byte hexBinary and a token with enumerations of W and U, representing Windows-style and UNIX-style physical record terminators.
Schemas for Source and Target DocumentsHow We'll Use SchemasSchemas for the source and target XML representations of our legacy formats play an important but optional role in this approach. We decided that we'll use our own XML-based languages for describing the grammars of our non-XML formats. In addition, we decided that our utilities, in and of themselves, are not going to perform full validation against business constraints when converting but will perform only the validation necessary for converting our non-XML formats to and from XML. So, what role do schemas play in the architecture? Schemas play an important role by providing the primary means by which business constraints are enforced. We will validate our XML formats against schemas that define the XML representations of our non-XML formats. Rather than writing a lot of our own code to validate business constraints, we're going to take advantage of the schema validation offered by the XML APIs. For example, we won't check the raw X12 850 Purchase Order for compliance with the X12 standard (or implementation guideline). We will instead support schema validation of the XML instance document produced from the X12 850 by our EDI to XML utility. Our common strategy in all of these conversion utilities will be to create a one-for-one correspondence (or, in stricter terms, one-to-one and "on to," or isomorphic, correspondence) between the XML and the non-XML formats. So, if the data satisfies the appropriate business constraints in the XML representation, as defined in a schema, changing the syntax to a non-XML representation should make no difference in satisfying the constraints. The same is true in reverse. Using XML as the format in which our data content is validated further cements XML's central place in our architecture. Creating the SchemasAlthough I recommend that users at least be able to read schemas, I want to avoid any requirement that they be fluent in schema language. The design approach I present here keeps that consideration paramount. KISS comes first. I propose the users start with what is basically a simple approach to designing schemas. I recommend an initial approach of using a tool such as XMLSPY or TurboXML, feeding it an instance document, and having it generate a schema. For most users this will beat hand-coding a schema from scratch every time. Users must review the generated schema and will almost certainly need to clean up and correct a few things such as the assigned data types, minOccurs, and maxOccurs. (This is discussed in more detail in Chapter 7.) However, this approach is much easier than trying to create a schema completely by hand. If such a tool isn't available, users can take the examples from the next three chapters and hack them up in a text editor or XML Notepad to suit their needs. However, I highly recommend a full-featured XML tool. If a user is fluent with schema language, he or she could do something as ambitious as developing type libraries for the segments and data elements in the full UN/EDIFACT standard. I'll discuss some considerations and approaches in more detail in Chapter 12. But if he or she just wants to load a document into a tool like XMLSPY and click on Create Schema, that's okay too. The important thing to note is that users have considerable freedom in developing schemas that meet their needs. |
EAN: 2147483647
Pages: 181