A Brief History of Computer Programming
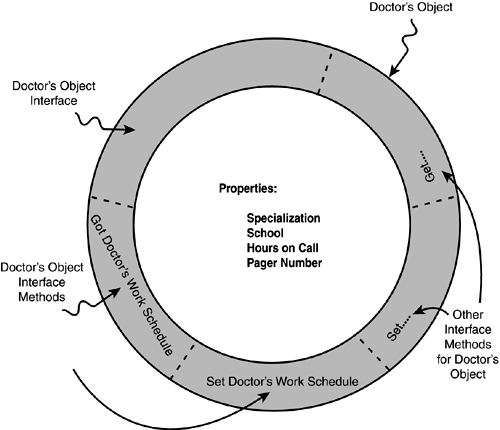
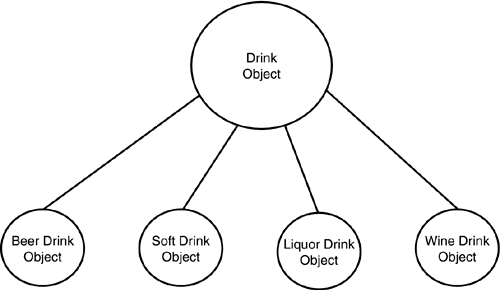
| Computer programming has a history that is less than a blink in time's eye. As recently as the 1960s, computers were actually programmed by plugging wires into jacks on boards that would then be plugged into slots in the computer. These boards determined the sequence of instructions that would operate on the data stored in the computer's memory. It's not surprising that the early programmers were often the same engineers who built the computers in the first place. A significant breakthrough came when John von Neumann suggested that the instructions the engineers were "wiring" into the computer might be stored in the computer's memory, just like the data. Eventually, the sequence of instructions, called stored programs, did become stored in the computer's memory ”and the art of computer programming was born. Programming LanguagesThere are a multitude of programming languages, but they all must ultimately be reduced to the native language of the computer. That language is called machine language. Therefore, we will begin our historical journey of programming languages with a peek at machine language programming. Machine LanguageThe first computer programs were written in machine language, a language that is specific to the particular computer being used. A machine language instruction is nothing more than a precise sequence of 1s and 0s that causes a specific action to take place in the computer. Because computers only understood these two states ”1s and 0s ”they were called binary computers. Even today's computers use the same 1s and 0s as those early computers. (Today's computers are called digital computers because the old tube-based analog circuits have been replaced with all digital circuitry .) Programming a computer consisted of flipping a set of toggle switches off (a binary 0) or on (a binary 1) to create a certain machine-language instruction. Each toggle switch represented a bit in the computer's memory. When the proper bit pattern for the instruction was represented by the toggle switches, pressing yet another button "deposited" the instruction in the computer's memory. By depositing enough instructions in exactly the correct order, a computer program was created and stored in the computer's memory. As you might imagine, there was a lot of switch-flipping going on for even the simplest of programs. Indeed, you could often identify programmers by the "binary blisters" they had on their index fingers from flipping the switches. (I used to build PCs from kits in the mid-1970s, and I did enough programming to develop "binary calluses" ”a clear sign of extensive programming experience back then.) The sequence of 1s and 0s can be viewed as a number in a variety of ways. Most people are accustomed to using a base-10 (or decimal ) numbering system, where numbers "roll over" on every tenth digit. In other words, you might start counting at 0 and count up to 9. Then you roll over a 1 to the left of the digit and start over at 0 again. This process forms the number 10 in a base-10 counting system. You then count up 10 more digits (0 through 9), which then gives you the numbers 10 through 19, and you roll over another digit and reset the first digit to 0. You then have 20. This numbering system has served humans well for more than 1,000 years . Computers, however, don't like a base-10 numbering system. Computers prefer a base-2 (or binary ) numbering system because it uses only two numbers: 0 and 1. As mentioned earlier, each bit in a computer's memory is either on (a 1) or off (a 0). (We won't get into too much detail about it here; you will learn the details of binary numbers in Chapter 4, "Data Types and Numeric Variables.") It's possible to view a sequence of such computer memory bits by using different numbering bases, depending on how you want to group the bits. In the early days of computers, most computer memory instructions were designed to use 8-or 16-bit instructions. As a result, most machine language instructions used a base-8 (or octal ) or a base-16 (or hexadecimal, often called simply hex ) numbering system. Octal-based systems grouped the binary bits into groups of 3 bits, and hex-based systems grouped them into groups of 4 bits. A group of 8 bits taken together is called a byte, and 4 bits is called a nibble. (I'm not making this stuff up.) Of the two predominant numbering systems, hex is used more often than octal in PCs. Using the hex numbering system, a computer instruction to jump to memory location 3,000 for a certain computer processor might be written like this: C3 68 06 The programmer has to remember that the computer instruction for jumping to a certain memory location is an operation code (or op code ) of C3, followed by a two-byte memory address. This is hardly a user -friendly programming language. As you will learn later, the number 3,000 in base-10 numbers becomes 668 in hexadecimal. The early PC chips stored numbers in the computer's memory with the least significant byte first, followed by the most significant byte. That's why 668 appears as 68 06 in our example. Again, some details are presented in Chapter 4. Assembly LanguageEventually, programmers got a little tired of machine language programming and looked for easier, and more productive, ways to program computers. One of the earliest attempts was to create a more easily recognized set of abbreviations for the machine language op codes. For example, the op code sequence C3 86 06 could be replaced with this: JUMP 3000 JUMP was a form of shorthand, or mnemonic, for C3 ”and it was a lot easier to remember. Other mnemonics were created for each op code in the computer's machine language instruction set. Collectively, the resulting set of mnemonics was called assembly language. An actual computer program would be a sequence of these assembly language mnemonics, arranged in such a way as to perform a specific task. Collectively, these mnemonic instructions for the program are called the source code of the program. Even though assembly language was a huge step in the right direction, it still had several shortcomings. First, even something as simple as adding a few numbers together might require dozens of assembly language instructions. Although it was better than machine language, assembly language was still tedious , at best. Second, assembly language was specific to the central processing unit (CPU) of a particular computer. Each CPU had its own unique set of machine language instructions and, hence, its own assembly language. Therefore, if you wrote a program in assembly language for the Motorola 6800 CPU, that same program would have to be rewritten if you wanted it to run on the Intel 8080 CPU. In a nutshell , assembly language is not portable from one computer system to another. Assembly language is still used today. Indeed, Chapter 4 shows how to look at a Visual Basic .NET program and see the assembly language that the Visual Basic .NET compiler creates for the program. Although you may never need to understand or use assembly language, it's comforting to know that Visual Basic .NET makes it available to you if ever you do need it. Virtual Machine Language and InterpretersIn the 1950s, computer programmers created virtual machine languages. The idea was to produce a unified set of mnemonics that were the same for all computers. Then, as a program was running, the computer would translate those virtual instructions into the actual machine code for a particular computer. For example, to process the instruction JUMP 3000 , the computer would compare the JUMP mnemonic with a table of instructions, called the instruction table, that was stored in another part of the computer's memory. That table would then say that the mnemonic JUMP should be interpreted as the machine language op code C3. The table would also say something like " JUMP must be followed by a memory address. Take the number that follows the JUMP instruction and form it into a two-byte memory address." Seeing this, the program would then read the number 3,000 and form it into a 2-byte memory address (that is, 86 06 in hex, stored with the low byte of the memory address first, followed by the high byte of the 2-byte memory second). The program then had a machine language instruction it could execute. The benefit of this approach is that if you changed the instruction table stored in the computer's memory, the JUMP 3000 instruction in the program could be coded for any CPU. For example, if you wrote a program to do a company's payroll in assembly language on an 8080 CPU, the instruction table for that CPU would be loaded into memory and you could run your program. If you took the same payroll program to a computer using a 6800 CPU and loaded in the instruction table for the 6800, you could run the program on a totally different CPU. This was the benefit of a virtual machine: You could run the same program on different types of computers! That was the good news. The bad news was that the program ran slower using this approach than using assembly language. As you might guess, reading a line of the program's virtual machine language source code, looking up what it should be translated to in machine language in the instruction table, and then executing those instructions took a lot of time. Such languages that must interpret what each instruction means in terms of machine code are called interpreted languages. The program that reads the program's source code and performs the interpretation is called an interpreter. It's important to note that the interpreter must be sitting someplace in memory before a program can be run. Also, the interpreter needs the source code for the program to be loaded into memory before it can begin its interpretation tasks . Because interpreted language programs were easier to write and understand than their machine code equivalents, programmer productivity increased dramatically. After all, the programmer no longer had to cope with an endless sequence of 1s and 0s. In their stead was a more easily remembered set of mnemonics that could be used to write programs. Another real plus was the fact that the programmer didn't have to learn a new machine language each time a new CPU was developed. The only significant downside was that the interpreted languages spent so much time looking up each instruction that they ran slowly ”perhaps as much as 30 times slower than a machine language program. This seemed like a true dilemma ”there were two choices, and both were bad. Compiled LanguagesOne day, a programmer (often said to be Grace Hopper) suggested that perhaps it would be possible to let the interpreter perform all its table lookup translations and then run the program after all the interpretations had been performed. This is the idea behind a compiler. A compiler translates the program's source code into machine code and then stores the resulting machine language program (often called binary code ) for later use. When you want to run the program, you just load in the already translated machine language program and run it at full speed. Using a compiler provides the ease-of-use of the interpreted languages but generates a program that can run at the speed of machine language. So which is better: a compiled language or an interpreted language? It depends. If you're typing in your name on the computer as part of a program, does it really matter that a compiled program can process your typing at the rate of 2 billion characters per second, but an interpreted program can only do it at a rate of 500 million characters per second? Both programs are going to be sitting there twiddling their thumbs, waiting for you to hit the next key. On the other hand, if the program is not waiting for user input and is just crunching the numbers or doing some other more complex processing, the compiled program is going to finish faster than the interpreted program. So how much faster is it? Several years ago a fashionable pastime was cracking the security encryption used on the Web. Someone was able to crack one such encrypted message in "just" two weeks on a huge supercomputer. My guess is that the program was compiled. If the program had been an interpreted one, the same result may have taken several months to accomplish. I am fairly confident that most of the users of the program would have favored the compiled version. This, however, is a pretty extreme example. Most programs process a program's data fairly quickly ”a time that is often measured in milliseconds or less. If the compiled version takes 35 milliseconds and the interpreter takes 125 milliseconds , is a human's perception of time granular enough to notice the difference? Often it is not. Also, as you will see in later chapters, interpreters have certain advantages that make writing programs for them easier than writing programs when using a compiler. Visual Basic .NET is an interpreted language. I say this because the output of the Visual Basic .NET compiler is not machine code. Instead, the Visual Basic .NET compiler produces an intermediate code called Microsoft Intermediate Language (MSIL) that ultimately becomes translated into machine language. (Again, these are fussy details that you need not worry about yet.) Therefore, programs written with Visual Basic .NET run a little slower than compiled versions of the same programs might run. Still, in the age of 3GHz processors, Visual Basic .NET is usually more than fast enough for the vast majority of applications. High-Level LanguagesDuring the 1950s and 1960s, there was a move away from assembly language toward high-level languages. The trend was to move the programming language away from the machine code the computer understood toward a more English-like language the programmer understood. Several languages emerged during the 1950s and gained a large following, including ALGOL, COBOL, FORTRAN, and LISP. These languages are still in use today. One benefit of such high-level languages is that because they are not written in machine code, program source code can be moved from one computer to another and run, even if the two computers have totally different machine code instructions. A compiler or an interpreter must simply be written for the CPU of each machine for the language of choice. The programmer is then freed from having to cope with the underlying machine architecture and can concentrate on solving the programming problem at hand. Sequential ProcessingWhile computers and their languages were improving over time, so were the programmers. The earliest programs were executed in a sequential fashion. That is, the computer started with the first line in the program's source code, executed it, proceeded to line 2, executed that line, proceeded to line 3, and so on, until there were no more program lines to execute. The execution sequence of the program's instructions, called the program flow, was from the start of the program to its end, with no detours in between. This sequential processing worked, but it wasn't necessarily the most efficient way to write a program (see Figure 2.1). Figure 2.1. Sequential processing in an early BASIC program. Programs that used sequential processing had certain drawbacks. For example, as the program was executing, the user might be asked to type some information into the program at 10 different points in the program. With sequential processing, the code necessary to collect the keystrokes from the user would appear at each of the 10 points in the program's source code. This process is shown in Figure 2.2. (Only three instances are shown in the figure, but the others would be similar, just having different program line numbers.) Figure 2.2 Duplicate code used in early programs.1 REM - Start Program ... 120 S = Kinput 121 IF S <> "" THEN 122 V = V + S 123 GOTO 120 124 END IF ... 270 S = Kinput 217 IF S <> "" THEN 272 V = V + S 273 GOTO 270 274 END IF ... 550 S = Kinput 551 IF S <> "" THEN 552 V = V + S 553 GOTO 550 554 END IF ... Notice that the code is essentially the same in each of the three instances in Figure 2.2. SubroutinesProgrammers quickly observed that certain processes in a program were repeated over and over (refer to Figure 2.2). They reasoned, "Why not write the code that accepts keystrokes from the keyboard and place it at a certain line number (for example, line 900) in the program and simply branch to that line number whenever the program needs some data to be entered by the user? Just so we don't get lost in the process, we'll remember the line number where we make the branch (for example, line 125) and resume executing at the next line (for example, line 126) when the user has finished typing the new information into the program." Thus was born the concept of the subroutine. A subroutine is simply a small piece of program code that is designed to perform a specific task more than once. The phrase calling a subroutine is simply a programmer's way of saying that the program flow is temporarily redirected to the subroutine. Using a subroutine in a program is depicted in Figure 2.3. Note how the subroutine is called each time the user is expected to enter some data from the keyboard, and then program control returns to the line following the one where the subroutine was called. It's also clear from Figure 2.3 that at this stage, programs were no longer forced to use sequential processing. Programs could now branch to whatever subroutine was needed, have the subroutine complete its task, and resume program execution back where it left off before the branch to the subroutine. Figure 2.3 Using a subroutine to avoid code duplication.1 REM - Start Program ... 120 GOSUB 900 ... 270 GOSUB 900 ... 550 GOSUB 900 ... 900 S = Kinput 901 IF S <> "" THEN 902 V = V + S 903 GOTO 550 904 END IF 905 RETURN ... With a subroutine, the GOSUB keyword caused the program to jump to the subroutine at the stated line number (for example, 900 in Figure 2.3). The code in the subroutine was then executed. The RETURN statement in the subroutine caused the program to branch back to the line number following the subroutine call (for example, 121 in Figure 2.3). Think about what this simple idea means. Suppose a subroutine consists of 30 lines of code. A sequential program, with its 10 requests for user input, would have 300 lines of (mostly) duplicate code, whereas a program that used a subroutine would have only 30 lines of code to perform the same 10 tasks. This creates two significant advantages: the program requires less memory than it does with sequential processing and the programmer has 270 fewer lines of code to write, test, correct, and maintain. Memory savings was very important during the early stages of computing, and it was not uncommon for even large mainframe computers to run everything in as little as 32KB (that is, 32,000 bytes) of memory. (32KB of memory is actually 32,768 bytes of memory. Programmers love to simplify things!) Today, it's not uncommon for a PC to have 256MB or more of memory. (256MB of memory is actually 268,435,456 million bytes of memory!) Clearly, memory restrictions are a lot less imposing today than they were 40 years ago, although memory and other resource use should always be a concern to programmers. However, when it comes to the actual cost of writing and running a computer program, it is the cost of writing, testing, correcting, and maintaining the program that is highest. Memory is cheap; programmers are not. The advent of subroutines also significantly simplified the process of writing, testing, and debugging a program. It looked like subroutines were going to save the day by lowering the costs of writing new programs significantly. But, as you'll learn in the next section, that didn't happen. Structured ProgrammingAll the jumping around to process subroutines led to the creation of programs that lacked logical structure. Programs were getting larger and more complex, as were computers. With that growth came even higher expectations from the computer user of what the next generation of computers would do. As the hardware technology experienced explosive growth during the 1960s and 1970s, the programmers' bag of tricks just didn't seem to keep pace. Programmers knew that without some kind of structure and discipline in their programs, things were going to get worse before they got better. And, over time, that's exactly what happened . Program development costs continued to spiral, even though the actual computational costs were starting to decline. A lot of very bright people began work on developing a formal methodology for writing computer programs. One of these pioneers was Nicklaus Wirth, who was a strong proponent of a new way to write programs using structured programming techniques. The Pascal programming language was Wirth's brainchild; Wirth developed it with structured programming in mind from its inception. The structured programming methodology did result in programs that had more structure and, because of that structure, the programs were easier to test, debug, and maintain than earlier programs. Structured programming techniques ushered in other innovations, too, as described in the next section. FunctionsOne major contribution to structured programming was the concept of functions. A program function is much like a subroutine, except you can pass data to the function, have the function operate on that data, and then have the function return a data value when it is done processing the data. Although we're not fully ready to discuss the implications of this yet, functions in structured programming were an early attempt at data hiding. By hiding certain pieces of data from other parts of the program, data was less likely to become contaminated as the program executed. Another major player in the language arena was C. Developed in the early 1970s by Dennis Ritchie and Ken Thompson, the language grew from modest beginnings to become the most dominant language of the 1980s and early 1990s. C suited the philosophy of structured programming nicely . Its capability to use functions provided a way to divide a program problem into small, often reusable, parts. It also provided improved ways to hide the program's data from other effects in the program as it executed. C was a nice, powerful language. Alas, software costs continued to rise, despite falling hardware prices. Clearly, there had to be a better way to write programs. OOPOOP represents a unique way of thinking about the entire programming process. Although OOP may appear to be a relatively new programming process, its basic concepts can be traced back to early simulation problems of the 1960s. One particular simulation involved trying to simulate people arriving at a hospital elevator and waiting to get on. Programmers were frustrated because each time they wanted to simulate another person arriving at the elevator, they had to write new code to simulate that new person's arrival at the elevator doors. They realized that the simulation would be relatively simple if they could just tell the new arrival, "Create yourself and quit bothering me!" Lightning struck, thunder boomed, and programmers had an epiphany. Up until that time, every programming problem had been viewed from two separate perspectives: the data necessary to represent the problem and the code necessary to operate on that data to yield a solution to the problem. In that system, computer programs were reduced to defining the data and writing the subroutines and functions to manipulate the data in such a way that the solution to the problem became known. An OOP methodology works differently. OOP combines the data and the code that manipulates that data into a single concept called an object. Let's return to the hospital elevator simulation mentioned earlier. Say there's a Doctor object, a Nurse object, a Patient object, and a Visitor object. Buried inside each of these objects is a piece of code that can react to the message "Draw yourself." The Doctor object might draw itself with a stethoscope around its neck. The Nurse object might be very similar but exclude the stethoscope and instead carry a clipboard. Likewise, the Patient object would forego the clipboard and stethoscope and have a head bandage and wear one of those fetching gowns we all hate. The Visitor object might draw itself in a jacket, carrying a bouquet of flowers. What's really interesting here is that a single message to each object ” DrawYourself ”produces similar, yet distinct, behavior from each object. That is, sending a DrawYourself message to the Doctor object produces a result that is visibly different from the same message sent to a Visitor object. How is this possible? Although the answer is not simple, it can be explained in terms of three basic OOP concepts: encapsulation, inheritance, and polymorphism. EncapsulationEncapsulation means that the data for an object and the instructions that operate on that data are part of the object itself. Figure 2.4 shows how you might view a Doctor object as a series of three layers in the shape of a ball. Collectively, the outer layer is the shell that is labeled the Doctor object. Figure 2.4. The Doctor object. The Properties of an ObjectIn the center layer, or core , of the Doctor object is the data that describes the object. The exact nature of this data depends on how you describe the object. For the Doctor object, the data might include the doctor's area of specialization (for example, cardiology, urology ), where the doctor went to school, days or hours on call (that is, the work schedule), plus any other information you might think necessary to describe an object called Doctor and make that object useful. Often you hear the data of an object referred to as the properties, or attributes, of the object. The properties of an object are the data that describes not only the object itself but its state as well. Properties help answer the "so-tell-me-about-yourself" kinds of questions. For example, you might have a Person object, and one data item might be named Occupation . If you are a student and the object is being used to describe you, I can examine that property and learn something about you. Using the Doctor object discussed earlier, you might have a property named OnCall that has a value of 1 when a certain doctor is on call and when the doctor is not on call. In this case, you can examine the state of the doctor: Is the doctor on call or not? These are the types of questions that the properties of an object often address. Clearly, the properties of any object can change, and objects of the same type can assume different values. For example, one Doctor object may have a specialization in cardiology, but a different Doctor object might specialize in pediatrics. One Doctor object might be on call on Saturdays, and another might be on call on Mondays. Although each Doctor object may have the same list of properties, the value of each of those properties can vary from one Doctor object to the next. Therefore, the values that the properties assume for the object define the state of the object. This also means that by inspecting the properties of an object, you can distinguish among individual objects even though they may all be the same type of object (for example, Doctor ). The Interface of an ObjectNote in Figure 2.4 that the properties of the Doctor object are at the core of the object: They are not directly exposed to the outside world. This type of hiding is done by design in the OOP world. As much as possible, the OOP methodology wants to hide the data of an object (that is, its properties) from the outside world. The only way to access the data of an object, therefore, is through a set of methods that clearly define how people can access the properties of the object. In Figure 2.4, the methods for accessing the object's properties form the second layer of the object. It is this second layer that dictates how the outside world interacts with the properties of the object. Because this second layer describes and defines how the outside world communicates with the object, the second layer defines the interface for the object. The object's interface is defined by the methods by which all communication is done with the object's data. In other words, you use the methods of the object to examine the properties of the object. Therefore, the interface gives you access to the state of the object. Note that methods are not simply limited to fetching and changing property values. Methods often address the "so-what-do-you-do?" types of questions. A Doctor object might have a PerformHeartSurgery method. A Nurse object might have a GiveInjection or ThisMightStingABit method. Methods, therefore, may imply some form of action on the part of the object. For example, one method might be called GetDoctorsWorkSchedule . If your program needs to know the work schedule for a given Doctor object, you request the GetDoctorsWorkSchedule method to get that information for you. The code associated with the GetDoctorsWorkSchedule method then looks up the Doctor object's work schedule as it is stored in the object's list of properties. Similarly, there will likely be another method called SetDoctorsWorkSchedule that enables you to change the work schedule for each Doctor object. Indeed, it's common to find these Set and Get methods in pairs for many of the attributes of an object. The purpose of a Set method is to change the object's property, and the Get method is used to read the current value of the property. It should also be clear that the object's Set methods are used to change the state of the object. Methods usually affect one or more property values, but they are not required to do so. You, the programmer, must make these decisions. All this might seem a bit overwhelming at the moment, but it actually gets easier as you dig deeper into the art of OOP programming. You'll see. It is important to note that the outside world is forced to use an object's interface in order to know anything about the state of the object. That is, the programmer must use the methods found in the second layer of the object to gain access to the properties found at the core of the object. This is the whole idea behind encapsulation: Keep the data and everything that can affect that data in one place ”as part of the object itself. InheritanceThe idea behind inheritance is that after you've defined an object, you can extend the object to create new objects. For example, you might create an object called Drink . For now we'll assume that the only property for an object called Drink is the size of the glass that holds the fluid (as measured in ounces). Conceptually, you can then create a new object called WaterDrink that is extended from Drink but has a new property called Water . You might create yet another Drink object, called BeerDrink , with a property called BeerType . And you might create another object derived from Beer called Ale , which has a slightly different set of attributes than does Beer . Other possible objects that might be created from the basic Drink object are SoftDrink , LiquorDrink , FruitDrink , AdeDrink , WineDrink , and so on. This hierarchy is shown in Figure 2.5. Figure 2.5. The Drink object hierarchy. By adding new properties and methods to a previously defined object, it is possible to create new (and slightly different) objects. Because these new objects inherit attributes and methods from existing objects, your job, as a programmer, is simplified because you can build on objects that already exist and reuse the code from the existing object. We will return to this concept of inheritance many times in the course of our study of Visual Basic .NET. PolymorphismThe third ingredient in the OOP mix is polymorphism. The word polymorphism comes from the Greek for "many shapes ," but it takes on a slightly different meaning when applied to OOP. What it means in the context of OOP is that you can send a single message to a group of different objects, and each object knows how to process the message in its own distinct way. Using the hospital elevator example, you could send a DrawYourself message to each object, and the Doctor object would draw itself with a stethoscope, the Nurse object would draw itself with a clipboard, and so on. You don't have to tell the object how to draw itself; it already knows how because each object has a method that responds to the DrawYourself message in its own unique way. As a result, the same message sent to different objects produces slightly different results in that the shapes are drawn differently. A single message produces many shapes; hence, this is polymorphism. Using the hospital example again, you could send a DoSomething message to the interface of each of the objects. As a result of receiving this message, the Doctor object would perform an operation, the Nurse object would give the Patient object an injection, the Patient object would say "Ouch" and complain, and the Visitor object would say, "I bet that hurt." Again, the important thing to notice is that the same message sent to different objects causes different behavior to occur for those objects. For a language to be considered an OOP language, it must support encapsulation, inheritance, and polymorphism. Some languages come close but do not support all three elements of OOP. Up through release 6.0, Visual Basic had encapsulation and polymorphism, but it lacked inheritance capabilities. Visual Basic .NET removes this shortcoming, and it is a full-featured and robust OOP language. Other languages, such as C++, have all the elements but don't require you to use OOP techniques. Visual Basic .NET, on the other hand, has all three elements of OOP and forces you to use OOP techniques. This is why you need to have a basic understanding of OOP fundamentals early in this book. |

EAN: 2147483647
Pages: 238