The Motivations for Clustered Infrastructure Solutions: Scalability and High Availability
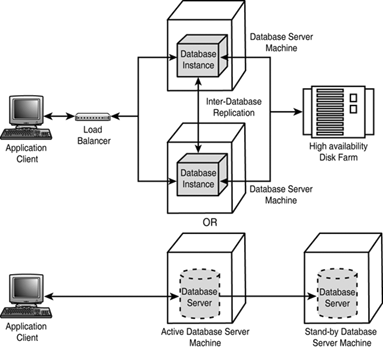
| Scalability and high availability (fault resilience) are two key infrastructure adaptability requirements that organizations must reflect in the architectural (system) design of their mission-critical e-business solutions. As illustrated in Figure 25.1, during the client/server era, scalability and high-availability solutions were primarily implemented in the Database or Server tiers, where Figure 25.1. Scalability and high availability within a client/server architecture.
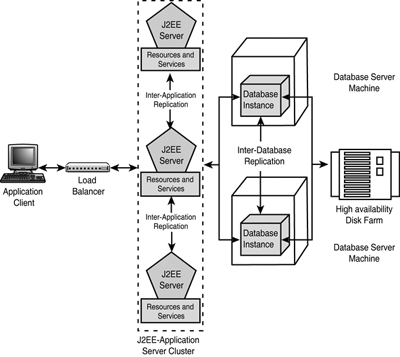
To implement an agile and robust J2EE e-business solution, scalability and high availability solutions for the Database tier still remain applicable as they did for the client/server system, but now they address the Enterprise Information System (EIS) tier. However, as illustrated in Figure 25.2, scalability and high availability must now also be addressed at the distributed middle tiers of the J2EE Application Programming Model ”the Presentation (Web servers) and Application (Application servers) tiers ”which brings a whole new dimension of challenges. These challenges are as follows : Figure 25.2. Scalability and high-availability requirements within the J2EE Application Programming Model.
Scalability and high availability within a J2EE architecture are achieved through the implementation of client-request load-balancing techniques in combination with the clustering capabilities of the J2EE application server that constitutes the middle tier, such as the BEA WebLogic Server cluster. A cluster cannot possess scalability or high availability without the support of an intelligent and robust load-balancing service. A cluster in a J2EE architecture is generally defined as a group of two or more J2EE-compliant Web or application servers that closely cooperate with each other through transparent object replication mechanisms to ensure each server in the group presents the same content. Each server (node) in the cluster is identical in configuration and networked to act as a single virtual server . Client requests directed to this virtual server can be handled independently by any J2EE server in the cluster, which gives the impression of single entity representation of the hosted J2EE application in the cluster. The following sections introduce the three highly interrelated core services ”scalability, high availability, and load balancing ”that any J2EE server clustering solution must provide. How these services are implemented within WebLogic Server will be discussed later in this chapter. ScalabilityScalability refers to the capability to expand the capacity of an application hosted on the middle tier without interruption or degradation of the Quality of Service ( QoS ) to an increasing number of users. As a rule, an application server must always be available to service requests from a client. As you may have discovered through experience, however, if a single server becomes over-subscribed, a connecting client can experience a Denial of Service ( DoS ) or performance degradation. This could be caused by a computer's network interface, which has a built-in limit to the amount of information the server can distribute regardless of the processor's capability of higher throughput, or because the J2EE server is too busy servicing existing processing requests. As client requests continue to increase, the J2EE server environment must be scaled accordingly . There are two approaches to scaling:
By applying conventional wisdom, the most logical method for achieving scalability is though the implementation of a clustering solution. High AvailabilityHigh availability refers to the capability to ensure applications hosted in the middle tier remain consistently accessible and operational to their clients . High availability is achieved through the redundancy of multiple Web and application servers within the cluster and is implemented by the cluster's "failover" mechanisms. If an application component (an object) fails processing its task, the cluster's failover mechanism reroutes the task and any supporting information to a copy of the object on another server to continue the task. If you want to enable failover:
In the event of a failure to one of the J2EE servers in a cluster, the load-balancing service, in conjunction with the failover mechanism, should seamlessly reroute requests to other servers, thus preventing any interruption to the middle-tier service. Additional Factors Affecting High AvailabilityIn addition to application server clustering, which provides high availability in the middle tier of an application architecture, organizations must accept that people, processes, and the technology infrastructure are all interdependent facets of any high-availability solution. People and process issues comprise at least 80% of the solution, with the technology infrastructure assuming the remainder. From a people and process perspective, the objective is to balance the potential business cost of incurring system unavailability with the cost of insuring against planned and unplanned system downtime. Planned downtime encompasses activities in which an administrator is aware beforehand that a resource will be unavailable and plans accordingly ”for example, performing backup operations, making configuration changes, adding processing capacity, distributing software, and managing version control. Unplanned downtime, also known as outages or failures , includes a multitude of "What happens if" scenarios, such as
In practice, organizations should initially focus on developing mature, planned downtime procedures before even considering unplanned downtime. This is supported through extensive studies conducted by research firms, which concluded that 70 “90% of downtime may be directly associated with planned downtime activities. However, the organizational reality indicates that more time and effort are applied to preventing unplanned downtime. From a technology infrastructure perspective, for a system to be truly highly available, redundancy must exist throughout the system. For example, a system must have the following:
As stated earlier, the extent of redundancy should be directly related to the business cost of system unavailability versus the realized cost of insuring against system downtime. Load BalancingFor a server cluster to achieve its high-availability, high-scalability, and high-performance potential, load balancing is required. Load balancing refers to the capability to optimally partition inbound client processing requests across all the J2EE servers that constitute a cluster based on factors such as capacity, availability, response time, current load, historical performance, and also administrative weights (priority) placed on the clustered servers. A load balancer, which can be software or hardware based, sits between the Internet and the physical server cluster, also acting as a virtual server. As each client request arrives, the load balancer makes near-instantaneous intelligent decisions about the J2EE server best able to satisfy each incoming request. Software-based load balancers can come in the form of computers, routers, or switches with integrated load-balancing software or load-balancing capabilities. Hardware load balancers are separate pieces of equipment that provide advanced load-balancing features and additional reliability features such as automatic failover to a redundant unit. |
EAN: 2147483647
Pages: 360