| If you have reviewed Chapters 7 and 8, you should have a fairly good understanding of the architecture and basic coding approach used for these utilities. You will find that the utilities developed in this chapter have many similarities to those developed in the two previous chapters. However, X12 interchanges are very different in some key aspects from CSV files and flat files, so we will see some interesting processing differences. As with Chapter 8 I will focus on the unique aspects of these utilities and refer you back to Chapter 7 if you wish to better understand the architecture and coding approach. Main Program As with the other utilities our main program is a basic shell that calls methods from the SourceConverter base class. Logic for the Shell Main Routine for X12 to XML Arguments: Input File Name Output Directory Name Directory Path Name for File Description Documents Options: Validate output Help Validate and process command line arguments IF help option specified Display help message Exit ENDIF Create new X12SourceConverter object, passing: Validation option Output Directory Directory Path for File Description Documents Call X12SourceConverter processFile method, passing the input file name Display completion message The main difference between this and the CSV and flat file main programs is that instead of dealing with a specific file description document we deal with a directory path where we can find them. This is due to the fact that an X12 interchange may contain several types of transaction sets, each of which requires a different file description document. We use information from the control segments in the X12 interchange to identify the type of conversion we need to perform. Then we load the appropriate file description document from the source directory based on the naming convention specified at the beginning of this chapter. X12SourceConverter Class (Extends SourceConverter)
Overview The X12SourceConverter is the main driver for the actual conversion. It inherits all the attributes and methods of its base classes, the SourceConverter and Converter classes. Attributes: -
X12RecordReader Object -
String FDD Path (file description document directory path) -
String Saved FDD Name -
String Output Directory Path -
String FA Output Directory Path -
String Group SenderID -
String GroupID -
String X12Version -
String Tag -
String Included Transaction Sets -
Integer Received Transaction Sets Methods: -
Constructor -
processFile -
processDocument -
writeFunctionalAck Methods Constructor The constructor method for our X12SourceConverter object sets up that object as well as the X12RecordReader object. Logic for the X12SourceConverter Constructor Method Arguments: Boolean Validation option String Output Directory Name String File Description Document Directory Path Call base class constructor FDD Path <- From passed path name Create FA_Out directory Create X12RecordReader object processFile The main processing is driven by the X12SourceConverter's processFile method. Note that there are several differences between this method and the one in the FlatSourceConverter. This method processes the control segments for the interchange and functional groups, then calls processDocument to process each transaction set. Logic for the X12SourceConverter processFile Method Arguments: String Input File Name Returns: Status or throws exception Open input file Call X12RecordReader's setInputStream method Call X12RecordReader's parseISA method Call X12RecordReader's logISA method Record Length <- Call RecordReader's readRecordVariableLength IF Record Length = 0 Return Error ENDIF Tag <- Call X12RecordReader's getRecordType DO while Tag = GS to process all functional groups Call X12RecordReader's parseGS method Call X12RecordReader's logGS method Group Sender ID <- Call X12RecordReader's getControlSegmentElement for GS02 Group ID <- Call X12RecordReader's getControlSegmentElement for GS01 X12Version <- Call X12RecordReader's getControlSegmentElement for GS08 Output Directory Path <- Base Directory + Group Sender ID + Group ID + directory separator Create Output Directory Record Length <- Call RecordReader's readRecordVariableLength IF Record Length = 0 Return Error ENDIF Tag <- Call X12RecordReader's getRecordType Received Transaction Sets <- 0 DO while (Tag = ST) to process all transaction sets Increment Received Transaction Sets Status <- call processDocument IF Status != SUCCESS Return error ENDIF ENDDO IF Tag != GE Return Error ENDIF Call X12RecordReader's parseGE method Call X12RecordReader's logGE method Included Transaction Sets <- call X12RecordReader's getControlSegmentElement for GE01 IF GSID != "FA" Call writeFunctionalAck ENDIF Record Length <- Call RecordReader's readRecordVariableLength IF Record Length != 0 Tag <- Call X12RecordReader's getRecordType ELSE Return error ENDIF ENDDO IF (Tag != IEA) Return Error ENDIF Call X12RecordReader's parseIEA method Call X12RecordReader's logIEA method Close input file Return success processDocument The processDocument method reads and processes a single X12 transaction set starting with the ST header and ending with the SE trailer. This method loads the appropriate file description document if one is not already loaded, and based on it the method creates and saves a single output XML document representing the transaction set. Logic for the X12SourceConverter processDocument Method Arguments: None Returns: Status or throws exception Call X12RecordReader's parseST method Call X12RecordReader's logST method Transaction SetID <- From ST01 FDD Name <- FDD Path + Group Sender ID + '-' + Group ID + '-' + Transaction SetID + "-" + Version/Release + ".xml" IF (FDD Name != Saved FDD Name) Call loadFileDescriptionDocument, passing FDD Name Call EDIRecordReader's setFileDescriptionDocument Saved FDD Name <- FDD Name Schema Location URL <- from File Description Document Throw exception if no schema and validation requested ENDIF Create new Output DOM Document Create Root Element, using Root Element Name from Grammar, and append to Output DOM Document IF Schema Location URL is not NULL Create namespace Attribute for SchemaInstance and append to Group Element Create noNamespaceSchemaLocation Attribute and append to Root Element ENDIF Call RecordReader's setOutputDocument method for new document Transaction Set Control Num <- ST02 Output File Path <- Output Directory Path + Root Element Name + Transaction Set Control Num + ".xml" Record Length <- Call RecordReader's readRecordVariableLength IF Record Length = 0 Return error ENDIF Tag <- Call X12RecordReader's getRecordType Child Node <- Get Grammar Element's firstChild DO while Child Node is not an Element Node Child Node <- ChildNode's nextSibling ENDDO Segment Grammar Element <- Child Node Grammar Tag <- Call Segment Grammar getAttribute for "TagValue" DO until (Tag = SE) at end of transaction set DO until Grammar Tag = Tag Child Node <- ChildNode's nextSibling IF Segment Grammar Element is NULL return error // This Segment is not part of the document ENDIF IF Child Node nodeType != ELEMENT CONTINUE ENDIF Segment Grammar Element <- Child Node Grammar Tag <- Call Segment Grammar getAttribute for "TagValue" ENDDO Grammar Element Name <- Segment Grammar getNodeName IF Grammar Element Name = "GroupDescription" Record Length = Call processGroup, passing Root Element and Segment Grammar Element ELSE Call X12RecordReader's parseRecord, passing Segment Grammar Element Call X12RecordReader's toXML Call X12RecordReader's writeRecord, passing Root Element and Segment Grammar Element Record Length <- Call RecordReader's readRecordVariableLength ENDIF IF Record Length = 0 Return error ENDIF Tag <- Call X12RecordReader's getRecordType ENDDO Call X12RecordReader's parseSE method Call X12RecordReader's logSE method Call saveDocument Record Length <- Call RecordReader's readRecordVariableLength IF Record Length = 0 Return error ENDIF Tag <- Call X12RecordReader's getRecordType Return Success The logic and operations are very similar to those in the SourceConverter's processGroup method developed in Chapter 8. You'll note that the logic for the main DO loop here is almost an exact match for the logic in the main DO loop of that method. In addition to the functional differences noted at the beginning of this section, the main differences are due to the structure of X12 interchanges as defined in the standards. A transaction set must start with an ST segment and end with an SE segment. We enter the method after having just read an ST segment, and the last segment we process is an SE segment. We exit the method after reading the next segment. We also know from the standards that the trailing SE segment must be followed by either another ST header segment or the GE group trailer segment. If we reach the end of the file at any point in this routine, we are processing an incomplete interchange and return an error. writeFunctionalAck This method writes an XML representation of the 997 Functional Acknowledgment. Since we use the 997 only as a return receipt, to indicate acceptance of the group and not to report errors, we write data only sufficient for writing the AK1 and AK9 segments. Logic for the X12SourceConverter writeFunctionalAck Method Arguments: None Returns: Status or throws exception Output File Name <- FA Output Directory Path + GS Sender ID + "-" + Functional Group ID Code + ".xml" Create output DOM FA Document Create Root Element "TS997" and append to FA document Create AK1 Element and append to Root Create AK101 Element and append to AK1 Create Text Node with Functional Group ID Code and append to AK101 Create AK102 Element and append to AK1 Create Text Node with GS Control Number and append to AK102 Create AK9 Element and append to Root Create AK901 Element and append to AK9 Create Text Node with "A" and append to AK901 Create AK902 Element and append to AK9 // AK902 is count of included transaction sets from GE01 Create Text Node with Included Transaction Sets and append to AK902 // AK903 is count of transaction sets actually received in group Create AK903 Element and append to AK9 Create Text Node with Received Transaction Sets and append to AK903 // AK904 is count of transaction sets accepted - We're going to // say we accepted all of them that we received Create AK904 Element and append to AK9 Create Text Node with Received Transaction Sets and append to AK904 Save FA Document EDIRecordReader Class (Extends RecordReader) Overview The EDIRecordReader is the generalized base class for several derived classes that deal with specific EDI syntaxes. In this chapter we develop an X12RecordReader derived class. However, as you'll see, the attributes and methods we develop here are applicable to other syntaxes, so we move them to a common base class. Attributes: -
Character Element Separator -
Character Component Separator -
Character Repetition Separator -
Character Release Character Methods: Methods Constructor The EDIRecordReader constructor method does very little processing. It calls the base RecordReader constructor method, passing along the null value for the file description document, and initializes the class member attributes. getRecordType This method extracts the segment identifier from the input record buffer. Logic for the EDIRecordReader getRecordType Method Arguments: None Returns: Record ID tag value; throws exception or returns status Record Tag Value <- Get first characters of input record up to the Element Separator Return Record Tag Value or status parseRecord This is perhaps the most interesting method developed in this chapter. To develop it we draw on the BNF grammar analysis presented at the start of the High-Level Design Considerations section. We'll start with some general observations that lead us to the characteristics and outlines of a processing algorithm. The state transition diagram will follow that. We'll finish off with the full algorithm. As I said in the grammar analysis, the grammar of EDI segments is fairly complex. If for no other reason this is due to the number of productions . It would take a fairly complex state machine and associated algorithm to directly implement the grammar I outlined. Fortunately, we don't have to take that approach. We can simplify things somewhat by observing that we mainly want to extract data from simple data elements. From strictly that perspective we don't care very much whether an element is a stand-alone simple data element, a component data element within a composite data structure, an instance of a repeating simple element, or a component data element within an instance of a repeating composite. We do, of course, in the big picture care about these distinctions, but not when it comes to parsing the input segment. We care about them when we actually save the data. The good news is that we have a way to make these distinctions when we save the data. We have the segment grammar, and if we walk the grammar as we parse the segment, we can make the necessary distinctions. So, here is the general outline of a processing algorithm. We maintain pointers to the current DataCell and the current grammar Element. We also maintain a pointer to the grammar for the current composite data structure. -
We start processing by parsing past the segment identifier to the first element separator. -
If we encounter a delimiter such as an element separator, a component data element separator, or a repetition separator, we point the current grammar Element to the appropriate element within the segment or composite grammar. We also clear the pointer to the current DataCell. -
If we encounter a normal character in an input stream, we save it. If the current DataCell pointer is null, we first create a new DataCell, passing the current grammar Element. -
If we encounter the release character, we treat the next character as a normal character and save it. -
If we encounter a delimiter that should not immediately follow a different delimiter, we move to an error state. Examples of this type of error would be the cases of a repetition separator or a data element separator immediately following a component data element separator. These cases indicate an invalid segment because trailing component data element separators within a composite data structure are not allowed. -
The last character in the segment immediately preceding the segment terminator should be a normal character and not a delimiter. We can check for this condition by testing whether or not the current DataCell pointer is null. If it is null, the last character processed was a delimiter and we exit the routine with an error. If it isn't null, the last character processed was a normal character and we exit the parsing routine normally. With this outline we can construct the state transition diagram shown in Figure 9.1. Four states correspond to each of our four delimiters, one state corresponds to a data element, and one is an error state. To make the state machine more closely reflect the sense of the algorithm, I named the states for the actions taken rather than for the symbol from the segment grammar. -
Next Element, entered after parsing the data element separator : If the element position within the segment is greater than the Field Number of the current Grammar Element, advance the current Grammar Element until the Field Number is equal to or greater than the Element Position. If greater, set the current Grammar Element to null. Otherwise, if the current Grammar Element describes the grammar of a composite data structure, point the current composite grammar pointer to it and set the current Grammar Element to point to its first child Element. Otherwise , clear the current composite grammar pointer. Clear the DataCell pointer. -
Next Component, entered after parsing the component data element separator : Point the current Grammar Element to the next child Element of the current composite Grammar Element. Clear the DataCell pointer. -
Next Repeat, entered after parsing the repetition separator : If the composite grammar pointer is null, we don't change the current Grammar Element. If it is not null, we reset the current Grammar Element to point to the first child of the current composite Grammar Element. Clear the DataCell pointer. -
Escape, entered after parsing the Release character : Set the current state to Save Character so that the next character in the segment is saved. -
Save Character, entered after parsing a normal character or an escaped delimiter : If the DataCell pointer is null, create a new DataCell. Save the current character to the DataCell. -
Error, entered after encountering a parsing error in one of the other states : Terminate processing and exit the routine. Figure 9.1. State Transition Diagram for Parsing an EDI Segment 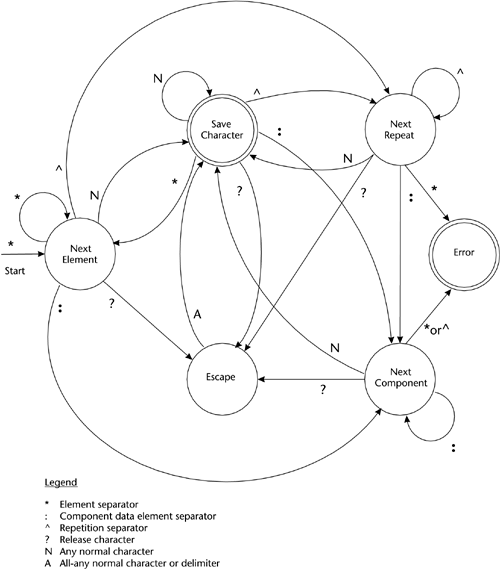 In Figure 9.1 the double circle on the Save Character state indicates an accepting state and on the Error state indicates a termination state. From the perspective of more formal analysis, this outline makes a lot of sense. If we were to successively replace each of the nonterminal symbols in the productions of the segment grammar with terminal symbols (with a bit of leeway for the char and special char productions), we could eventually reduce the grammar to a single production. It would not be very readable or useful, but it would be a single production. Most importantly, it would be a single production that could be converted to a regular expression. This is significant because it proves that we can process a segment grammar with a finite state automaton and the type of state transition diagram shown in Figure 9.1. I leave to you the exercise of actually performing the reduction and creating the regular expression. The diagram is convincing enough for me. Finally, we combine the outline of the algorithm and the information from the state transition diagram, yielding the following processing algorithm. When we enter the method there's a segment loaded in the Record Buffer and we have identified the segment type. The method has also been passed the Grammar Element for the segment. When reviewing the algorithm, bear in mind that if a data element isn't used in a segment or composite data structure, we don't require that it be defined in the grammar. So, we advance through the grammar as we advance through the appropriate delimiters, but we match data element position within segment against the Grammar Element's FieldNumber Attribute and component data element position within composite data structure against the Grammar Element's SubFieldNumber Attribute. The Save Character state is the only accepting state or successful completion state. If we exit the main loop in any other state, the segment is invalid because it ends with a delimiter. In such cases we move to the Error state. Logic for the EDIRecordReader parseRecord Method Arguments: DOM Element Segment Grammar Returns: Error status or throw exception Segment Child <- get Segment Grammar's firstChild DO until Segment Child nodeType is Element Segment Child <- Segment Child nextSibling ENDDO Current Grammar <- Segment Child Grammar Position <- Current Grammar getAttribute for Field Number Composite Grammar <- null Element Position <- 0 Component Position <- 0 Parsing State <- Next Element Advance Pos to point to the Record Buffer's first Element Separator DO while Pos < Buffer Length and Parsing State != Parsing Error CurChar = Record Buffer[Pos] // Advance to the next state DO CASE of Parsing State Next Element: IF CurChar = Element Separator Parsing State = Next Element ELSE IF CurChar = Component Separator Parsing State = Next Component ELSE IF CurChar = Repetition Separator Parsing State = Next Repeat ELSE IF CurChar = Release Character Parsing State = Escape ELSE Parsing State = Save Character ENDIF ENDIF ENDIF ENDIF BREAK Next Component: IF CurChar = Element Separator Parsing State = Parsing Error ELSE IF CurChar = Component Separator Parsing State = Next Component ELSE IF CurChar = Repetition Separator Parsing State = Parsing Error ELSE IF CurChar = Release Character Parsing State = Escape ELSE Parsing State = Save Character ENDIF ENDIF ENDIF ENDIF BREAK Next Repeat: IF CurChar = Element Separator Parsing State = Parsing Error ELSE IF CurChar = Component Separator Parsing State = Next Component ELSE IF CurChar = Repetition Separator Parsing State = Next Repeat ELSE IF CurChar = Release Character Parsing State = Escape ELSE Parsing State = Save Character ENDIF ENDIF ENDIF ENDIF BREAK Escape: Parsing State = Save Character BREAK Save Character: IF CurChar = Element Separator Parsing State = Next Element ELSE IF CurChar = Component Separator Parsing State = Next Component ELSE IF CurChar = Repetition Separator Parsing State = Next Repeat ELSE IF CurChar = Release Character Parsing State = Escape ELSE Parsing State = Save Character ENDIF ENDIF ENDIF ENDIF BREAK ENDDO // Take action appropriate to state DO CASE of Parsing State Next Element: CurrentCell = null Increment ElementPosition // Get the next the Grammar Element for the next data // element in the segment DO while Element Position > Grammar Position Segment Child <- Segment Child nextSibling IF Segment Child = null Return error for no Grammar Element ENDIF IF Segment Child nodeType != Element CONTINUE ENDIF Grammar Position <- Current Grammar getAttribute for "FieldNumber" ENDDO // If we find a match then do the setup, otherwise set // the current Grammar Element to null IF Element Position = Grammar Position Node Name <- Segment Child nodeName IF Node Name = "CompositeStructureDescription" Composite Grammar <- Segment Child Composite Child <- Composite Grammar firstChild DO until Composite Child nodeType is Element Composite Child <- Composite Child nextSibling ENDDO Current Grammar <- Composite Child Component Position <- 1 ELSE Composite Grammar <- null Composite Child <- null Component Position <- 0 Current Grammar <- Segment Child ENDIF ELSE Current Grammar <- null ENDIF BREAK Next Component: CurrentCell = null Increment Component Position Grammar SubPosition <- Current Grammar getAttribute for "SubFieldNumber" // Get the next Grammar Element for the next data // element in the Composite DO while Component Position > Grammar SubPosition Composite Child <- CompositeChild nextSibling IF Composite Child = null Return error for no Grammar Element ENDIF IF Composite Child nodeType != Element CONTINUE ENDIF Grammar SubPosition <- Current Grammar getAttribute for "SubFieldNumber" ENDDO // If we find a match then do the setup, otherwise set // the current Grammar Element to null IF Component Position = Grammar SubPosition Current Grammar <- Composite Child ELSE Current Grammar <- null ENDIF BREAK Next Repeat: // If we're processing a composite, reset the grammar and // index back to the start of the composite. Otherwise // do nothing and stay with the current grammar. Current Cell = null IF Composite Grammar != null Composite Child <- Composite Grammar firstChild DO until Composite Child nodeType is Element Composite Child <- Composite Child nextSibling ENDDO Current Grammar <- Composite Child Component Position <- 1 ENDIF BREAK Release: // Take no action BREAK Save Character: IF Current Cell = null IF Current Grammar = null Return error for no Grammar Element ENDIF Current Cell = call createDataCell, passing Element Position and Current Grammar IF ComponentPosition != 0 Call Current Cell's setSubFieldNumber, passing Component Position ENDIF ENDIF Call Current Cell putByte, passing CurChar BREAK Parsing Error: // Take no action BREAK ENDDO Increment Pos ENDDO // Check if we are finishing with a delimiter IF Parsing State != Save Character Parsing State = Parsing Error ENDIF IF Parsing State = Parsing Error Display parsing error message with Element Position, Component Position, Pos, and segment contents Return error ENDIF Return success One restriction needs to be noted regarding the algorithm. While it parses input correctly, the actions taken in the Next Repeat state may not meet all requirements. The X12 Design Rules imply that the position of a particular instance of a repeating data element may have semantic significance. I've not investigated the UN/EDIFACT rules, but I wouldn't be surprised if they said something similar. But regardless of what the standards say, there may certainly be implementations where position within a repeating data element is significant. For example, there might be a usage in which the first occurrence of an element would be loaded into the first column of a spreadsheet row while the fifth occurrence (or fourth repetition) would be loaded into the fifth column. In this parsing algorithm positional information is lost if there are empty data elements within a repeat since we don't write empty XML Elements from them. If the second repetition were missing in our example, repeats three and later would be shifted one column to the left. I'm not sure how significant this deficiency is, but investigating and perhaps providing better repeat support is among the version 1.0 requirements for the Babel Blaster project. Again, repeating data elements were not supported at all in X12 004010, which is the initial focus of these utilities. setFileDescriptionDocument The constructors in the CSV and flat file record readers set the file description document pointer for us. However, when processing EDI we need to read from the interchange before the SourceConverter loads the file description document. In addition, we may use several such documents while processing an interchange. This method gives us a way to set and change the file description document. Logic for the EDIRecordReader setFileDescriptionDocument Method Arguments: DOM Document File Description Document Returns: Nothing Base RecordHandler File Description Document <- From passed DOM Document File Description Document Return Note : I contemplated moving this method to the base RecordHandler class but didn't because I couldn't think of any class other than the EDIRecordReader that needed it. writeRecord This method is very similar to the one in the base RecordWriter class. It creates an XML Element that represents a segment (or record) and writes the contents of the DataCell Array to child Elements of the record Element. We could use that base class method if it weren't for the fact that for EDI formats we also write Elements that correspond to composite data structures. These have child Elements that correspond to the component data elements within a composite. So, we are faced with the classic conundrum of object-oriented analysis and design: What do we put in the generalized base class and what do we put in the specialized derived class? This is a particularly thorny problem when it comes to methods that are very similar in the base and derived classes. My gut feeling tells me not to unnecessarily risk breaking something that already works. So, rather than including logic in the base class method to handle the special case of composite data structures, I'm going to develop a specialized method for this derived class. If it appears similar enough and doesn't break any of the functionality in the base class method, for Babel Blaster version 1.0 I may promote it to the base class. The main difference between this and the base RecordWriter's writeRecord method is that we get a NodeList of the segment Grammar Element's composite data structure grammars. If a DataCell Array entry has a subField number, we find the grammar for the appropriate composite and make the new Element a child of the composite. Logic for the EDIRecordReader writeRecord Method Arguments: DOM Element Output Document Parent Element DOM Element Record Grammar Element Returns: Status or throws exception Element Name <- Call Grammar Element's getAttribute for "ElementName" Record Element <- call Output Document's createElement, passing Element Name Parent Element <- call Parent's appendChild to append Record Element Current Parent <- RecordElement Composite Parent <- null Composite Position <- 0 Composite Grammars <- call Record Grammar's getElementsByTagName for "CompositeStructureDescription" DO for all DataCells in array up through Highest Cell // Test if this is a component within a composite Component Position <- call DataCell's getSubFieldNumber IF Component Position != 0 // See if we are starting a new composite Cell Field Number <- Call DataCell's getFieldNumber IF Cell Field Number != Composite Position // Find the grammar and create the Element DO for all Elements in Composite Grammars NodeList until Cell Field Number = Composite Position Composite Position <- Call Composite Grammars item's getAttribute for "FieldNumber" ENDDO Composite Name <- Call Composite Grammars current item Element's getAttribute for "ElementName" Composite Parent <- call Output Document's createElement, passing Composite Name Record Element <- call Record Element appendChild to append Composite Parent Current Parent <- Composite Parent ENDIF ELSE // simple element Current Parent <- Record Element Composite Parent <- null Composite Position <- 0 ENDIF Call toElement on Cell Array entry, passing Current Parent Clear Cell Array Entry ENDDO Highest Cell <- -1 I should note that this algorithm does not properly support all aspects of repeating data elements. It will work fine if the repeated data elements are simple data elements. However, it will not work correctly if the repeating unit is a composite data structure. All the child component data elements for all repetitions would be written under one composite parent Element in the output XML document. This is yet another area where current support is limited to version 004010 of X12 and where we have another requirement for Babel Blaster version 1.0. My impression is that we might fix this by adding a RepeatPosition member attribute to the DataCell class. We would set it in the parseRecord method and in this method check for a break in RepeatPosition to see if we need to write a new composite parent Element. We could also use RepeatPosition to write a RepeatPosition Attribute to the output XML Element for a repeating Element. X12RecordReader Class (Extends EDIRecordReader) Overview The EDIRecordReader is the generalized base class for several derived classes dealing with specific EDI syntaxes. The X12RecordReader has attributes and methods that deal specifically with X12 control segments. The current implementation is hard-coded to support version 004010 of X12. One of the Babel Blaster 1.0 requirements is to enable support for different versions. Attributes: -
String array for data elements from the ISA Interchange Control Header segment -
String array for data elements from the GS Functional Group Header segment -
String array for data elements from the ST Transaction Set Header segment -
String array for data elements from the GE Functional Group Trailer segment Methods: -
Constructor -
getControlSegmentElement -
logGE -
logGS -
logIEA -
logISA -
logSE -
logST -
parseGE -
parseGS -
parseIEA -
parseISA -
parseSE -
parseST Methods Most of the methods do very little, so with a few exceptions I'll discuss them only in general terms. The constructor method calls the EDIRecordReader constructor, initializes the class member attributes, and exits. The parse methods simply use the language-specific string token routines to parse the Record Buffer and load the class member attributes corresponding to the data elements in the segment. The log methods in this initial implementation display segment information from the appropriate class member attributes. A requirement for later Babel Blaster versions is to enhance these log routines to write output to a data store. We may not use or call all the methods in this version, so some of them exist for future requirements. Note when examining the code that the text strings in the log methods are hard-coded and not set by parameters. The X12 standards are most commonly used by English speakers . Expressing all of the message text as parameters adds coding complexity. Since these methods will probably be completely rewritten in the next version I didn't think it appropriate. getControlSegmentElement Since there are several values that other classes need to retrieve from the header and trailer control segments, we develop a generalized method to retrieve them. Logic for the X12RecordReader getControlSegmentElement Method Arguments: String Segment ID Integer Element position within segment Returns: Status or throws exception IF Segment ID = "ISA" Return ISA[Element position] ENDIF IF Segment ID = "GS" Return GS[Element position] ENDIF IF Segment ID = "GE" Return GE[Element position] ENDIF IF Segment ID = "ST" Return ST[Element position] ENDIF IF Segment ID = "SE" Return SE[Element position] ENDIF Return failure parseISA The parseISA method is perhaps the most important method in the X12Record Reader class. It parses the Interchange Control Header segment and loads the base class delimiters based on the parsing results. Logic for the X12RecordReader parseISA Method Arguments: None Returns: Status or throws exception Record Buffer <- call language-specific routines to read 106 bytes from input file stream Buffer Length <- 106 IF character at Record Buffer index 93 = '-' Get one more byte from input file and append to Record Buffer Buffer Length <- 107 ENDIF IF Record Buffer doesn't start with "ISA" Return Error for not an ISA segment ENDIF Element Separator <- Record Buffer at index 3 Component Separator <- Record Buffer at index Buffer Length - 2 Record Terminator1 <- Record Buffer at index Buffer Length - 1 Using language-specific string token routines, load class attributes ISA01 through ISA16 Once again this method is hard-coded to process version 004010 of X12 since it doesn't look for the Repetition Separator in ISA11. One other little bit of code deserves comment. It is a common belief that the ISA segment has a fixed length of 106 bytes. Most commercially available EDI translators rely on this assumption. Strictly speaking, the ISA segment doesn't have a fixed length; all the data elements within it do since their minimum length is the same as their maximum length. However, the N0 data type of the ISA13 Interchange Control Number allows a leading minus sign, and X12.6 says that leading minus signs are not counted against maximum length requirements. So, in nearly all circumstances an actual data stream has a control number of 9 bytes. However, I do know of at least one usage (to me, an odd one) where a negative control number can appear and ISA13 is 10 bytes long, yielding a 107-byte ISA segment. It takes only a couple lines of code to support this little quirk, so I thought I would throw it in.  |