Lesson 1: Introducing Replication
3 4
SQL Server 2000 has several different replication solutions to enable you to distribute data and stored procedures between servers in your environment. In this lesson, you will learn about uses for replication and the terminology used in replication. Next, you will learn about each type of replication. You will also learn about physical replication topologies. Finally, you will learn about the different tools available for implementing a replication solution.
After this lesson, you will be able to
- Understand the replication terminology
- Describe how each type of replication functions
- Select among physical replication topologies
- Choose replication implementation tools
Estimated lesson time: 15 minutes
Describing Replication
Replication is the process of automatically distributing copies of data and database objects among SQL Server instances, and keeping the distributed information synchronized.
Reasons to Replicate Information
There are many reasons to replicate data and stored procedures among servers. These include
- Reducing network traffic between separate physical locations—Rather than requiring users in the New York office of a company to query data on a server in London across a link with limited bandwidth, the data could be replicated to a server in New York (at a time when the bandwidth was not heavily used) and accessed locally.
- Separating OLTP operations from decision support functions—Rather than having decision support personnel query a busy OLTP server, the data could be replicated to a dedicated decision support server for querying.
- Combining data from multiple locations—Data can be entered into a local SQL Server instance at each of several regional offices of a company and then replicated to the national (or international) office and merged automatically.
- Data redundancy—Data can be replicated to a standby server, which can be used for decision support queries, and provide a copy of data in the event of a server failure.
- Scaling out—Data that you make available over the Internet can be replicated to various servers in different geographic regions for load balancing.
- Supporting mobile users—Data can be replicated to laptop computers, which can be updated offline. When the mobile users reconnect to the network, changed data can be replicated to and synchronized with a centralized database.
Types of Replication
SQL Server 2000 supports three types of replication: snapshot, transactional, and merge. Snapshot replication is the periodic replication of an entire set of data as of a specific moment in time from a local server to remote servers. You would typically use this type of replication in databases where the amount of data to be replicated is small and the source data is static. You can grant remote servers a limited capability to update the replicated data. Transactional replication is the replication of an initial snapshot of data to remote servers plus the replication of individual transactions occurring at the local server that incrementally modify data contained in the initial snapshot. These replicated transactions are applied to the replicated data at each remote server to keep the data on the remote server synchronized with the data on the local server. You use this type of replication when you must keep the data current on the remote servers. You can grant remote servers a limited capability to update the replicated data. Merge replication is the replication of an initial snapshot of data to remote servers plus the replication of changes that occur at any remote server back to the local server for synchronization, conflict resolution, and re-replication to remote servers. You use merge replication when numerous changes are made to the same data, or when remote offline computers need to operate autonomously, such as in the case of a mobile user.
Replication Terminology
SQL Server replication uses terminology from the publishing industry to represent the components of replication. The server that is replicating stored information to other servers is called the Publisher. The information being replicated consists of one or more publications. Each publication is a logical collection of information from a single database consisting of one or more articles. An article can be one or more of the following:
- Part or all of a table (can be filtered by columns and/or rows)
- A stored procedure or view definition
- The execution of a stored procedure
- A view
- An indexed view
- A user-defined function
Each Publisher uses a Distributor to assist in the replication process. The Distributor stores the distribution database, history information, and metadata. The exact role of the Distributor varies with the type of replication. The Distributor used by a Publisher can be either local (the same SQL Server instance) or remote (a separate SQL Server instance).
Servers that receive replicated information are called Subscribers. Subscribers receive selected publications (called a subscription) from one or more Publishers. Depending upon the type of replication being implemented, Subscribers may be permitted to modify replicated information and replicate the changed information back to the Publisher. Subscribers can be specifically authorized or can be anonymous (such as for Internet publications). With large publications, the use of anonymous subscriptions can improve performance.
The replication process is automated through the use of replication agents. A replication agent is generally a SQL Server Agent job configured by an administrator to perform specified tasks on a specified schedule. By default, replication agents run in the security context of the SQL Server Agent domain user account on Windows 2000 and Windows NT 4.0. They run in the security context of the logged-in user on Windows Me and Windows 98. There are a number of replication agents for different replication tasks. Each agent is configured to run according to a specified schedule. Different types of replication use one or more of these agents.
- Snapshot Agent—Creates an initial snapshot of each publication being replicated, including schema information. All types of replication use this agent. You can have one Snapshot Agent per publication.
- Distribution Agent—Moves snapshot information and incremental changes from the Distributor to Subscribers. Snapshot and transactional replication use this agent. By default, all subscriptions to a publication share one distribution agent (called a shared agent). However, you can configure each subscription to have its own distribution agent (called an independent agent).
- Log Reader Agent—Moves transactions marked for replication from the transaction log on the Publisher to the Distributor. Transactional replication uses this agent. Each database that you mark for transactional replication will have one Log Reader Agent that runs on the Distributor and connects to the Publisher.
- Queue Reader Agent—Applies changes made by offline Subscribers to a Publication. Snapshot and transactional replication use this agent if queued updating is enabled. This agent runs on the Distributor and only one instance of this agent exists to service all Publishers and publications for a given Distributor.
- Merge Agent—Moves snapshot information from the Distributor to Subscribers. It also moves and reconciles changes to replicated data between the Publisher and Subscribers. This agent also deactivates subscriptions whose data has not been updated within a maximum publication retention period (14 days by default). Merge replication uses this agent. Each subscription to a merge publication has its own merge agent that synchronizes data between the Publisher and the Subscriber.
- Agent History Clean Up Agent—Removes agent history from the distribution database and is used to manage the size of the distribution database. All types of replication use this agent. This agent runs every 10 minutes by default.
- Distribution Clean Up Agent—Removes replicated transactions from the distribution database, and deactivates inactive Subscribers whose data has not been updated within a specified maximum distribution retention period (72 hours by default). If anonymous subscriptions are permitted, replicated transactions are not removed until the maximum retention period expires. Snapshot and transactional replication use this agent. This agent runs every 10 minutes by default.
- Expired Subscription Clean Up Agent—Detects and removes expired subscriptions. All types of replication use this agent. This agent runs once a day by default.
- Reinitialize Subscriptions Having Data Validation Failures Agent—Reinitializes all subscriptions having data validation failures. This agent is run manually by default.
- Replication Agents Checkup Agent—Detects replication agents that are inactive and logs this information to the Windows application log. This agent runs every 10 minutes by default.
Note
The Snapshot Agent, Distribution Agent, and Merge Agent can be embedded into applications using ActiveX controls.
Understanding the Types of Replication
To implement replication, you must understand how each type of replication functions. Each type of replication provides a replication solution with a different set of tradeoffs.
Snapshot Replication
With snapshot replication, the Snapshot Agent periodically (according to a specified schedule) copies all data marked for replication from the Publisher to a snapshot folder on the Distributor. The Distribution Agent periodically copies all the data in the snapshot folder to each Subscriber and updates the entire publication at the Subscriber with the updated snapshot information. The Snapshot Agent runs on the Distributor, and the Distribution Agent can run either on the Distributor or on each Subscriber. Both agents record history and error information to the distribution database. Figure 15.1 illusrates the snapshot replication process.
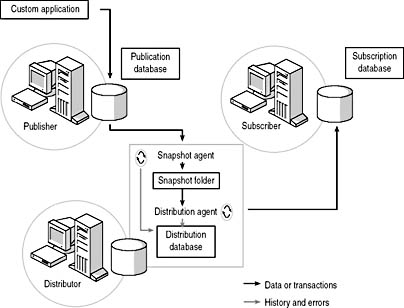
Figure 15.1
The snapshot replication process.
Snapshot replication is most appropriate for data that does not change rapidly, for small publications that can be refreshed in their entirety without overwhelming the network, and for information that does not need to be completely current all the time (such as historical sales information).
With snapshot replication, you can elect to permit Subscribers to update replicated information using the Immediate Updating and/or Queued Updating options. These Updatable Subscription options are useful for occasional changes by Subscribers. If changes are frequent, use merge replication instead. Also, with the Updatable Subscription options, updates are part of a transaction. This means that the entire update either propagates or is rolled back if a conflict occurs. With merge replication, conflicts are resolved on a row-by-row basis.
If the Immediate Updating option is used, a two-phase commit (2PC) transaction is automatically initiated by the Subscriber with the Publisher whenever a Subscriber attempts to update replicated data. A 2PC transaction consists of a prepare phase and a commit phase under the control of the MS DTC service on the Subscriber, which serves as the transaction manager. During the prepare phase, the transaction manager coordinates with the SQL Server service on the Publisher and on the Subscriber, each acting as a resource manager, to ensure that the transaction can occur successfully in both databases. During the commit phase, if the transaction manager receives successful prepare notifications from each resource manager, the commit command is sent to each resource manager, and the transaction commits at the Publisher and the Subscriber. If a conflict exists on the Publisher (because of a conflicting update not yet replicated to the Subscriber), the transaction initiated by the Subscriber fails. The 2PC transaction ensures that no conflicts occur because the Publisher detects all conflicts before a transaction is committed.
If the Queued Updating option is used, changes made by a Subscriber are placed in a queue and periodically updated to the Publisher. Modifications can be made without an active network connection to the Publisher. The queued changes are applied at the Publisher when network connectivity is restored. Either the queue can be in a SQL Server database, or you can elect to use Microsoft Message Queuing if you are running Windows 2000. See "Queued Updating Components" in Books Online for more information on installing and using Microsoft Message Queuing. Because updates do not happen in real time, conflicts can occur if another Subscriber or the Publisher has changed the same data. Conflicts are resolved using a conflict resolution policy defined when the publication is created.
If you enable both options, Queued Updating functions as a failover in case Immediate Updating fails (such as due to a network failure). This is useful if the Publisher and updating Subscribers are normally connected, but you want to ensure that Subscribers can make updates in the event that network connectivity is lost.
Transactional Replication
With transactional replication, the Snapshot Agent copies an initial snapshot of data marked for replication and copies it from the Publisher to a snapshot folder on the Distributor. The Distribution Agent applies this initial snapshot to each Subscriber. The Log Reader Agent monitors changes to data marked for replication and captures each transaction log change into the distribution database on the Distributor. The Distribution Agent applies each change to each Subscriber in the original order of execution. If a stored procedure is used to update a large number of rows, the stored procedure can be replicated rather than each modified row. All three of these replication agents record history and error information to the distribution database. Figure 15.2 illustrates the transactional replication process.
The Distribution Agent can be scheduled to run continuously for minimum latency between the Publisher and Subscribers, or can be set to run on a specified schedule. Subscribers with a network connection to the Distributor can receive changes in near real time. After all Subscribers receive replicated transactions, the Distribution Clean Up Agent removes the transactions from the distribution database. If a Subscriber does not receive replicated transactions before the expiration of a specified retention period (72 hours by default), the replicated transaction is deleted and the subscription deactivated. This prevents the distribution database from becoming too large. A deactivated subscription can be reactivated and a new snapshot applied to bring the Subscriber current.
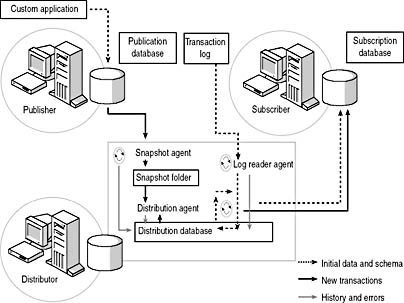
Figure 15.2
Transactional replication process.
Transactional replication can also be configured to support Updatable Subscriptions using the Immediate Updating and/or Queued Updating options discussed in the preceding section for snapshot replication.
Merge Replication
With merge replication, the Snapshot Agent copies an initial snapshot of data marked for replication from the Publisher to a snapshot folder on the Distributor. The Merge Agent applies this initial snapshot to each Subscriber. The Merge Agent also monitors and merges changes to replicated data occurring at the Publisher and at each Subscriber. If a merged change results in a conflict at the Publisher, the Merge Agent resolves the conflict using a resolution method specified by the administrator. You can choose among a variety of conflict resolvers or create a custom resolver. Both agents record history and error information to the distribution database (this is the only function of the distribution database with merge replication). Figure 15.3 illustrates the merge replication process.
The Merge Agent relies on a unique column existing for each row in a table that is being replicated in order to identify the row across multiple copies of the table on multiple servers and to track conflicts between rows. If a unique column does not exist, the Snapshot Agent adds one when the publication is created. The Snapshot Agent also creates triggers on the Publisher when the publication is created. These triggers monitor replicated rows and record changes in merge system tables. The Merge Agent creates identical triggers on each Subscriber when the initial snapshot is applied.
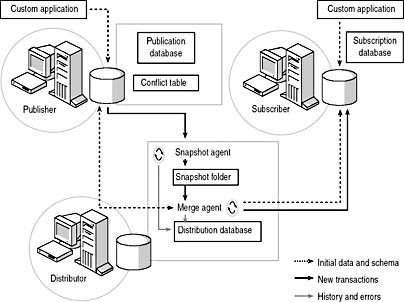
Figure 15.3
Merge replication process.
The Merge Agent can be scheduled to run continuously for minimum latency between the Publisher and Subscribers, or can be set to run on a specified schedule. Subscribers with a network connection to the Publisher can receive changes in near real time. If a Subscriber does not receive replicated transactions before the expiration of a specified retention period (14 days by default), the subscription is deactivated. A deactivated subscription can be reactivated and a new snapshot applied to bring the Subscriber current.
Selecting a Physical Replication Model
There are a number of physical replication models that you can implement with your replication solution. If you are using snapshot or transactional replication, you will frequently use a remote Distributor. This Distributor may provide replication services to multiple Publishers and multiple Subscribers. If the amount of data being replicated is small, the Distributor and the Publisher frequently reside on the same computer.
If you are replicating over a link with a limited bandwidth or an expensive communications link to multiple Subscribers, you can publish to a remote Subscriber that republishes to other Subscribers on its side of the link. This remote Subscriber is called a Republisher or a Publishing Subscriber.
With merge replication, a central Subscriber is frequently used to merge information from multiple regional Publishers to a central location. This model requires horizontal partitioning of data to avoid conflicts and generally uses a column to identify regional data. This central Subscriber model can also be used with snapshot and transactional replication. In addition, because merge replication makes limited use of the distribution database, the Publisher and the Distributor frequently reside on the same computer.
Choosing Replication Implementation Tools
SQL Server Enterprise Manager is the primary tool used to implement and monitor replication. A Replication container serves as a central location to organize and administer publications and subscriptions. Replication Monitor, which is a node within the Replication container, is used to view and manage replication agents. Replication Monitor also includes the ability to set alerts on replication events.
In addition, you can implement, monitor, and administer replication using a number of other methods.
- ActiveX controls—Used within custom applications written using Visual Basic or Visual C++. ActiveX controls enable you to control Snapshot Agent, Merge Agent, and Distribution Agent activity programmatically. For example, an application can have a Synchronize button that you can click to activate the Merge Agent to merge and synchronize data on demand.
- SQL-DMO—Used to create custom applications to configure, implement, or maintain a replication environment.
- Replication Distributor Interface—Provides the ability to replicate data from heterogeneous data sources (such as Access or Oracle).
- Stored procedures—Used primarily to script replication on multiple servers, based on a replication configuration initially configured using SQL Server Enterprise Manager.
- Windows Synchronization Manager—This utility is available with Windows 2000 in the Accessories program group and, with any computer using Internet Explorer 5.0, on the Tools menu. It is a centralized location for managing and synchronizing SQL Server publications and other applications (such as Web pages and e-mail).
- Active Directory Services—You can publish replication objects to Active Directory, permitting users to discover and subscribe to publications (if permitted).
Lesson Summary
You can use replication to distribute data to multiple locations and automatically keep the data synchronized between all replication locations. There are three basic types of replication used to implement a replication solution: snapshot, transactional, and merge. Replication is automated through the use of replication agents performing tasks according to specified schedules. SQL Server Enterprise Manager is the primary tool used to implement, monitor, and administer replication solutions. ActiveX controls are also frequently embedded into custom applications to manage replication.
EAN: N/A
Pages: 126